
【笔记】网络文章笔记
声明
-
以下所有文章都在标题后标明来源网址,如有侵权请联系我的邮箱我将尽快回复并删除
记事
- URL转md网站:
https://devtool.tech/html-md
https://www.helloworld.net/html2md - 待学习:
- https://ctf-wiki.org/pwn/linux/user-mode/mitigation/canary/
hexo的多种markdown渲染器对比分析
1.1、hexo-renderer-marked
Hexo默认的Markdown的渲染器,针对于普通的Markdown的文章书写,该渲染器已经足够,但是由于不支持Mathjax,不支持插件扩展,不支持emoji表情,所以该渲染器也是介绍的渲染器中功能最弱的。
-
GitHub地址:hexojs/hexo-renderer-marked
-
NPM地址:hexo-renderer-marked
版本:2.0.0最近提交:a month ago依赖:hexo-util,marked,strip-indent
-
安装方式:
npm install hexo-renderer-marked —save
1.2、hexo-renderer-kramed
基于hexo-renderer-marked二次开发的渲染器,完善了对Mathjax的支持,仍然不支持插件的扩展,不支持emoji表情。
-
GitHub地址:sun11/hexo-renderer-kramed
-
NPM地址:hexo-renderer-kramed
版本:0.1.4最近提交:2 years ago依赖:hexo-util、kramed、object-assign、strip-indent
-
安装方式:
npm install hexo-renderer-kramed --save
1.3、hexo-renderer-pandoc
与hexo-renderer-marked类似,支持Mathjax语法,不仅可以渲染markdown,还支持textile,reStructedText和许多其他格式,仍然不支持emoji表情;内建的汇总文件db.json将来可能会非常大,同步到 Github 可能会比较慢,博客内建的搜索功能也可能会变得非常慢。
-
GitHub地址:wzpan/hexo-renderer-pandoc
-
NPM地址:hexo-renderer-pandoc
版本:0.1.4最近提交:2 years ago依赖:无
-
安装方式:
npm install hexo-renderer-pandoc --save
1.4、hexo-renderer-markdown-it
支持Mathjax语法(支持不太好),支持Markdown以及CommonMark语法,渲染速度比hexo-renderer-marked快,支持插件配置,支持标题带安全的id信息,支持脚注(上标,下标,下划线)。
-
GitHub地址:hexojs/hexo-renderer-markdown-it
-
NPM地址:hexo-renderer-markdown-it
版本:3.4.1最近提交:4 years ago依赖:较多…
-
安装方式:
npm i hexo-renderer-markdown-it —save
1.5、hexo-renderer-markdown-it-plus
支持Katex插件并默认启用,默认启用插件列表:markdown-it-emoji,markdown-it-sub,markdown-it-sup,markdown-it-deflist,markdown-it-abbr,markdown-it-footnote,markdown-it-ins,markdown-it-mark,@iktakahiro/markdown-it-katex,markdown-it-toc-and-anchor。
-
安装方式:
npm i hexo-renderer-markdown-it-plus —save
ZIP已知明文攻击深入利用
传统明文攻击概况
- 进行ZIP已知明文攻击,通常需要一个完整的明文文件。 而本文讨论的攻击方式只需要知道加密压缩包内容的12个字节,即可进行攻击破解降低了已知明文的攻击难度。同时,结合各类已知的文件格式,更扩宽了ZIP已知明文攻击的攻击面。
- 传统的已知明文攻击要成功需要三个条件:
- 完整的明文文件
- 明文文件需要被相同的压缩算法标准压缩(也可理解为被相同压缩工具压缩)
- 明文对应文件的加密算法需要是 ZipCrypto Store
- 第三点是我们实际应用中常常会被忽略的。因竞赛中遇到的题目,都是提前设置好的
- AES256-Deflate/AES256-Store加密的文件不适用于明文攻击。
- ZIP的加密算法大致分为两种ZipCrypto和AES-256,各自又分Deflate和Store。
ZipCrypto Deflate |
- ZipCrypto算是传统的zip加密方式。只有使用ZipCrypto Deflate /Store才可以使用 ZIP已知明文攻击进行破解。
- 传统的ZIP已知明文攻击利用,windows下可以使用AZPR,linux下可以使用pkcrack。
本文攻击方式
- 两个条件:
- 至少已知明文的12个字节及偏移,其中至少8字节需要连续。
- 明文对应的文件加密方式为ZipCrypto Store
- 查看是ZipCrypto Store加密还是别的加密:用7z打开或者命令行工具可以查看加密算法
7z l -slt XXX.zip |
- 经测试:
- Winrar(v5.80)、7zip(v19.00)默认状态下加密使用的就是AES256算法
- 360压缩(v4.0.0.1220)、好压(v6.2)使用的是ZipCrypto,不固定使用Store或Deflate(如果要固定使用ZipCrypto Store算法加密,可以在压缩的时候指定压缩方式为“存储”)。
bkcrack实操
加密文本破解
- 8+4的方式提取部分已知明文来进行攻击测试,
- 利用以下这部分明文,来进行攻击破解:*lag{16e3************74f6
#准备已知明文 |
- 注:-p 指定的明文不需要转换,-x指定的明文需要转成十六进制
- 提到的偏移都是指 “已知明文在加密前文件中的偏移”。
- 历时近16分钟,成功得到秘钥,这不是压缩包的加密密码,而是ZIP内部的三段秘钥,使用该秘钥进行解密:
bkcrack -C flag_360.zip -c flag.txt -k b21e5df4 ab9a9430 8c336475 -d flag.txt |
利用PNG图片文件头破解
#准备已知明文 |
- 近7分钟破解出秘钥:e0be8d5d 70bb3140 7e983fff
- 利用秘钥解密文件:
bkcrack -C png4.zip -c flag.txt -k e0be8d5d 70bb3140 7e983fff -d flag.txt |
- jpg:
FFD8FFE000104A4649460001 - gif:
474946383961或474946383761
利用zip格式破解
- 一个名为flag.txt的文件打包成ZIP压缩包后,你会发现文件名称会出现在压缩包文件头中,且偏移固定为30。且默认情况下,flag.zip也会作为该压缩包的名称。
- 所以,当一个加密压缩包中存在另一个ZIP压缩包时,且能够知道或猜测该压缩包内的文件名称时,可以尝试进行已知明文攻击。
- 将flag.zip与其他文件(选用一张图片2.png)一起用好压打包成加密ZIP压缩包:test5.zip
- 已知的明文片段有:
- “flag.txt” 8个字节,偏移30
- ZIP本身文件头:50 4B 03 04,4字节
- 8+4,满足了破解的最低要求
echo -n "flag.txt" > plain1.txt //-n参数避免换行,不然文件中会出现换行符,导致攻击失效 |
- 想解密2.png,由于是ZipCrypto deflate加密的,所以解密后需要bkcrack/tool内的inflate.py脚本再次处理。
bkcrack -C test5.zip -c 2.png -k b21e5df4 ab9a9430 8c336475 -d 2.png |
EXE文件格式破解
- 如果加密ZIP压缩包出现以store算法存储的EXE格式文件,很容易进行破解。
- 大部分exe中都有这相同一段,且偏移固定为64:
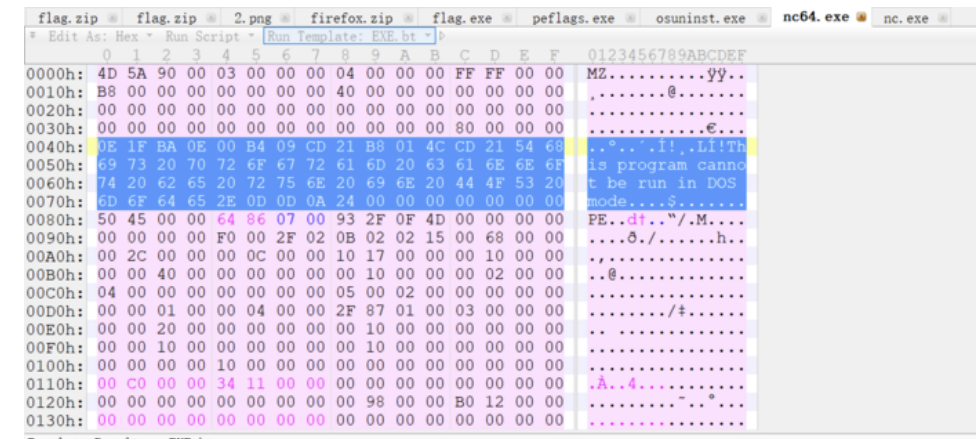
# 准备明文 |
流量包pcapng格式解密
- 这里另外参考:
- http://www.glun.top/2020/10/05/ctf02/
- linux自带命令zipinfo,可以清楚的列出文件大小、压缩方式、压缩率等信息,加-v还能显示详细参数——鹤城杯misc-m1完整复现过程【钓鱼城杯量子加密原题】

