
【笔记】零(被)碎(拷)问(打)题记录
网络
掩码考点
- 同一局域网下的192.168.50.128/25和192.168.50.127/25能否ping通(无路由器无交换机的情况)
- 那同一局域网下的192.168.50.127/25和192.168.50.126/25能否ping通
子网掩码(Subnet Mask)是计算机网络中非常核心的概念。简单来说,它的作用就是在 IP 地址中“划线”,区分哪一部分代表“街道”(网络号),哪一部分代表“门牌号”(主机号)。
以下是关于子网掩码的核心知识点:
- 核心作用:身份识别
一个 IP 地址(如192.168.1.5)本身无法告诉电脑它属于哪个网络。子网掩码的作用就是:
- 确定网络地址: 告诉设备哪些位是网络标识。
- 确定主机地址: 告诉设备哪些位是个体设备标识。
- 判断是否在同一网段: 电脑通过子网掩码计算出目标 IP 是否和自己在同一个“群聊”里。如果是,直接发消息;如果不是,就发给路由器(网关)。
2. 形态与结构
子网掩码和 IP 地址一样,也是 32 位二进制数,通常用“点分十进制”表示。它的规则非常简单粗暴:
- 连续的 1: 对应的 IP 位是网络号。
- 连续的 0: 对应的 IP 位是主机号。
常见对应关系:
| 掩码(十进制) | 掩码(二进制) | 含义 |
|---|---|---|
| 255.0.0.0 | 11111111.0... |
前 8 位是网络,后 24 位是主机 |
| 255.255.255.0 | 11111111.11111111.11111111.00000000 |
前 24 位是网络,后 8 位是主机 |
3. 为什么会有 /24 这种写法?(CIDR)
你可能经常看到 192.168.1.1/24。这叫 CIDR(无类别域间路由) 记法。
- /24 就代表子网掩码的前 24 位全是
1。 - 也就是
255.255.255.0。 - 如果是 /16,就是
255.255.0.0。
4. 子网掩码是如何工作的?(AND 运算)
计算机通过二进制的 “与”(AND)运算 来计算网络地址。
- 规则: 1 & 1 = 1; 1 & 0 = 0; 0 & 0 = 0。
例子:
IP 地址:192.168.1.10
掩码:255.255.255.0
两者进行 AND 运算后,结果为 192.168.1.0。这就是该设备所在的网络地址。
5. 如何计算子网下的主机数量?
在一个子网中,有多少个 IP 可以分配给电脑使用?
- 是子网掩码中 0 的个数。
- 为什么要减 2?
- 主机号全为
0的地址是网络地址(代表整个网段)。 - 主机号全为
1的地址是广播地址(发给该网段所有人的消息)。
linux运维
考考你假设你现在面对一个被黑的 WordPress 站点,/var/www 下有 8 万个 PHP 文件,需要快速找出含 eval( 的可疑文件。
你更倾向哪种做法? 单选
find … | xargs grep
find … -exec grep {} ;
find … -exec grep {} +
find -print0 | xargs -0 -P 4 grep
find ... -exec grep {} \;