- 红分是固定的:
- Block Type始终为 0A0D0D0A;
- Block Total Length是小端存储的Header长度,显然不会超过64KB,所以高两位都是 00 ;
- Byte-Order Magic在小端机器上始终为4D3C2B1A;
- Major Version目前只有 1000 ;Minor Version目前只有 0000 。
- 这样可以知道文件中的 4 + 10 字节内容,满足明文攻击的要求。
- 其实蓝色部分也是可以猜出来的:Section Length是可选字段,大多数软件(比如WireShark)在保存pcapng时会写入-1(即 8 个字节的FF)。
- 00 00 4D 3C 2B 1A 01 00 00 00 FF FF FF FF FF FF FF FF
echo -n "00004D3C2B1A01000000FFFFFFFFFFFFFFFF" | xxd -r -ps > pcap_plain1 |
网站相关文件破解
- 很容易找到突破口
- 例如:
- robots.txt的文件开头内容通常是User-agent: *
- html文件开头通常是
- xml文件开头通常是
- 在此以web.xml为例,web.xml 是网络程序中的一个很重要的配置文件。
- 常见xml文件头为:
<?xml version="1.0" encoding="UTF-8"?> - 网站目录肯定会涉及到多级目录,我们也同样进行模拟。在文件夹中创建一个二级目录“123”,并将一个web.xml放入该二级目录中,然后打包成加密ZIP。
- 攻击:
echo -n '<?xml version="1.0" encoding="UTF-8"?>' > xml_plain |
- 解密:
bkcrack -C xml.zip -c 123/web.xml -k e0be8d5d 70bb3140 7e983fff -d web.xml |
SVG文件格式破解
- xml格式的文件除了.xml以外,也包括.svg文件。SVG是一种基于XML的图像文件格式。
#攻击: |
【pwn之最】RELRO:最小丑的机制
0、先简单介绍一下RELRO
- ReLocation Read-Only,这是一种通过设置“重定位相关表”的权限为“只读”来防止其被修改的安全机制
- 这是个好思想,如果能够实施,一定能够防止大量的可能的攻击的吧,实在是太天才了!
- linux的页机制:但是,我拒绝!
1、介绍一下RELRO的三个等级
(1)no relro
- 关闭RELRO,放弃这趟jocker之旅~
(2)partial relro
- 即“部分relro”,是gcc默认的relro等级,大多数pwn题就算这个等级,因为开高了会影响程序运行速度,开低了就emmmm也没有更低的等级了。
- 但是,因为页机制,这个等级下的relro成为了小丑。
- 先介绍一下这个等级本来的思想:
- 对于.dynamic表,直接将其列为只读,对于got表,got表的每个表项一开始是可写,被符号解析后,它就要被设置为是只读
- 实际实现上,遇到了一个绕不过去的底层问题
操作系统通常以页(通常是4KB大小)为单位来管理内存的权限,也就是说它没法单独修改某个got表项的权限。
也就是说——它在实现上,就变成了:必须got表的所有表项都被符号解析后,.dynamic和.got表才会被划入只读段
- 那就变小丑啦,你正常pwn题注入点的时候,肯定所有符号没有被解析完啊,你怎么说肯定有个exit没有被解析完吧~那你搞了个pratical relro,就变成没有意义了
- 正是:一波理论猛如虎,一看效果0杠五,寄。
同时,该ELF文件的各个部分会被重新排序。内数据段(internal data sections)(如.got,.dtors等)将被置于程序数据段(program’s data sections)(如.data和.bss)之前
(3)full relro
- 该等级下延迟绑定与重定位将被禁止GOT表中的所有符号将在程序开始前被重定位好,然后程序开始运行时整个GOT表就被设置成只读了
- 但是这个时候plt跳板还是存在,也就是call还是会先转到plt跳板处
- 好,好,好,这样终于有用了,这样攻击者终于确实修改不了got表了,不过可惜这样坐会影响程序的启动速度,特别是一些大程序,会要启动大半天。
- 所以——选吧,诸君,to卡or to be 小丑…
另外link_map和_dl_runtime_resolve这两个函数将不会被装载到内存
此时尝试修改got表会遇到程序退出,退出码-11(SIGSEGV)表示遇到了段错误(试图写入只读内存区域)
2、最后介绍一下gcc编译指令
\-z norelro #关闭relro- 啥都不写就是partial relro
\-z relro #开启relro
作者:载酒-下辈子不要学pwn https://www.bilibili.com/read/cv33601003/ 出处:bilibili
RC4
RC4
RC4(来自Rivest Cipher 4)由美国密码学家罗纳德·李维斯特(Ron Rivest)在1987年设计,是一种流加密算法,密钥长度可变。它加解密使用相同的密钥,因此也属于对称加密算法。RC4是有线等效加密(WEP)中采用的加密算法,也曾经是TLS可采用的算法之一。由于RC4算法存在弱点,2015年2月所发布的 RFC 7465 规定禁止在TLS中使用RC4加密算法。
算法
总结起来就3步:
- 通过算法生成一个256字节的S-box。
- 再通过算法每次取出S-box中的某一字节K.
- 将K与明文做异或得到密文。
Step1. 密钥变换算法
for i from 0 to 255 |
先初始化S-box,使得S[0] = 0, S[1] = 1 … S[255] = 255。
而后再打乱S-box,这一步会引入密钥。打乱后得到一个乱序的S-box。
Step2. 伪随机算法
i := 0 |
通过算法取出S-box中的一位K。
Step3. 加密
将上一步取出的K与明文当前字节做异或得到密文。明文的每一字节都会重复2,3步骤。
二维码之QR码生成原理与损坏修复
二维码基础知识
- 一提到二维码,我们就会想起生活中处处都能见到的“二维码”,比如收款码、付款码、微信名片等等。但是严格意义来讲,这些码只是众多二维码中的一种,叫做QR码,也是现在我们使用最广泛的一种二维码。
- 二维码又称二维条码,是用某种特定的几何图形按一定规律在平面(二维方向上)分布的、黑白相间的、记录数据符号信息的图形;在代码编制上巧妙地利用构成计算机内部逻辑基础的“0”、“1”比特流的概念,使用若干个与二进制相对应的几何形体来表示文字数值信息,通过图象输入设备或光电扫描设备自动识读以实现信息自动处理:它具有条码技术的一些共性:每种码制有其特定的字符集;每个字符占有一定的宽度;具有一定的校验功能等。同时还具有对不同行的信息自动识别功能、及处理图形旋转变化点。
- 二维码的种类有很多,除了我们常见的QR码外,使用比较广泛的还有:PDF417、DM、汉信码等。有兴趣的可以自行查阅
QR 码的格式与生成原理
QR码的尺寸
- 首先,我们先说一下QR码一共有40种尺寸。官方叫做版本Version(版本)。
Version 1是21x21的矩阵; |
- 每增加一个version,就会增加4的尺寸(或者称单位,看后面就会理解),公式是:(V-1)*4 + 21(V是版本号) 最高Version 40,(40-1)*4+21 = 177,所以最高是177 x 177的正方形。
鉴于大家平时都已经习惯称呼QR码为二维码,我们后面的内容也就不一直强调QR码,而是称为二维码。大家只要明白,我们后面所说的二维码,都是指QR码即可。
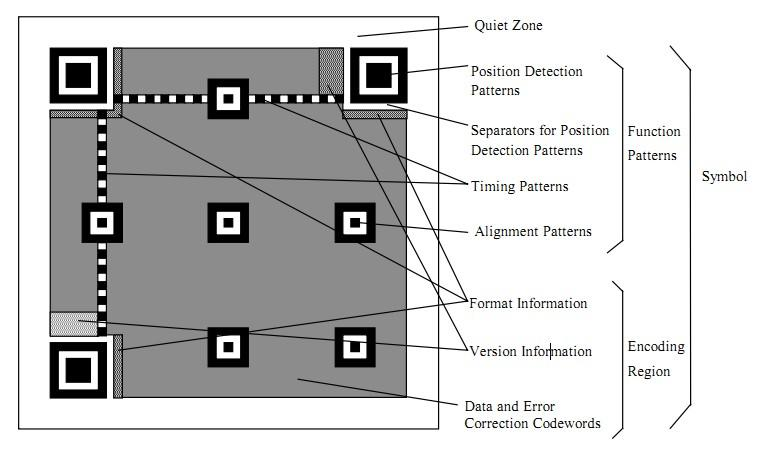
QR码的格式
- QR码格式示例如下:
英文版:
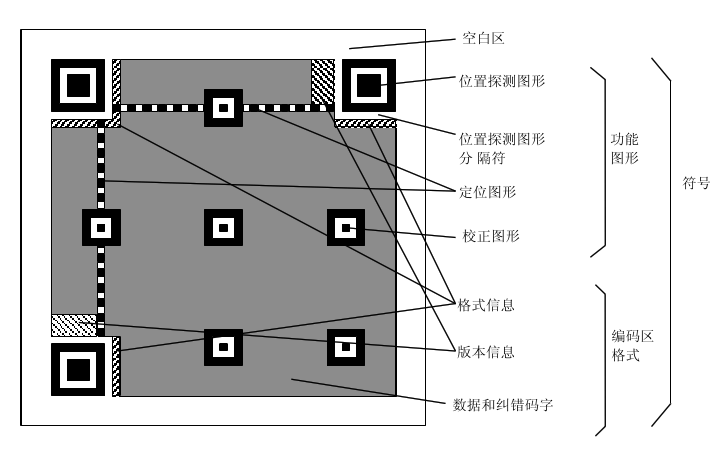
中文版:
定位图案
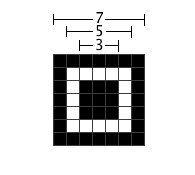
Position Detection Pattern(位置探测图形)是定位图案的一种,就是每个二维码都有的左上、左下和右上三个角的“回”字形的标志。用于标记二维码的矩形大小。这三个定位图案有白边叫Separators for Postion Detection Patterns。之所以三个而不是四个,因为三个就足以标识一个矩形了,用四个反而多余,且会使得能够表示的数据空间变小,扫描器在进行二维码扫描的时候会根据这三个定位标识符来更正二维码的坐标,方便进行扫描。这块区域的尺寸固定,无论是哪个版本的二维码,他的尺寸都是7*7的模块。
Alignment Patterns(校正图形) 只有在Version 2以上(包括Version2)的二维码中需要这个东西,同样是为了定位用的。它的尺寸也是固定的,为5*5的模块。
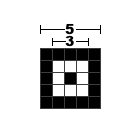
Timing Patterns(定位图形)也是用于定位的,是一单位宽的黑白交替点带,由黑色点起始和结束。原因是二维码有40种尺寸,尺寸过大了后需要有根标准线,不然扫描的时候可能会扫歪了。
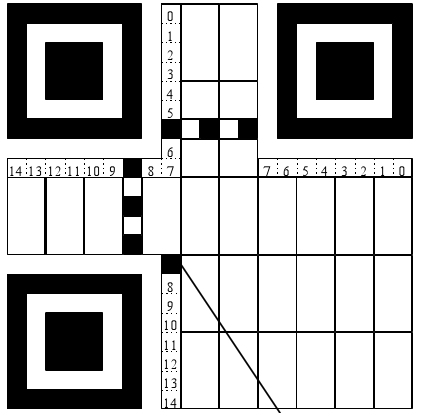
格式信息
Format Information 存在于所有的版本中,用于存放一些格式化数据的,通过读取这部分的内容,可以知道当前二维码的纠错等级、掩码类别。主要内容为“纠错等级(2bit)+ 掩码类别(3bit)+ BCH code(10bit,用于纠错)”,然后这15个bits还要与101010000010010做XOR操作,主要是为了如果选用了00的纠错级别和000的Mask,从而造成全部为白色,这会增加扫描器的图像识别的困难。
纠错等级的比特表示:

为了增强二维码的容错能力,保证在一定的损坏范围内,不会影响数据的读取,共设计了两个区域来存放两条一模一样的格式信息。
这15个bit在format information区域内的分布以及顺序如下(下图中数字的顺序就是这15个bit的存放顺序,应当注意的是这些数字表示的是位的高低,也就是当获取到格式信息15个bit长度的二进制字符串时,左边为高位,右边为低位,所以最左侧的二进制数字应该在14的位置,最右侧的二进制数字应该在0的位置):
版本信息
Version Information 在>= Version 7的版本中,预留两块3*6的区域存放一些版本信息。
数据码字和纠错码字
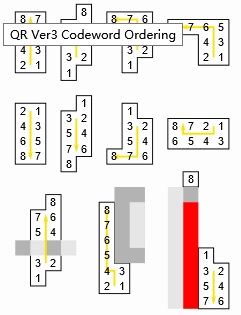
除了上述的那些地方,剩下的地方存放 Data Code 数据码字 和 Error Correction Code 纠错码字。我们后面就简称数据码和纠错码,就是最前面两张图的深灰色区域,一般数据都是从右下角开始填充,先填充数据码,数据码填充完毕之后再填充纠错码,以version1为例,数据的填充顺序,是这样的:
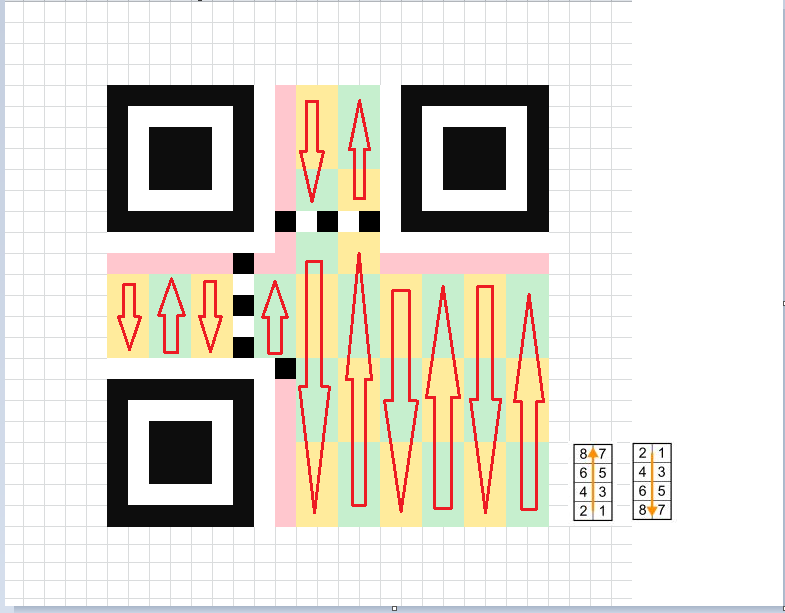
当然,随着版本的升高,会有越来越多的校正图形掺杂在其中,这样的话,数据填充可能就不是这么规矩的矩形了,但是总体的填充顺序不会大变化,都是先右后左的顺序。具体的可参考官方的文档。
数据编码与编码流程
QR码支持的数据编码
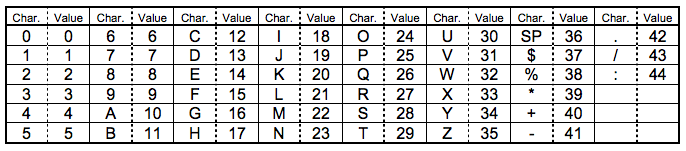
- Numeric mode(数字编码),从0到9。
- Alphanumeric mode(字符编码),包括0-9,大写的A到Z(没有小写),以及符号“$ % * + – . / : 空格”。
- Byte mode (字节编码),可以是0-255的ISO-8859-1字符。
- Kanji mode (日文编码),也是双字节编码。
- Extended Channel Interpretation (ECI) mode 主要用于特殊的字符集。并不是所有的扫描器都支持这种编码。
- Structured Append mode 用于混合编码,也就是说,这个二维码中包含了多种编码格式。
- FNC1 mode 这种编码方式主要是给一些特殊的工业或行业用的。比如GS1条形码之类的。
下表是每个模式的编码相对应的“编号”。
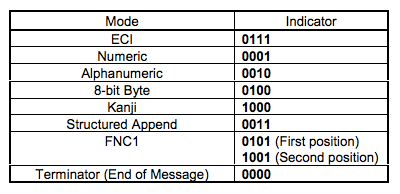
因为种类较多较复杂,而且为了方便大家理解,我们在这里值选择数字编码和字符编码举例,其它的编码,有兴趣的朋友可以查看官方文档。
示例一:
Numeric mode 数字编码,仅支持对从0到9的数字进行编码,也就是使用这个编码的二维码,扫描出来的内容只会是一串数字。如果需要编码的数字的个数不是3的倍数,那么,最后剩下的1或2位数会被转成4或7bits,则其它的每3位数字会被编成长度为10位的二进制数,最后将这些二进制数据连接起来并在前面加上编码模式的编号和字符计数指示符(就是表示了被编码的信息有多少个字符),字符计数指示符的长度取决于编码的模式和所要编成二维码的版本,在数字编码中,字符计数指示符如下表对应的有10、12或14位:
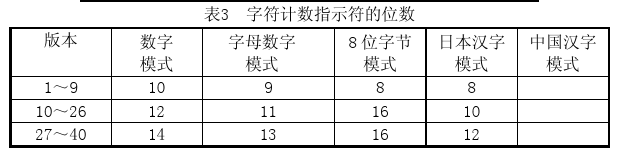
比如在Version 1的尺寸下,纠错级别为H(表示纠错等级为“高”,纠错级别我们会在下面讲到)的情况下,我们要编码的内容为:01234567
> (1). 按照每3个字符一组,把上述数字分成三组: 012 345 67 |
示例二:
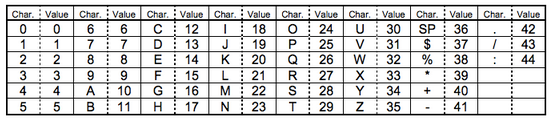
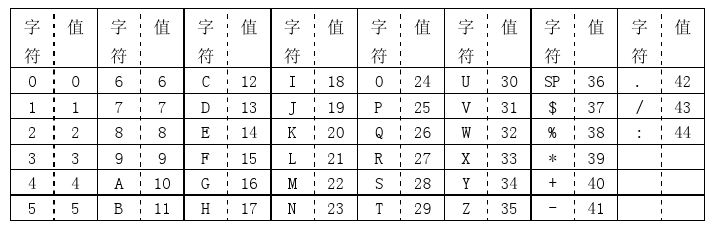
Alphanumeric mode 字符编码(也叫字母数字编码)。包括0-9,大写的A到Z(没有小写),以及符号“$ % * + – . / : 空格”。这些字符会映射成一个字符索引表。如下所示(两个表,中英文对照):(其中的SP是空格,Char是字符,Value是其索引值)编码的过程是把字符转换为索引值,之后两两分组,按照特殊的算法转换成十进制的数值(这个算法,虽然简单,但是也是相当有想法,将前面的数值乘以45,加上后面的数值,组成一个十进制的数,这样在后期解码的时候,只用逆运算,用最后这个十进制的数除以45,得到的商和余数,就是原来的两个数),最后转成11bits的二进制,如果最后有一个落单的,那就转成6bits的二进制。而字符计数指示符需要根据不同的Version尺寸编成9,11或13个二进制(如上表)。
在Version 1的尺寸下,纠错级别为H的情况下,对“AC-42”进行编码:
> (1). 从字符索引表中找到 AC-42 这五个字条的索引 (10,12,41,4,2) |
结束符和补齐符
以上述示例一为基础,在编码结束后,我们得到了如下编码:

然后,我们还要加上结束符,表示真正的额数据已经结束。

按每组8个bit分组,如果所有的编码加起来不是8个倍数我们还要在后面加上足够的0,比如上面一共有45个bit,所以,我们还要加上3个0,然后按8个bits分好组:
00010000 00100000 00001100 01010110 01100001 10000000 |
再然后,就是补齐符(padding bytes),如果添加上结束符之后还没有达到我们最大的bits数的限制,我们还要加一些补齐码(Padding Bytes),Padding Bytes就是重复这两个bytes:11101100 00010001。(使用这两个字节的主要原因是,为了防止在填入数据时出现大片的深色或浅色区域,对扫描器产生干扰,使得二维码难以正常扫描),至于要补多少个补齐符,需要查看文档中相应的字符数和数据容量对应表,由于版本比较多,我们不一一列出,在官方文档中,我们示例相对应的是表7-表11。我们以下表为例:
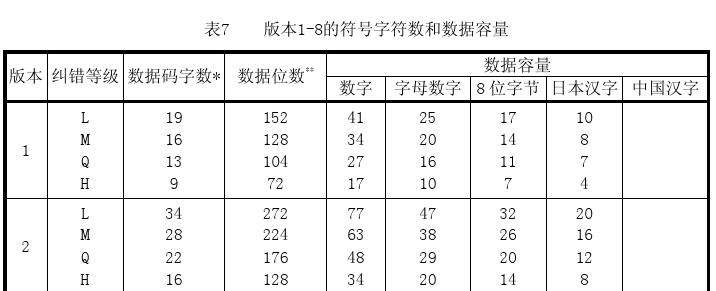
从表中,我们可以知道,version1-H的数据容量为9个数据码字(每个数据码字为8位),而我们上面已经有了6个数据码字,所以要补充三个8bit,补充完毕如下:
00010000 00100000 00001100 01010110 01100001 10000000 11101100 00010001 11101100 |
上面的每一组数据为一个数据码字,Data Codewords,现在也只是原始数据,还需要对其加上纠错码。
纠错码
上面我们提到了纠错级别,Error Correction Code Level,二维码中有四种级别的纠错(从低到高为L、M、Q、H),这就是为什么有人在二维码的中心位置加入图标,也依旧能够扫描的原因。(就是二维码残缺量不超过所对应的纠错等级允许的范围时,使用扫描工具依旧能扫描出内容的原因)。纠错等级对应的容错范围如下:
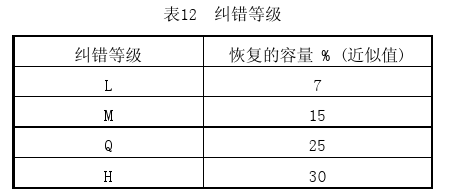
即只要二维码的损坏面积没有超过这个范围,理论上是可以恢复损坏的数据的。
- 至于纠错码是如何计算的,这涉及到里德-所罗门纠错算法(Reed-Solomon error correction),里德-所罗门码是定长码。这意味着一个固定长度输入的数据将被处理成一个固定长度的输出数据。在最常用的(255,223)里所码中,223个里德-所罗门输入符号(每个符号有8个位元)被编码成255个输出符号。大多数里所错误校正编码流程是成体系的。这意味着输出的码字中有一部分包含着输入数据的原始形式。符号大小为8位元的里所码迫使码长(编码长度)最长为255个符号。标准的(255,223)里所码可以在每个码字中校正最多16个里所符号的错误。由于每个符号事实上是8个位元,这意味着这个码可以校正最多16个短爆发性错误。
- 里德-所罗门码,如同卷积码一样,是一种透明码。这代表如果信道符号在队列的某些地方被反转,解码器一样可以工作。解码结果将是原始数据的补充。但是,里所码在缩短后会失去透明性。在缩短了的码中,“丢失”的比特需要被0或者1替代,这由数据是否需要补足而决定。(如果符号这时候反转,替代的0需要变成1)。于是乎,需要在里所解码前对数据进行强制性的侦测决定(“是”或者“补足”)。
这两段话是我抄的,什么意思我也不懂,但我们有现成的python模块来运算出纠错码——python的reedsolo模块,我们只要会用就行了,数学好的朋友可以去研究具体算法的实现。
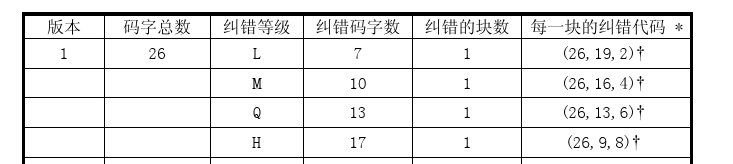
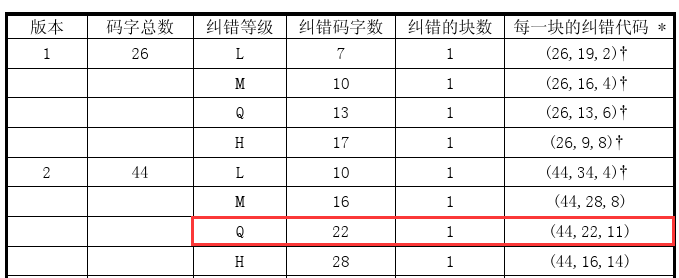
那么,哪个版本应该生成几个纠错码?我们可以对照官方文档中的纠错特性表,表13-表22。以下表为例:
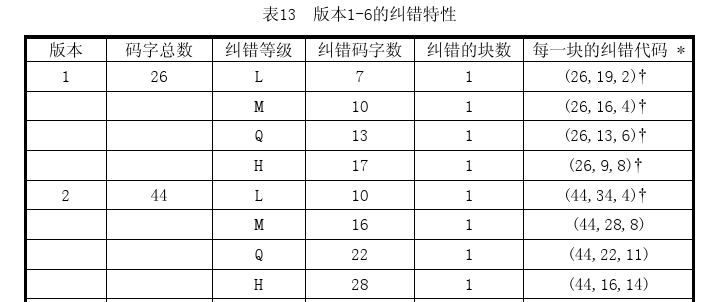
以版本1-H为例进行解释,从表中,我们可以清晰的知道,纠错码字数应该为17个,纠错的块数为1(表示这个版本要编码的数据只会分为一个数据块),(26,9,8)表示,这个版本的二维码总共可以存放26个码字,但是这26个码字中,有9个码字为数据码字,17个为纠错码字(8*2+1=17),8位纠错容量。每个表的下方附有注释信息:

这也是为什么纠错码字数为r_2,当后面有一个箭头时,表示r_2之后还要加1。
在给数据码字添加纠错码时,还有对数据码字分块的操作,因为version1的二维码对数据码字只分一个块,不够明显,所以我们采用网上的我所参考过的一个例子(现在不太容易找出处了,时间太久远了):
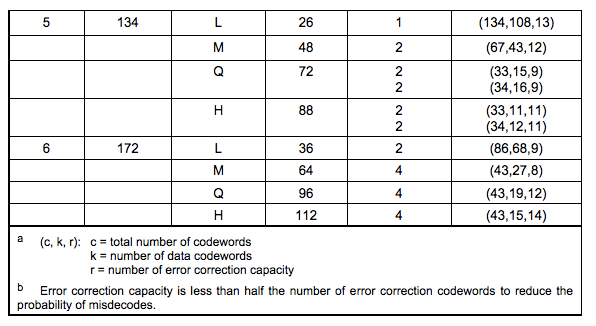
这个例子使用的是Version 5 Q纠错等级的二维码,从表中得知需要4个纠错块(2,2表示纠错块有两2组,每组2个),头一组的两个Blocks中各15个数据码字加上各18个纠错码字。
因为二进制写起来会让表格太大,所以,都用了十进制来表示,我们简述一下下表是如何生成的:在将数据编码之后,每8位分开,形成我们需要的数据码字,然后再将数据码字按照规定分成15:15:16:16的四组,分别进行纠错码的运算,生成的纠错码字数都是18。
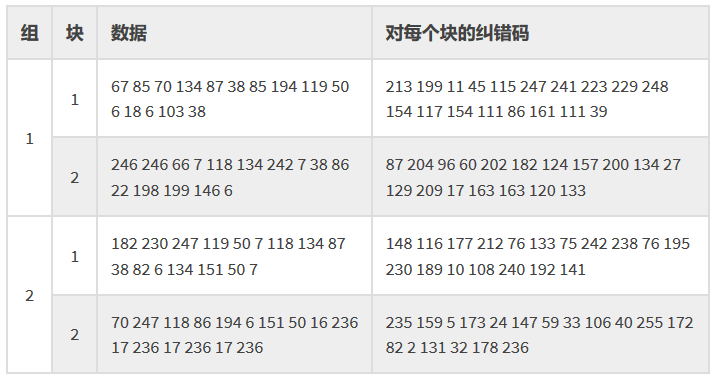
最终将这些码字穿插放置。但是也不是随意穿插,是数据码字与数据码字穿插,纠错码字与纠错码字穿插。
对于数据码字:把每个块的第一个数据码字先拿出来排列好,然后再取第一块的第二个,如此类推。上述示例中的数据码字Data Codewords如下:
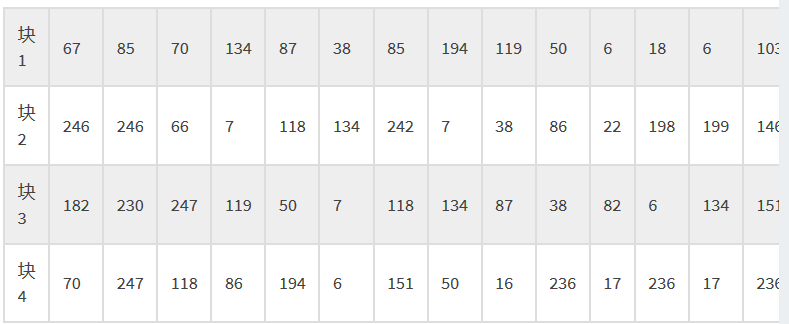
> 我们先取第一列的:67, 246, 182, 70 |
对于纠错码,也是一样:
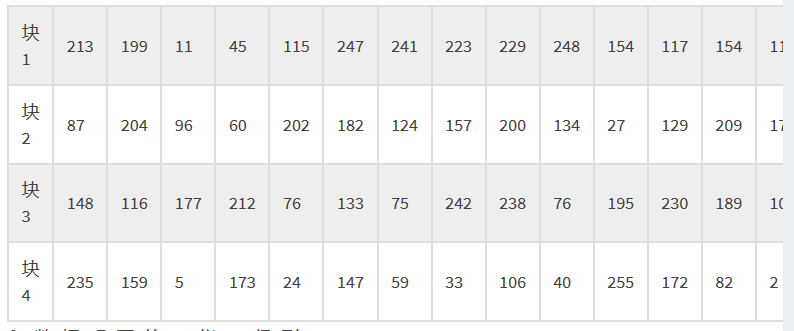
和数据码取的一样,得到:213,87,148,235,199,204,116,159,…… …… 39,133,141,236 |
然后,再把这两组放在一起(纠错码放在数据码之后)得到:
67, 246, 182, 70, 85, 246, 230, 247, 70, 66, 247, 118, 134, 7, 119, 86, 87, 118, 50, 194, 38, 134, 7, 6, 85, 242, 118, 151, 194, 7, 134, 50, 119, 38, 87, 16, 50, 86, 38, 236, 6, 22, 82, 17, 18, 198, 6, 236, 6, 199, 134, 17, 103, 146, 151, 236, 38, 6, 50, 17, 7, 236, 213, 87, 148, 235, 199, 204, 116, 159, 11, 96, 177, 5, 45, 60, 212, 173, 115, 202, 76, 24, 247, 182, 133, 147, 241, 124, 75, 59, 223, 157, 242, 33, 229, 200, 238, 106, 248, 134, 76, 40, 154, 27, 195, 255, 117, 129, 230, 172, 154, 209, 189, 82, 111, 17, 10, 2, 86, 163, 108, 131, 161, 163, 240, 32, 111, 120, 192, 178, 39, 133, 141, 236 |
Remainder Bits(剩余位)
最后再加上Reminder Bits,对于某些Version的QR,上面的还不够长度,还要加上Remainder Bits,比如:上述的5Q版的二维码,还要加上7个bits,Remainder Bits加零就好了。关于哪些Version需要多少个Remainder bit,可以参看官方文档的表一(这里列出一部分)。
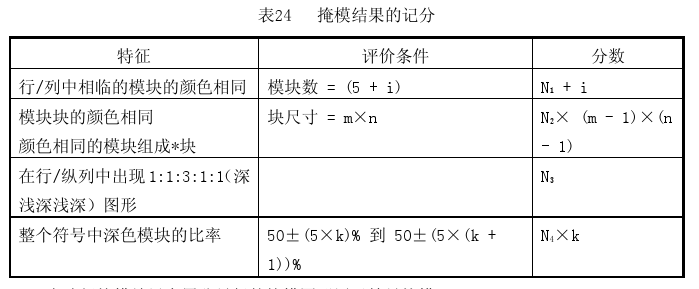
掩码(也叫掩模)
编码的步骤是完成了,但是要想生成一个完整的二维码,还需要先将现在所拥有的数据填入提前准备的空白模板后,选择一个合适的掩码,将原模板的数据与掩码进行异或运算,最后,再将format information填进去就生成了二维码。
掩码存在的意义:二维码是要拿来扫描的,而扫描怕的就是无法清晰地分辨出编码信息的每一位。要是二维码中黑白点数量不均,或是空间分布不均都会导致大色块区域的出现,而大色块区域的出现会增加扫描时定位的难度,从而降低扫描的效率。更严重的情况下,如果数据填入后碰巧出现了功能性标识,比如定位标识的图样,还会干扰正常功能性标识的作用,导致QR码无法扫描。
在计算机科学中,掩码就是一个二进制串,通过和数据进行异或运算来变换数据。在QR码中,掩码也是通过异或运算来变换数据矩阵。QR码的掩码就是预先定义好的矩阵。QR标准通过生成规则定义了八个数据掩码(最后一个的编号,应该是111而不是110,图片错了):