命令含义:找到一个文件,就暂停
find,启动一个grep进程查这个文件,查完关掉,再找下一个。
- 机制:1 对 1。每找到 1 个文件,执行 1 次
grep命令。 - 致命伤:进程开销极大。
- 对于 8 万个文件,系统需要执行 80,000 次
fork()(创建进程)和exec()(执行命令)。 - 这就像你要送 8 万封信,这个做法是:拿一封信,开一次车去邮局,回来;再拿一封信,再开一次车去邮局。
- 结果:慢到让你怀疑人生,可能需要跑十几分钟。
- 对于 8 万个文件,系统需要执行 80,000 次
find ... | xargs grep
命令含义:
find把找到的文件名一股脑丢给管道,xargs负责把这些文件名拼成一行,一次性传给grep。
- 机制:多 对 1。默认情况下
xargs会尽可能多地填满命令行长度,比如一次传 1000 个文件给grep。 - 优点:快!只启动几十次
grep进程。 - 致命伤:安全漏洞(Separator 问题)。
- 默认的
xargs以空格或换行作为分隔符。 - 如果有一个文件名叫
my photo.php(中间有空格)。 find输出了my photo.php。xargs会以为这是两个文件:my和photo.php。grep就会报错说找不到文件my,从而漏掉了对这个文件的检查。黑客常利用这一点隐藏后门。
- 默认的
find ... -exec grep {} +
命令含义:这是 POSIX 标准推荐的高效写法。
find会自己把文件名攒起来,攒够了一波,再调用一次grep。
- 机制:多 对 1(内置优化)。逻辑和