前面的三位二进制的数据就是每个模式掩码相对应的编号,这个信息也是要填入format information中的。具体的掩码图片是这样的:

从这个图我们就可以直观的看到每种掩码的模板样子,以掩码2(编号为010)为例,公式 j mod 3 = 0 就是表示从左边开始数,能被3整除的列,都要取逆(黑块变白块,白块变黑块),当然二维码的固定格式区域的信息是不用取逆的,所以要使用掩码2,需要取逆的列数为:0、3、6、9……。
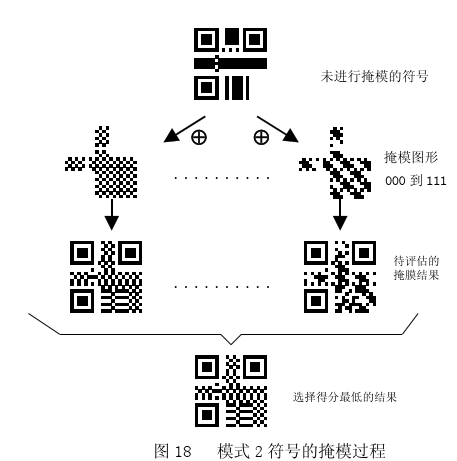
当然,官方规定在进行异或时,原始的数据模板要与每个掩码模板进行异或运算后,要进行如下的规则进行计分(处罚),最后选择分数最低的一个作为最佳的掩码选择。这里我们只做了解,不深入。
手绘二维码
在这一小节,我计划用excel手动画出一个二维码,目标是使用手机能够扫描出“HELLO”。
准备固定格式的填充模板
利用前面所学到的内容,就已经足够我们手动来描绘出一个简单的二维码,我们要画的是一个version1且容错等级为H的二维码,从上面的基础知识中知道,版本1的二维码尺寸为21_21,所以我们整理出一个21_21的表格(最好将每一单位的模块都调整成正方形),并提前画好version1二维码中的固定格式部分。如下图,是一个version1版本的二维码的所有固定格式。
进行数据编码
接下来就是对数据进行编码,由于进行编码的内容“HELLO”,全部为大写字母,且不存在特殊符号。所以这里选用字符编码是最方便的。
根据前面的示例,可以很简单的知道如何来运算得到二进制的数据:
1. 从字符索引表中找到“HELLO”相对应的值。(17,14,21,21,24) |
计算纠错码
根据纠错特性表来进行分块和添加纠错码:
由表我们知道,码字总数为26,纠错码字数为17,再加上我们之前编码好的数据9个8bit,刚好是26.
计算纠错码:

码字整理
整理一下得到的码字:
> 数据码字:32,43,11,120,204,0,236,17,236 |
数据填充
得到所有的码字之后,就是简单但是麻烦的数据填充了:
由于我们制作的是version1的二维码,所以不需要进行数据块的排序。直接按照如下的图片进行数据块的填充(先填充数据码字,再填充纠错码字)。
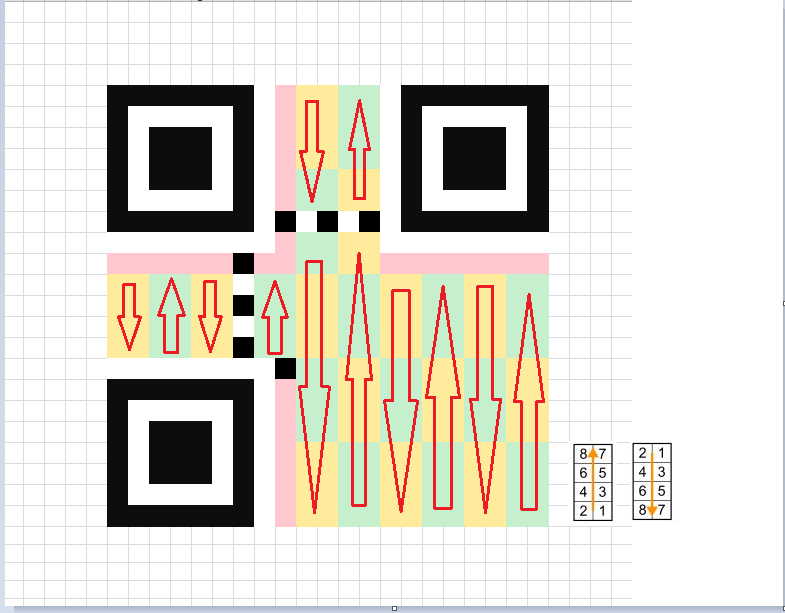
如:填充完第一个第二个数据码字的时候,应该是这个样子的:

全部填充完毕如下图,(剩下的粉红色的部分,是格式信息的位置,我们到后面再填充):

将相应的format information信息填充进相应的区域。
- 纠错码等级:H 对应的编码为:10
- 掩码类别:2 对应的编码为:010
- BCH纠错比特:这里我们为了方便,直接查看对应关系,如下图,意思是一个二维码,如果它的纠错等级为H,所采用的的掩码为2,那么后面的二进制字符串即为它所对应的format information。参考地址:https://www.thonky.com/qr-code-tutorial/format-version-tables#list-of-all-format-information-strings

- 最终15个bit的数据为: 001110011100111

将其填充进format information数据区(注意填充顺序0-14所对应的是二进制的低位到高位)。

与掩码进行异或运算
我们前面提到,我们使用的是掩码2,也就是下面这个掩码:
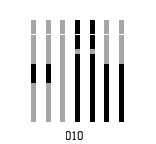
j mod 3 = 0 意思就是从左往右数,凡是能够被3整除的列,颜色都要取反(黑变白,白变黑)。我们将要进行反色的列标注出来(这里我是用的是在对应的列下方标粉色)。注意:功能性区域的不用取逆,就是一开始准备的固定格式的地方和之后的format information区域的数据,不用取逆。

手绘完成
OK,大功告成。现在用我们的手机就可以扫描了:

MMA2015-MISC400-qr二维码恢复挑战
学以致用,复现MMA2015-MISC400-qr的二维码恢复挑战的解题步骤,原版write-up地址为:
https://github.com/pwning/public-writeup/blob/master/mma2015/misc400-qr/writeup.md
我的恢复思路也是跟着wp来的。
注:python官方下载的reedsolo模块版本为0.3,不是很好用,所以我们这次使用write-up中推荐的版本,下载解压后运行python setup.py install即可。
题目分析
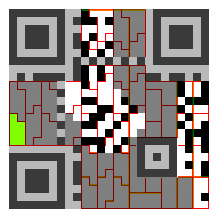
题目给出的二维码如下图:

根据对QR码的了解,知道这是一个25*25的二维码,也就是version2的二维码,从它能看见的部分我们可以得到format information的一部分信息:
??????011011010 |
获取格式信息
对照下面这个网址所给出的对应表,可以知道这个二维码使用了什么编码模式和使用了哪一个掩码
https://www.thonky.com/qr-code-tutorial/format-version-tables\#list-of-all-format-information-strings
【此网址已失效】

经对照可知:
- 完整的format information信息应该是:010111011011010
- 且可以得到的信息还有该二维码使用的掩码为:6,对应的计算公式:( (ij) mod 2 + (ij) mod 3 ) mod 2 = 0
- 所对应的纠错等级为:Q
将被遮挡的固定信息部分以及format information信息补充完整。

获取原始码字
与相对应的掩码进行异或运算,得到原始的数据中的一部分数据码字和纠错码字。这个掩码对应的公式比较麻烦,且不容易计算,好在官方的文档中有提供各个掩码相对应的图案,如下图就是掩码6相对应的图案,如果不会计算公式,可以手动画一个与题目大小一样的掩码图,其对应的小图案大小是不变的,不同版本的二维码,只是小图案的数量不同:

将掩码应用到我们补充完的二维码上,翻转与掩码中深色区域相对应的区域的颜色,并用灰色将format information覆盖,方便读取数据,最后得到的如下图:

从右下角开始,按下图的蛇形顺序读取数据码字和纠错码字的信息,至于不同区域块的信息读取顺序,可以参考官方文档。
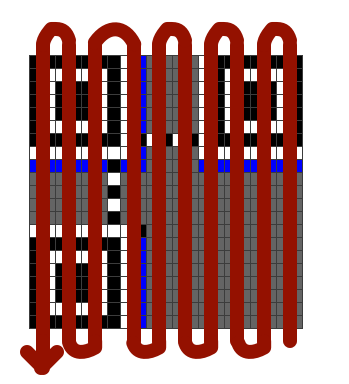
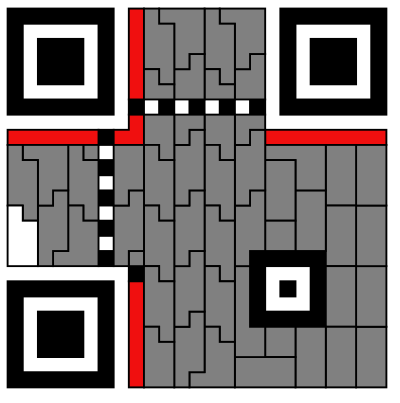
且相对应的数据块分布应该如下图所示:
将全部可读的信息读取出来:
00100000 10100010 10111000 00111010 01011001 10011010 10001000 ???????? |
尽可能多地恢复数据
根据官方文档的纠错特性表,可知version2-Q的纠错码字数有22个,数据码字数也有22个,在Q级别,它可以恢复不超过25%的损坏的字节,但是我们只有16个完整的字节,即超过63%的字节丢失,但是Reed-Solomon的纠错能力很强,如果它知道错误在哪里,那么纠错能力就强得多,可以纠正多达两倍的擦除。但是这个比例也才只到50%,还不能直接把丢失的数据恢复出来。所以我们要想办法恢复一部分字节使得达到所拥有的完整数据有22个字节这个最低要求。
我们先将获得的可读取数据整理一下:
0010:【编码模式=字符编码(字母数字模式)】 |
我们计算一下,22个数据码字,就是176个bit,而字符计数标识符表示总共有20个字符被编码,在编码的时候分为10组,每组11个bit,所以4+9+10*11=123个bit,也就是真正储存信息的数据码字共有123个bit,123/8=15余3,也就是结束符在第16个字节码,所以在第16个字节码的第4位开始,加上4个0(结束符),又因为8bit重组时需要补充为8的倍数,8-3-4=1,所以还需要加1个0。这时候总共也就16个数据码字,22-16=6,所以还要加上6个字节的补齐码,最终获得的数据码字的内容如下:
00100000 10100010 10111000 00111010 01011001 10011010 10001000 ???????? |
这样,我们就手动恢复了6个字节的数据,此时我们丢失的码字就只剩下22个了,正好达到了最低的要求。我们就可以使用纠错码恢复原本的数据。
编写脚本恢复
编写脚本利用python的reedsolo模块进行纠错(脚本文件已经存在与step3文件夹下)。
import sys |
得到全部的信息:
00100000 10100010 10111000 00111010 01011001 10011010 10001000 00101111 |
拆分和解码
> 0010 [编码模式=字符编码] |
二维码恢复挑战-二维码恢复工具
二维码恢复工具:qrazybox
工具下载地址:https://github.com/Merricx/qrazybox/tree/master/js
声明:
本次使用的题目是某次CTF比赛的题目,但是具体是哪次比赛的,我也不是很清楚。只是某天在群里划水的时候,间接得到了题目的文件,所以尝试进行了解答;由于是之后进行的回忆,自己也懒得再做一遍了,所以只能依靠当时解题时的一些零碎数据来拼凑一下完整的过程(我当时是手工做的,很费时间)。
> QRazyBox 是一个基于 Web 的应用程序(工具包),用于分析和恢复损坏的二维码。 |
总体来说,这是一个辅助类型的工具,可以帮助你更好的分析损坏的QR码。
题目分析
这个题目的文件如下:

可以看到损坏的程度并不高(至少比上一道题少),我们先尝试手工读取内容,根据前面的知识,我们可以得知:
那么可以尝试将它画在excel表格中,并将缺失的定位点和格式信息补上:

整理已知信息
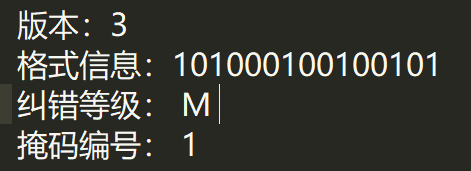
手动解码的步骤我们就不在这里描述了,我们直接放出解码时需要的内容:
> 版本:3 |
恢复初始数据
计算掩码的行数与列数(python):
for row in range(29): |
手动将掩码反色的点返回来:

读取数据码字
01000001 11000111 10100110 10100110 00110111 |
整理信息
> 0100 = 编码模式 8-bit Byte |
跟前面读取的数据比对一下,可以知道前28个码字都是完整的,这就意味着我们都不需要使用纠错码来纠错,直接读取就行了。
脚本读取
最后的解密代码:
s = '''01111010 01101010 01100011 0111 |
将上面的代码运行,即可得到最终的flag。
使用工具恢复
现在我们讲如何使用工具:
从github上将qrzybox-master下载下来,将index.html文件拖入浏览器中打开,然后点击“new project”–> “import from image”,然后将“恢复固定格式.png”导入:
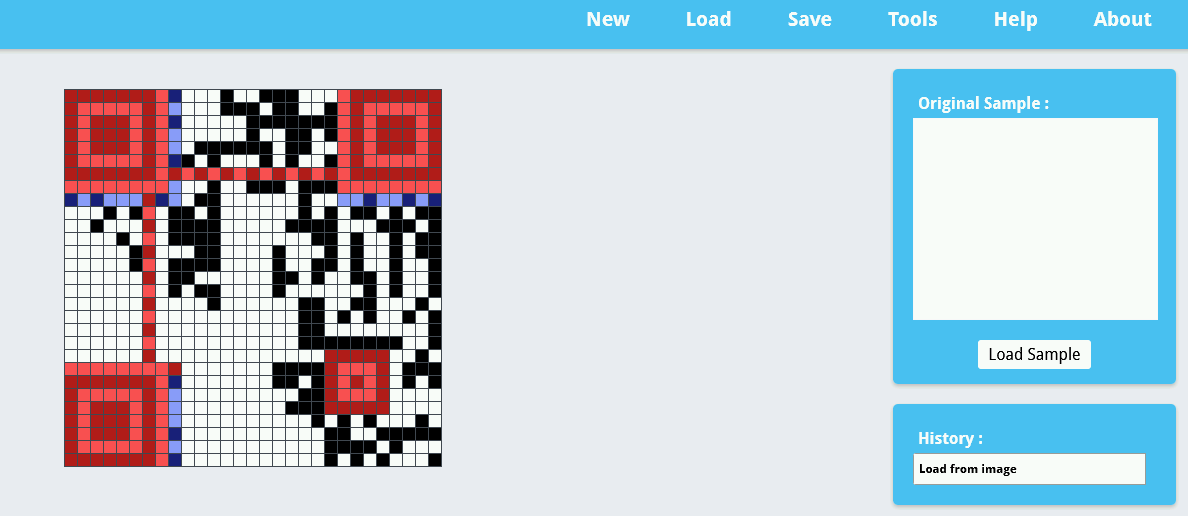
然后点击“tools”–>“Extract QR information”,即可恢复数据:
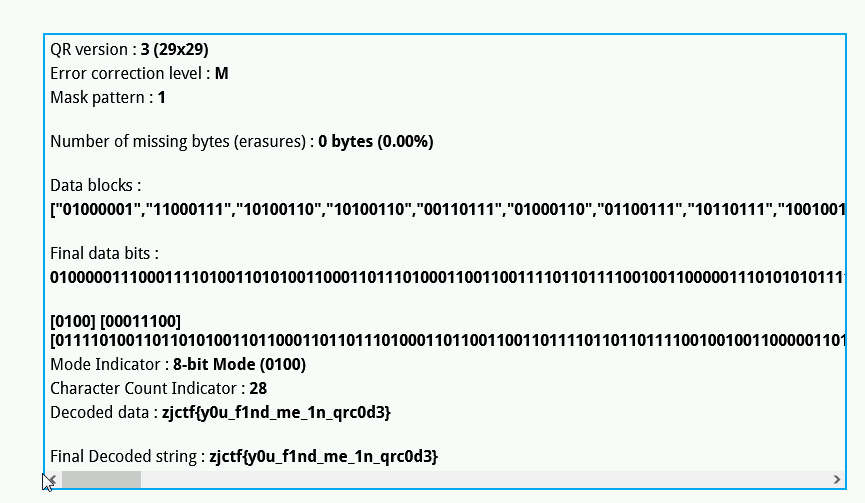
就这么简单,当然这个工具还有很多其他的用处,就开大家自己去研究了。
参考文章
二维码生成细节和原理:
https://zhuanlan.zhihu.com/p/21463650
https://coolshell.cn/articles/10590.html
官方文档(中文版):
https://wenku.baidu.com/view/ef77275f312b3169a451a4a4.html?pn=50
里德-所罗门码:
https://www.jianshu.com/p/8208aad537bb
https://en.wikiversity.org/wiki/Reed–Solomon_codes_for_coders#Encoding_outline
https://stackoverflow.com/questions/30363903/optimizing-a-reed-solomon-encoder-polynomial-division
MMA2015-MISC400-qr的write up
https://github.com/pwning/public-writeup/blob/master/mma2015/misc400-qr/writeup.md
MODBUS中文版
CTFSHOW-2026元旦跨年欢乐赛-CS2026大佬wp
演讲《服务器端模板注入:现代Web应用的RCE》英文版文档
信息收集-DNS解释-layer-fofa
一.DNS 信息收集
DNS概念:域名与ip被绑定的记录存在在DNS服务器,是进行域名和与之相对应的IP地址转换的服务器。
1、将域名解析为 IP 地址
通过ping命令:ping baidu.com -c 3 -4(-c指定发送数据包数量,-4指定使用IPV4)
这里将百度的域名转换为了IP就是110.242.68.66。
DNS解析过程:
<1>.先向根发送请求
<2>.根将xxx.com的预服务器的地址发送给请求端
<3>.对应目标服务器DNS中获取IP地址返回客户端
<4>.向IP地址发送请求
总结:通过域名找IP地址
2.多地ping
可以显示从全国各地进行ping扫时各地的响应
当你kali:ping不通的时候可以在这里查看,是目标服务器坏了还是你kali网出问题了。
二.域名概念
1.域名分为主域名,一级域名,二级域名,多级域名
例如fjw.com就是主域名,shuai.fjw.com就是一级域名,zhen.shuai.fjw.com就是二级域名。
2.子域名是某个主域的二级域名或者多级域名,在防御措施严密情况下无法直接拿下主域,那么就可以采用迂回战术拿下子域名,然后无限靠近主域。
3.常见顶级域名:.com(工商金融)/.cn(中国)/.gov.cn(政府)这个碰到了绕道走,进去别说跟我学的。/.edu.cn(教育)/.org(非盈利组织)/.net 网络信息中心
4.通常子域名收集到四级即可不必太多。
三.子域名收集
1.layer-子域名挖掘机
介绍:暴力枚举子域名
!!注意这里我跑的是a.mi.com浏览器上打开却是mi.com,是因为泛解析:***(无论输入什么).mi.com 都会指向mi.com的主域名。这是网站开发人员设置的。所以你收集到的很多域名都可能是重的。需要你自己去整理。
这里我跑的都是一级域名
2.站长之家子域名查询
https://tool.chinaz.com/subdomain
没vip有次数限制,要登陆,感觉一般。
3.google搜索引擎查找
google语法:site:xiaomi.com
搜索出来的结果都是子域名
4.fofa钟馗之眼搜集子域名
网站:https://fofa.info/
要登陆的,有限制搜索的,
语法:domain=“xiaomi.com”
【Cheatengine】Ⅶ:ce教程-自动汇编(基础知识)
- https://www.bilibili.com/opus/377368436654250777/?from=readlist
- 记录作用,如有侵权请联系我删除
这个汇编表–部分是我自己的解释,大部分都是从网上down下来的,就不标原创了,虽然我给了很多注解
本章开始前,我们必须先了解一下基本的汇编命令及其含义,才能在自动汇编写出得心应手的代码。实现各种强大的功能。本教程没有具体内容,可不看,这个表是你在ct的时候拿来查的,仅此而已,背是不可能背下来的
1.寄存器:
寄存器通常都用来意指由一个指令之输出或输入可以直接索引到的暂存器群组。更适当的是称他们为“架构寄存器”。
在自动汇编里面,我们会经常用到寄存器,怎么理解呢,就是临时存放东西的一个盒子吧,首先我们了解一下寄存器的种类,嗯,你看不懂的,但其实没关系,只是个名字而已。
一.16 位寄存器(远古寄存器)
AX: 累加器。也能做寄存器
BX: 空闲寄存器
CX: 计数器。也能做寄存器
DX: 数据寄存器。也能做寄存器。
SI: 源址变址寄存器。字符串形式的指针,也能做寄存器。
DI: 目的变址寄存器。字符串形式的指针,也能做寄存器。
BP: 机制指针寄存器。临时存储ESP,也能做寄存器。
SP: 原址指针寄存器。堆栈种指向寄存器和地址。
IP: 指令指针寄存器。
二.32 位寄存器(常用寄存器)
EAX: 累加器。也能做寄存器
EBX: 空闲寄存器
ECX: 计数器。也能做寄存器
EDX: 数据寄存器。也能做寄存器。
ESI: 源址变址寄存器。字符串形式的指针,也能做寄存器。
EDI: 目的变址寄存器。字符串形式的指针,也能做寄存器。
EBP: 机制指针寄存器。临时存储ESP,也能做寄存器。
ESP: 原址指针寄存器。堆栈种指向寄存器和地址。
EIP: 指令指针寄存器。
三.64 位寄存器
整数寄存器
RAX: 累加器。也能做寄存器
RBX: 空闲寄存器
RCX: 计数器。也能做寄存器
RDX: 数据寄存器。也能做寄存器。
R10:R11: 易失
R12:R15: 非易失
RSI: 源址变址寄存器。字符串形式的指针,也能做寄存器。
RDI: 目的变址寄存器。字符串形式的指针,也能做寄存器。
RBP: 机制指针寄存器。临时存储ESP,也能做寄存器。
RSP: 原址指针寄存器。堆栈种指向寄存器和地址。
RIP: 指令指针寄存器。
浮点数寄存器
xmm0:xmm15
2.指令
一.汇编常用指令
cmp
- cmp:**(cmp ax,bx)**的逻辑含义是比较 ax,bx 中的值。并且将逻辑比较的结果放入标志寄存器中。
- 解释: 简单来说,就是比较两个数。然后比较结果放入标志寄存器
jmp
- Jmp:****(jmp xxxx) 的逻辑含义是强制跳转到 xxxx 这个指令
- 解释: 简单来说,强行执行xxxx这个指令
- Jmp 变种:
- je/jz: 标志寄存器的标志的逻辑含义为相等,则强制跳转
- jne/jnz: 标志为不相等,则强制跳转
(注:接下来会出现符号的概念,一般游戏不会有负数,所以有符号可以不看)
ja: 无符号,其标志为大于,则跳转
jg: 有符号,其标志为大于,则跳转
jna: 无符号,其标志为不大于,则跳转
jng: 有符号,其标志为不大于,则跳转
jb: 无符号,其标志为小于,则跳转
jl: 有符号,其标志为小于,则跳转
jnb: 无符号,其标志为不小于,则跳转
jnl: 有符号,其标志为不小于,则跳转
jae: 无符号,其标志为大于等于,则跳转
jge: 有符号,其标志为大于等于,则跳转
jnae: 无符号,其标志为不大于等于,则跳转
jnge: 有符号,其标志为不大于等于,则跳转
例:
cmp [rbx+14],#1 |
先比较rbx+14这个地址的数值与1的大小,如果比较结果为大于,那么 ja originalcode 这行代码被执行,否则不被执行。
mov
-
Mov:
- (mov eax,ebx)把 ebx这个地址(注意不是地址的内容)移动到 eax(可以理解成 复制过去)
- **(mov eax,[ebx])**把ebx这个地址里面存放的内容复制到 eax这个地址所存放的内容(理解为赋值)
-
注意:[eax]就代表eax这个地址存放的内容
push & pop
- Push 与 pop 大部分情况下都需要搭配使用的
- 解释: push中文翻译为入栈,pop为出栈
- (那么你会问,什么是栈,把栈想象成一个叠叠乐,入栈就是把一个东西放在叠叠乐的最上面,出栈就是把这个东西从叠叠乐的最上面取出,假如不取出就成为叠叠乐的一部分,叠叠乐很可能会塌)
- (Push eax)与(pop eax)分别为入栈指令与出栈指令。
二.汇编指令大全
本小节内容可以跳过,需要的时候再查,源自x86,x87汇编指令大全
一、数据传输指令
它们在存贮器和寄存器、寄存器和输入输出端口之间传送数据.
- 通用数据传送指令
MOV 送字或字节.
MOVSX 先符号扩展,再传送.
MOVZX 先零扩展,再传送.
PUSH 把字压入堆栈.
POP 把字弹出堆栈.
PUSHA 把 AX,CX,DX,BX,SP,BP,SI,DI 依次压入堆栈.
POPA 把 DI,SI,BP,SP,BX,DX,CX,AX 依次弹出堆栈.
PUSHAD 把 EAX,ECX,EDX,EBX,ESP,EBP,ESI,EDI 依次压入堆栈.
POPAD 把 EDI,ESI,EBP,ESP,EBX,EDX,ECX,EAX 依次弹出堆栈.
BSWAP 交换32位寄存器里字节的顺序
XCHG 交换字或字节.(至少有一个操作数为寄存器,段寄存器不可作为操作数)
CMPXCHG 比较并交换操作数.(第二个操作数必须为累加器 AL/AX/EAX)
XADD 先交换再累加.(结果在第一个操作数里)
XLAT 字节查表转换.{BX 指向一张 256 字节的表的起点,AL 为表的索引值(0-255,即 0-FFH);返回 AL 为查表结果.([BX+AL]->AL) }
- 输入输出端口传送指令.
IN I/O 端口输入. ( 语法: IN 累加器, {端口号│DX} )
OUT I/O 端口输出. ( 语法: OUT {端口号│DX},累加器 )输入输出端口由立即方
式指定时,其范围是 0-255; 由寄存器 DX 指定时,其范围 0-65535.
- 目的地址传送指令.
LEA 装入有效地址.
例: LEA DX,string ;把偏移地址存到 DX.
LDS 传送目标指针,把指针内容装入 DS.
例: LDS SI,string ;把段地址:偏移地址存到 DS:SI.
LES 传送目标指针,把指针内容装入 ES.
例: LES DI,string ;把段地址:偏移地址存到 ES:DI.
LFS 传送目标指针,把指针内容装入 FS.
例: LFS DI,string ;把段地址:偏移地址存到 FS:DI.
LGS 传送目标指针,把指针内容装入 GS.
例: LGS DI,string ;把段地址:偏移地址存 到 GS:DI.
LSS 传送目标指针,把指针内容装入 SS.
例: LSS DI,string ;把段地址:偏移地址存到 SS:DI.
- 标志传送指令.
LAHF 标志寄存器传送,把标志装入AH.
SAHF 标志寄存器传送,把AH内容装入标志寄存器.
PUSHF 标志入栈.
POPF 标志出栈.
PUSHD 32 位标志入栈.
POPD 32 位标志出栈.
二、算术运算指令
ADD 加法.
ADC 带进位加法.
INC 加 1.
AAA 加法的 ASCII 码调整.
DAA 加法的十进制调整.
SUB 减法.
SBB 带借位减法.
DEC 减 1.
NEG 求反(以 0 减之).
CMP 比较.(两操作数作减法,仅修改标志位,不回送结果).
AAS 减法的 ASCII 码调整.
DAS 减法的十进制调整.
MUL 无符号乘法.结果回送 AH 和 AL(字节运算),或 DX 和 AX(字运算),
IMUL 整数乘法.结果回送 AH 和 AL(字节运算),或 DX 和 AX(字运算),
AAM 乘法的 ASCII 码调整.
DIV 无符号除法.结果回送:商回送 AL,余数回送 AH, (字节运算);或 商回送 AX,余数
回送 DX, (字运算).
IDIV 整数除法.结果回送:商回送 AL,余数回送 AH, (字节运算);或 商回送 AX,余数回
送 DX, (字运算).
AAD 除法的 ASCII 码调整.
CBW 字节转换为字. (把AL中字节的符号扩展到AH 中去)
CWD 字转换为双字. (把AX 中的字的符号扩展到DX中去)
CWDE 字转换为双字. (把 AX 中的字符号扩展到 EAX中去)
CDQ 双字扩展. (把 EAX 中的字的符号扩展到 EDX 中去)三、逻辑运算指令
AND 与运算.
OR 或运算.
XOR 异或运算.
NOT 取反.
TEST 测试.(两操作数作与运算,仅修改标志位,不回送结果).
SHL 逻辑左移.
SAL 算术左移.(=SHL)
SHR 逻辑右移.
SAR 算术右移.(=SHR)
ROL 循环左移.
ROR 循环右移.
RCL 通过进位的循环左移.
RCR 通过进位的循环右移.
以上八种移位指令,其移位次数可达255次.
移位一次时, 可直接用操作码. 如 SHL AX,1.
移位>1次时, 则由寄存器CL给出移位次数.
如 MOV CL,04 SHL AX,CL
四、串指令
DS:SI 源串段寄存器 :源串变址.
ES:DI 目标串段寄存器:目标串变址.
CX 重复次数计数器.
AL/AX 扫描值.
**D(**标志) 0表示重复操作中SI和DI应自动增量; 1表示应自动减量.
**Z(**标志) 用来控制扫描或比较操作的结束.
MOVS 串传送.( MOVSB 传送字符. MOVSW 传送字. MOVSD 传送双字. )
CMPS 串比较.( CMPSB 比较字符. CMPSW 比较字. )
SCAS 串扫描.把AL或AX的内容与目标串作比较,比较结果反映在标志位.
LODS 装入串.把源串中的元素(字或字节)逐一装入 AL 或 AX 中
.( LODSB 传送字符. LODSW 传送字. LODSD 传送双字. )
STOS 保存串.是 LODS 的逆过程.
REP 当 CX/ECX<>0 时重复.
REPE/REPZ 当 ZF=1 或比较结果相等,且 CX/ECX<>0 时重复.
REPNE/REPNZ 当 ZF=0 或比较结果不相等,且 CX/ECX<>0 时重复.
REPC 当 CF=1 且 CX/ECX<>0 时重复.
REPNC 当 CF=0 且 CX/ECX<>0 时重复.
五、程序转移指令
- 无条件转移指令 (长转移)**
JMP 无条件转移指令
CALL 过程调用
RET/RETF 过程返回.
- 条件转移指令 (短转移,-128到+127的距离内)( 当且仅当(SF XOR OF)=1时,OP1<OP2 )**
JA/JNBE 不小于或不等于时转移.
JAE/JNB 大于或等于转移.
JB/JNAE 小于转移.
JBE/JNA 小于或等于转移.
以上四条,测试无符号整数运算的结果(标志C 和Z).
JG/JNLE 大于转移.
JGE/JNL 大于或等于转移.
JL/JNGE 小于转移.
JLE/JNG 小于或等于转移.
以上四条,测试带符号整数运算的结果(标志S,O 和 Z).
JE/JZ 等于转移.
JNE/JNZ 不等于时转移.
JC 有进位时转移.
JNC 无进位时转移.
JNO 不溢出时转移.
JNP/JPO 奇偶性为奇数时转移.
JNS 符号位为 &34; 时转移.
JO 溢出转移.
JP/JPE 奇偶性为偶数时转移.
JS 符号位为 &34; 时转移.
- 循环控制指令(短转移)
LOOP CX 不为零时循环.
LOOPE/LOOPZ CX 不为零且标志 Z=1 时循环.
LOOPNE/LOOPNZ CX 不为零且标志 Z=0 时循环.
JCXZ CX 为零时转移.
JECXZ ECX 为零时转移.
- 中断指令
INT 中断指令
INTO 溢出中断
IRET 中断返回
- 处理器控制指令
HLT 处理器暂停, 直到出现中断或复位信号才继续.
WAIT 当芯片引线TEST 为高电平时使 CPU进入等待状态.
ESC 转换到外处理器.
LOCK 封锁总线.
NOP 空操作.
STC 置进位标志位.
CLC 清进位标志位.
CMC 进位标志取反.
STD 置方向标志位.
CLD 清方向标志位.
STI 置中断允许位.
CLI 清中断允许位.
六、伪指令
DW 定义字(2 字节).
PROC 定义过程.
ENDP 过程结束.
SEGMENT 定义段.
ASSUME 建立段寄存器寻址.
ENDS 段结束.
END 程序结束.
七、处理机控制指令:标志处理指令
CLC 进位位置 0指令
CMC 进位位求反指令
STC 进位位置为1指令
CLD 方向标志置1指令
STD 方向标志位置1指令
CLI 中断标志置0 指令
STI 中断标志置1 指令