xargs类似,但由find内部处理。 - 优点:
- 安全:它能正确处理包含空格等怪异字符的文件名。
- 较快:减少了进程启动次数。
- 缺点:它是单线程的。它只能利用一个 CPU 核心挨个处理这 8 万个文件。如果你的服务器是 8 核甚至 16 核的,另外 7 个核都在围观,极其浪费。
find -print0 | xargs -0 -P 4 grep
命令含义:安全处理文件名,并且开启 4 个线程并行处理。
-
find -print0:- 告诉
find:在输出每一个文件名后,不要加换行符,而是加一个 NULL 字符(ASCII 0)。 - 为什么? 因为在 Linux 文件系统中,文件名可以包含几乎任何字符(空格、换行、逗号等),唯独不能包含 NULL 字符。这是唯一绝对安全的分隔符。
- 告诉
-
xargs -0:- 告诉
xargs:不管你读到什么(空格、引号、反斜杠),都只当做普通字符,直到读到一个 NULL 字符 才认为是一个文件名的结束。 - 这与前面的
-print0是绝配,完美解决了“白银段位”中的安全问题。
- 告诉
-
-P 4(关键性能点):- Parallel(并行)。
- 告诉
xargs:不要等上一个grep跑完了再跑下一个。请同时启动 4 个grep进程并行工作! - 如果你的服务器是 4 核 CPU,理论速度可以提升接近 4 倍。对于 IO 密集型或 CPU 密集型任务(grep 大文件是 CPU 密集型),这是质的飞跃。
根据题意(快速、安全、并发、针对 PHP 文件),完整的最佳实践命令如下:
find /var/www -type f -name "*.php" -print0 | xargs -0 -P 4 grep -l "eval(" |
find /var/www- 指定查找的根目录。
-type f- 只查找“文件”,排除目录(提高效率,避免 grep 报错说“Is a directory”)。
-name "*.php"- 关键过滤:题目明确说是“8 万个 PHP 文件”,加上这个参数能避免去 grep 图片、日志或静态资源,大幅减少无用功。
-print0- 安全核心:输出文件名时以
null字符结尾。这是为了应对“被黑”场景下可能存在的恶意文件名(如包含空格、换行符的文件),防止命令执行出错或被绕过。
- 安全核心:输出文件名时以
|- 管道符,传递数据。
xargs -0- 安全核心:告诉 xargs 以
null字符作为分隔符来读取文件名,与前面的-print0完美配合。
- 安全核心:告诉 xargs 以
-P 4- 速度核心:启用 4 个进程并行执行 grep。如果是 8 核服务器,可以改为
-P 8,速度直接起飞。
- 速度核心:启用 4 个进程并行执行 grep。如果是 8 核服务器,可以改为
grep -l "eval(""eval(": 查找包含eval(的字符串。-l(小写 L):只输出包含匹配内容的文件名。- 如果不加
-l,grep 会把匹配到的那一行代码打印出来。 - 题目要求是“找出…文件”,通常我们需要的是一份文件清单(list),方便后续进行隔离或删除,所以
-l最合适。
- 如果不加
find /var/www -type f -name "*.php" -print0 | xargs -0 -P 4 grep -Hn --color "eval(" |
-H: 强制显示文件名。-n: 显示行号。--color: 高亮匹配到的eval(,方便肉眼识别。
学校网站上题
[REDACTED]
兔兔说她对一份机密文件进行了“完美的”脱敏处理。还好你在发送之前检查了一下。
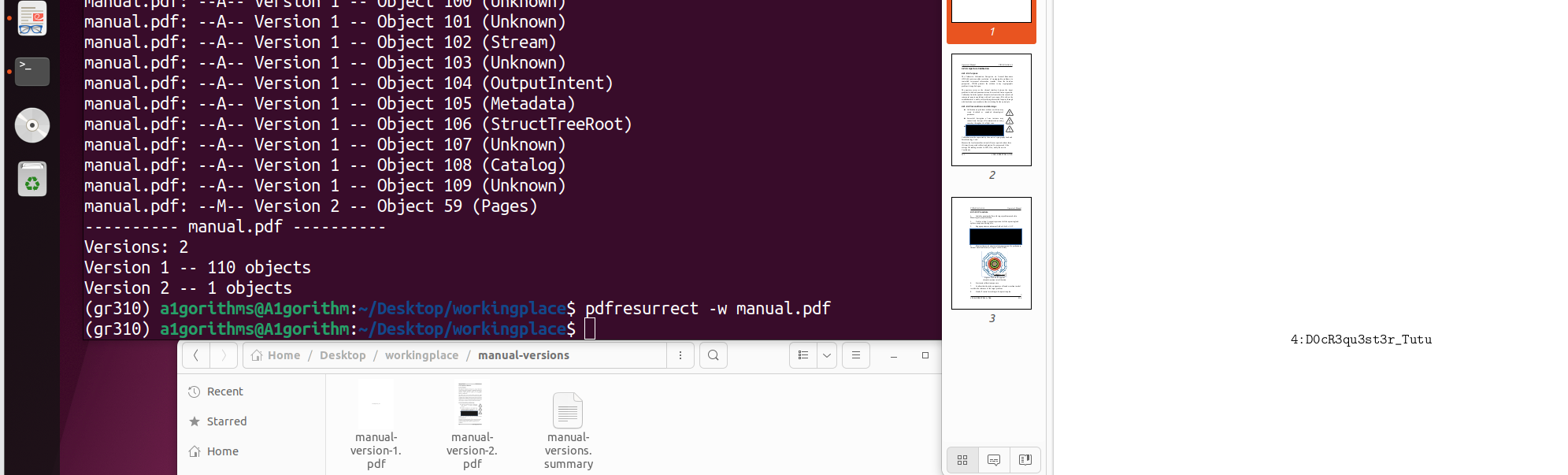
提交说明: 附件中包含四段敏感字符串,格式为 [1-4]:.+。用下划线字符 _ 连接去掉序号的四段字符串,包裹 hgame{} 后提交。例如,若四段敏感字符串分别为 1:Example、2:Redacted、3:Secret、4:Strings_!,则提交的 flag 为 hgame{Example_Redacted_Secret_Strings_!}。
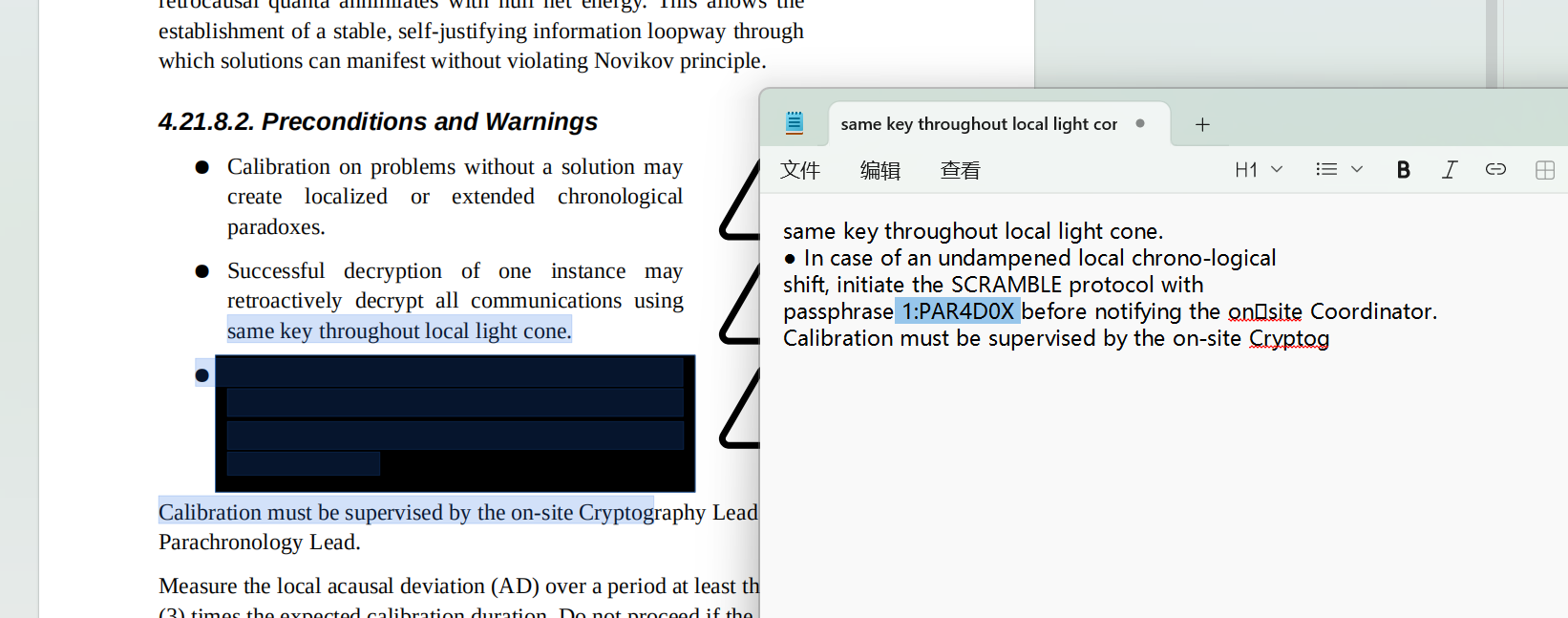
1:PAR4D0X
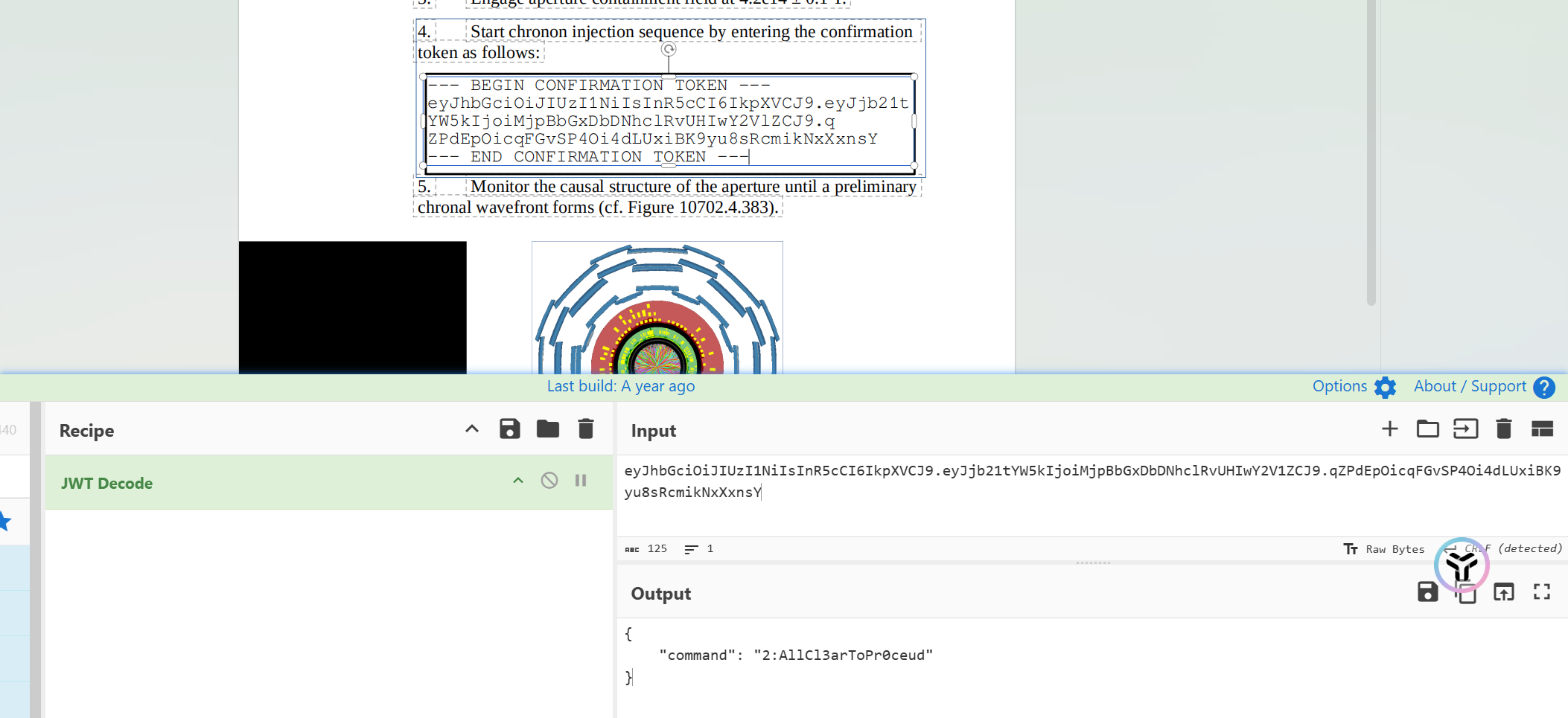
2:AllCl3arToPr0ceud
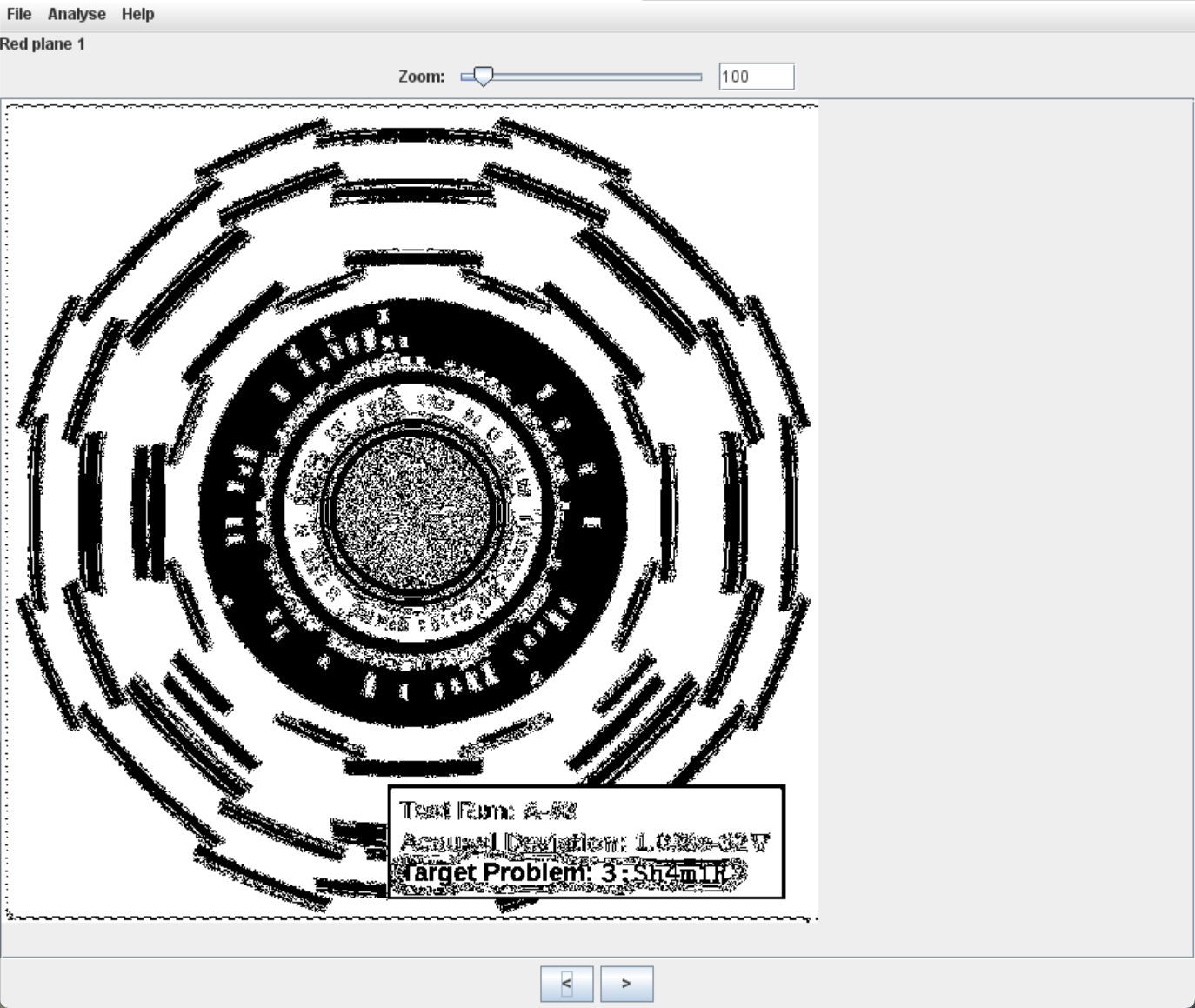
Sh4m1R
- pdf 版本查看:https://github.com/enferex/pdfresurrect

4:D0cR3qu3st3r_Tutu
hgame{PAR4D0X_AllCl3arToPr0ceed_Sh4m1R_D0cR3qu3st3r_Tutu}
basics
基础,答案用utflag{}包裹
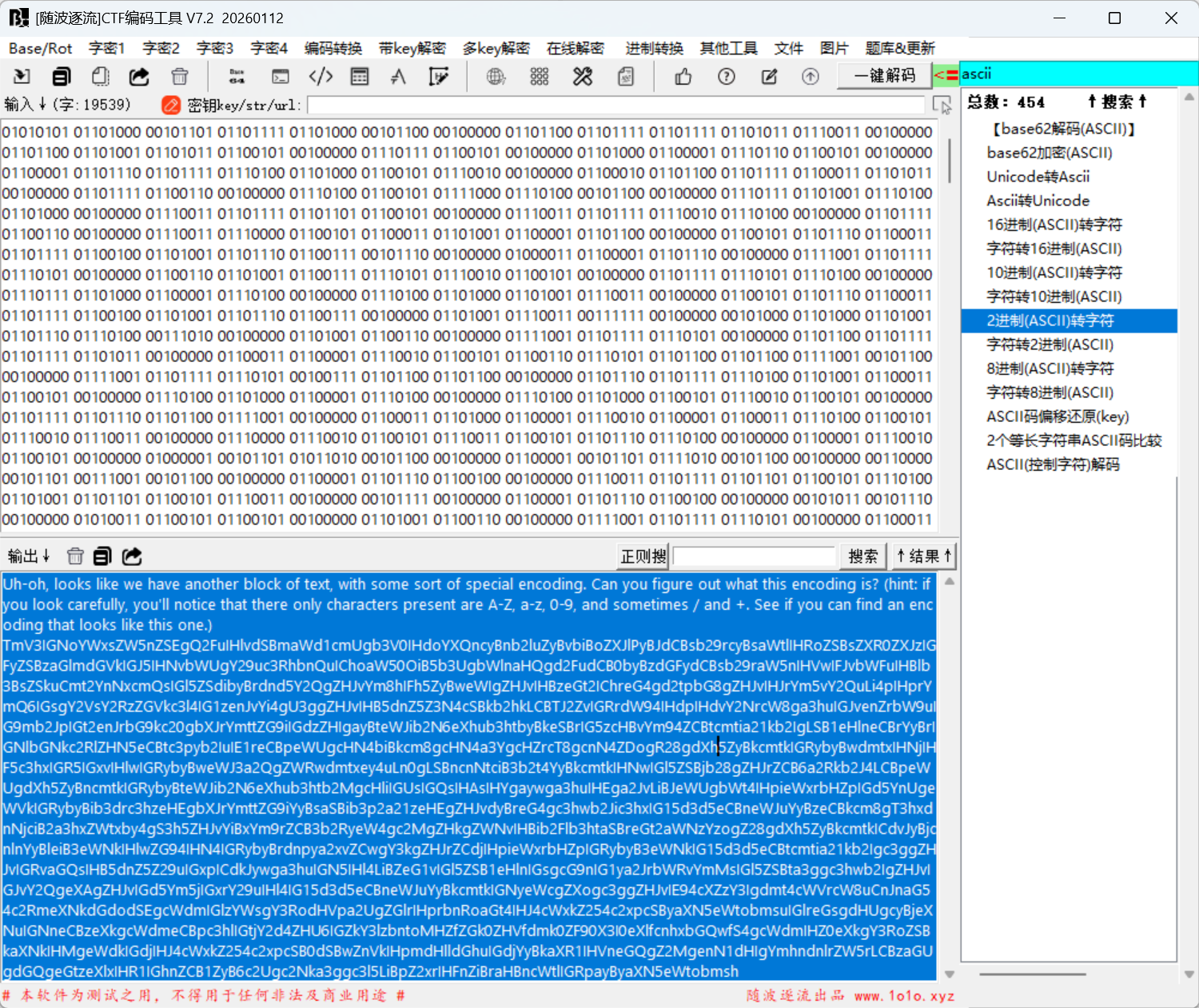
Uh-oh, looks like we have another block of text, with some sort of special encoding. Can you figure out what this encoding is? (hint: if you look carefully, you'll notice that there only characters present are A-Z, a-z, 0-9, and sometimes / and +. See if you can find an encoding that looks like this one.) |
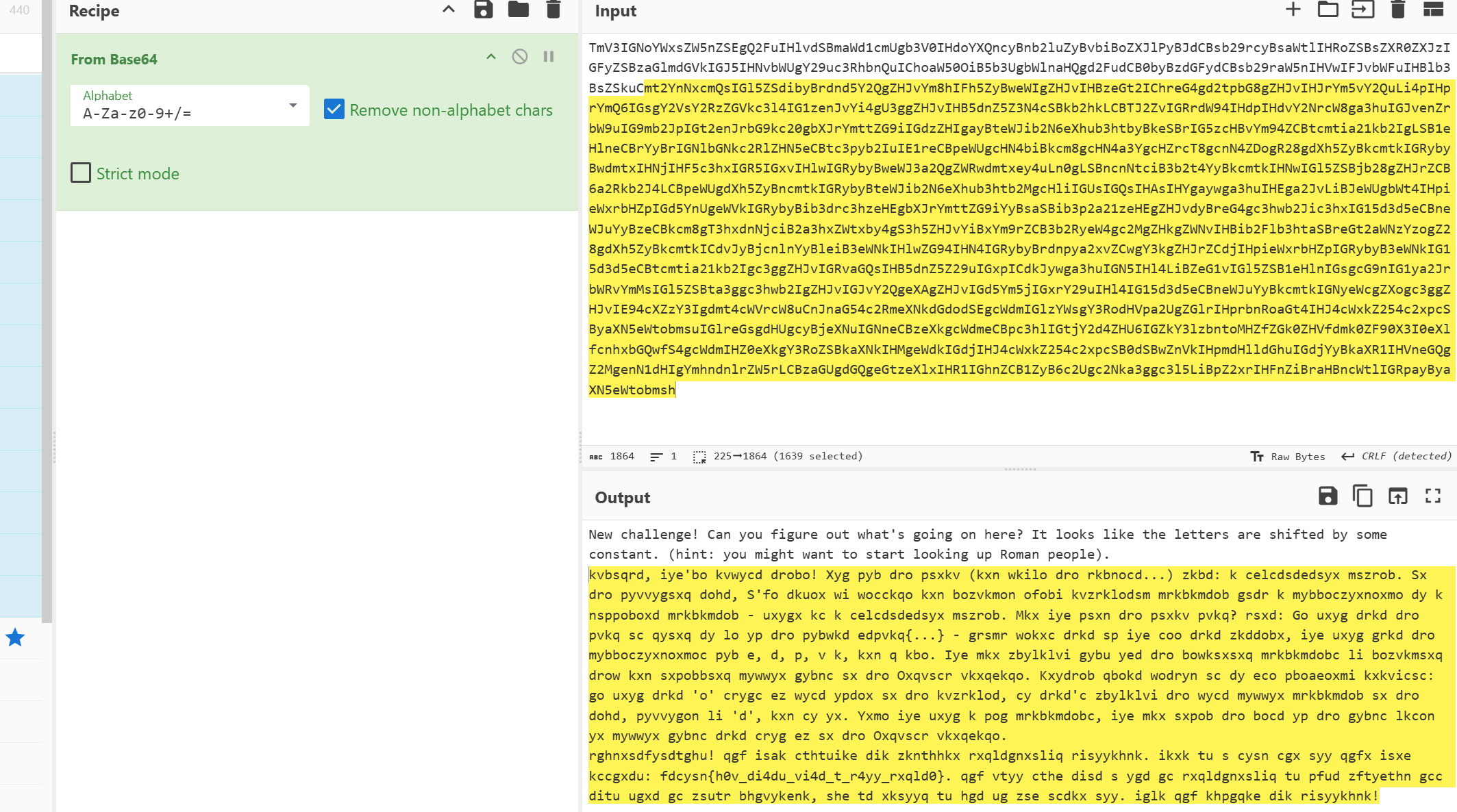
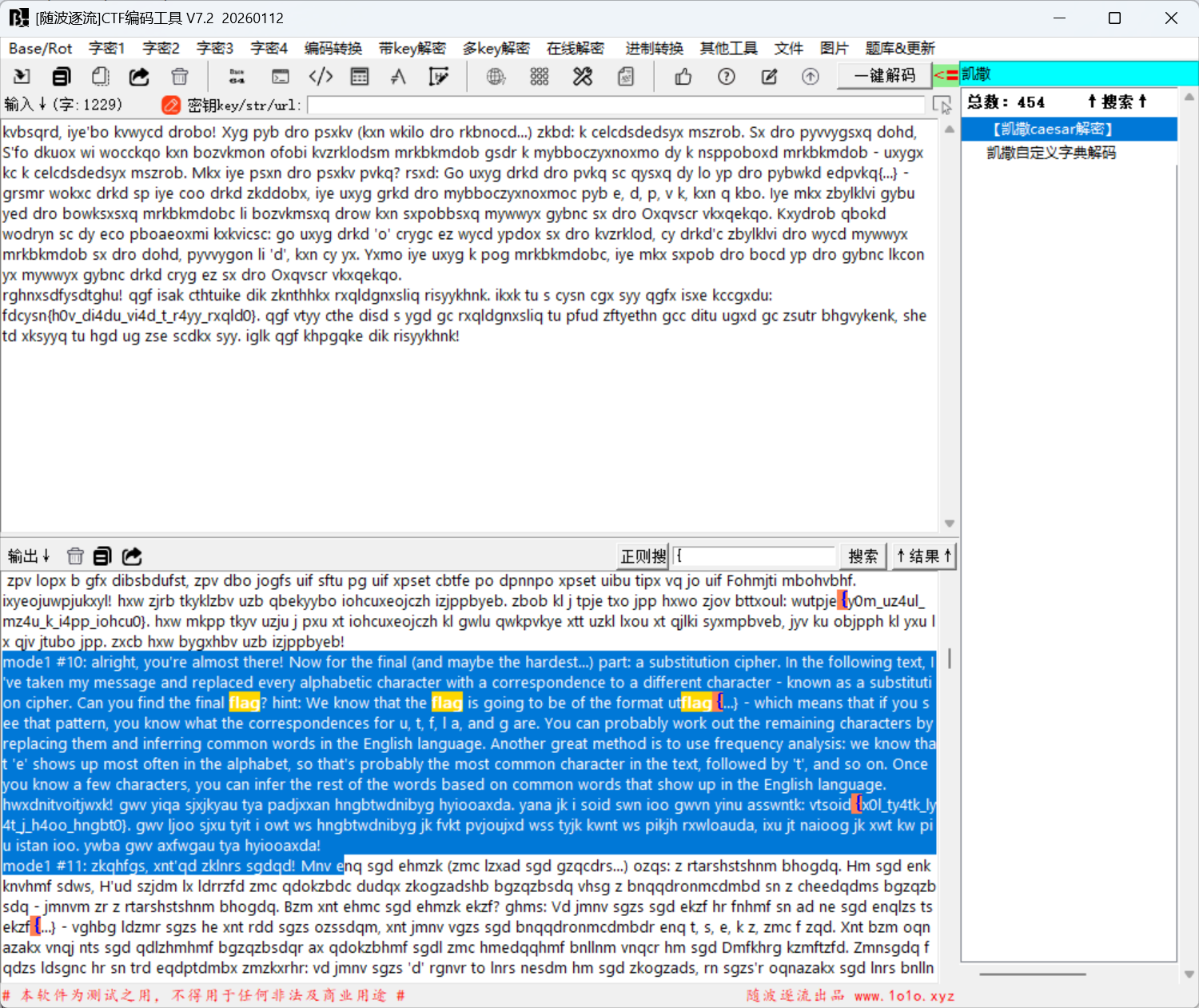
mode1 #10: alright, you're almost there! Now for the final (and maybe the hardest...) part: a substitution cipher. In the following text, I've taken my message and replaced every alphabetic character with a correspondence to a different character - known as a substitution cipher. Can you find the final flag? hint: We know that the flag is going to be of the format utflag{...} - which means that if you see that pattern, you know what the correspondences for u, t, f, l a, and g are. You can probably work out the remaining characters by replacing them and inferring common words in the English language. Another great method is to use frequency analysis: we know that 'e' shows up most often in the alphabet, so that's probably the most common character in the text, followed by 't', and so on. Once you know a few characters, you can infer the rest of the words based on common words that show up in the English language. |
- 微信
- 支付宝