NOP 无操作
HLT 停机
WAIT 等待
ESC 换码
LOCK 封锁
浮点运算指令集
一、控制指令(带 9B 的控制指令前缀 F 变为 FN时浮点不检查,机器码去掉 9B)
FINIT 初始化浮点部件 机器码 9B DB E3
FCLEX 清除异常 机器码 9B DB E2
FDISI 浮点检查禁止中断 机器码 9B DB E1
FENI 浮点检查禁止中断二 机器码 9B DB E0
WAIT 同步 CPU 和 FPU 机器码 9B
FWAIT 同步 CPU 和 FPU 机器码 D9 D0
FNOP 无操作 机器码 DA E9
FXCH 交换 ST(0)和 ST(1) 机器码 D9 C9
FXCH ST(i) 交换 ST(0)和 ST(i) 机器码 D9 C1iii
FSTSW ax 状态字到 ax 机器码 9B DF E0
FSTSW word ptr mem 状态字到 mem 机器码 9B DD mm111mmm
FLDCW word ptr mem mem 到状态字 机器码 D9 mm101mmm
FSTCW word ptr mem 控制字到 mem 机器码 9B D9 mm111mmm
FLDENV word ptr mem mem 到全环境 机器码 D9 mm100mmm
FSTENV word ptr mem 全环境到 mem 机器码 9B D9 mm110mmm
FRSTOR word ptr mem mem 到 FPU 状态 机器码 DD mm100mmm
FSAVE word ptr mem FPU 状态到 mem 机器码 9B DD mm110mmm
FFREE ST(i) 标志 ST(i)未使用 机器码 DD C0iii
FDECSTP 减少栈指针 1->0 2->1 机器码 D9 F6
FINCSTP 增加栈指针 0->1 1->2 机器码 D9 F7
FSETPM 浮点设置保护 机器码 DB E4
二、数据传送指令
FLDZ 将 0.0 装入 ST(0) 机器码 D9 EE
FLD1 将 1.0 装入 ST(0) 机器码 D9 E8
FLDPI 将 π 装入 ST(0) 机器码 D9 EB
FLDL2T 将 ln10/ln2 装入 ST(0) 机器码 D9 E9
FLDL2E 将 1/ln2 装入 ST(0) 机器码 D9 EA
FLDLG2 将 ln2/ln10 装入 ST(0) 机器码 D9 EC
FLDLN2 将 ln2 装入 ST(0) 机器码 D9 ED
FLD real4 ptrm em 装入 mem 的单精度浮点数 机器码 D9 mm000mmm
FLD real8p trm em 装入mem的双精度浮点数 机器码 DD mm000mmm
FLD real10p trm em 装入 mem 的十字节浮点数 机器码 DB mm101mmm
FILD word ptr mem 装入 mem 的二字节整数 机器码 DF mm000mmm
FILD dword ptr mem 装入 mem 的四字节整数 机器码 DB mm000mmm
FILD qword ptr mem 装入 mem 的八字节整数 机器码 DF mm101mmm
FBLD tbyte ptr mem 装入mem的十字节BCD数 机器码 DF mm100mmm
FST real4 ptr mem 保存单精度浮点数到mem 机器码 D9 mm010mmm
FST real8 ptr mem 保存双精度浮点数到 mem 机器码 DD mm010mmm
FIST word ptr mem 保存二字节整数到 mem 机器码 DF mm010mmm
FIST dword ptr mem 保存四字节整数到 mem 机器码 DB mm010mmm
FSTP real4 ptr mem 保存单精度浮点数到 mem 并出栈 机器码 D9 mm011mmm
FSTP real8 ptr mem 保存双精度浮点数到 mem 并出栈 机器码 DD mm011mmm
FSTP real10 ptr mem 保存十字节浮点数到 mem 并出栈 机器码 DB mm111mmm
FISTP word ptr mem 保存二字节整数到mem并出栈 机器码 DF mm011mmm
FISTP dword ptr mem 保存四字节整数到 mem 并出栈 机器码 DB mm011mmm
FISTP qword ptr mem 保存八字节整数到mem并出栈 机器码 DF mm111mmm
FBSTP tbyte ptr mem 保存十字节 BCD 数到 mem 并出栈 机器码 DF mm110mmm
FCMOVB ST(0),ST(i) <时传送 机器码 DA C0iii
FCMOVBE ST(0),ST(i) <=时传送 机器码 DA D0iii
FCMOVE ST(0),ST(i) =时传送 机器码 DA C1iii
FCMOVNB ST(0),ST(i) >=时传送 机器码 DB C0iii
FCMOVNBE ST(0),ST(i) >时传送 机器码 DB D0iii
FCMOVNE ST(0),ST(i) !=时传送 机器码 DB C1iii
FCMOVNU ST(0),ST(i) 有序时传送 机器码 DB D1iii
FCMOVU ST(0),ST(i) 无序时传送 机器码 DA D1iii
三、比较指令
FCOM ST(0)-ST(1) 机器码 D8 D1
FCOMI ST(0),ST(i) ST(0)-ST(1) 机器码 DB F0iii
FCOMIP ST(0),ST(i) ST(0)-ST(1)并出栈 机器码 DF F0iii
FCOM real4 ptr mem ST(0)-实数 mem 机器码 D8 mm010mmm
FCOM real8 ptr mem ST(0)-实数 mem 机器码 DC mm010mmm
FICOM word ptr mem ST(0)-整数 mem 机器码 DE mm010mmm
FICOM dword ptr mem ST(0)-整数 mem 机器码 DA mm010mmm
FICOMP word ptr mem ST(0)-整数 mem 并出栈 机器码 DE mm011mmm
FICOMP dword ptr mem ST(0)-整数 mem 并出栈 机器码 DA mm011mmm
FTST ST(0)-0 机器码 D9 E4
FUCOM ST(i) ST(0)-ST(i) 机器码 DD E0iii
FUCOMP ST(i) ST(0)-ST(i)并出栈 机器码 DD E1iii
FUCOMPP ST(0)-ST(1)并二次出栈 机器码 DA E9
FXAM ST(0)规格类型 机器码 D9 E5
四、运算指令
FADD 把目的操作数 (直接接在指令后的变量或堆栈缓存器) 与来源操作数 (接在目的操作数后的变量或堆栈缓存器) 相加,并将结果存入目的操作数
FADDP ST(i),ST 这个指令是使目的操作数加上 ST 缓存器,并弹出 ST 缓存器,而 目的操作数必须是堆栈缓存器的其中之一,最后不管目的操作数为何,经弹出一次后,目的操作数会变成上一个堆栈缓存器了
FIADD FIADD 是把 ST 加上来源操作数,然后再存入 ST 缓存器,来源操作数必须是字组整数或短整数形态的变数
FSUB 减
FSUBP
FSUBR 减数与被减数互换
FSUBRP
FISUB
FISUBR
FMUL 乘
FMULP
FIMUL
FDIV 除
FDIVP
FDIVR
FDIVRP
FIDIV
FIDIVR
FCHS 改变 ST 的正负值
FABS 把 ST 之值取出,取其绝对值后再存回去。
FSQRT 将 ST 之值取出,开根号后再存回去。
FSCALE 这个指令是计算 ST*2^ST(1)之值,再把结果存入 ST 里而 ST(1) 之值不变。ST(1) 必须是在 -32768 到 32768 (-215 到 215 )之间的整数,如果超过这个范围计算结果无法确定,如果不是整数 ST(1) 会先向零舍入成整数再计算。所以为安全起见,最好是由字组整数载入到 ST(1) 里。
FRNDINT 这个指令是把 ST 的数值舍入成整数,FPU 提供四种舍入方式,由 FPU 的控制字组(control word)中的 RC 两个位决定
RC 舍入控制
00 四舍五入
01 向负无限大舍入
10 向正无限大舍入
11 向零舍去
3.函数
ce的函数实在是不多,毕竟不是一款编程语言,但,我们还是有必要了解下
a. alloc
用法:alloc(xxx,2048)
解释: 自动划分一块大小为2048的内存,并命名为xxx
b. label
用法:label(xxx)
解释: 定义一个标签,这个标签可以包含需要的指令
alloc与 label 的区别:二者都可以理解为定义了一个标签,区别在于,alloc定义的标签 是可以放进内存空间的(也就是放进程序里执行),而label定义的标签,只是具有标签的含义,放不进内存空间里面,一般来说,alloc定义的标签里面可以放label以达到你想要的目的。(简单来说,标签相当于一段代码的缩写,用很短的代码表示很长的一段汇编指令)
c. registersymbol
用法:registersymbol(xxx)
解释: 为你分配的内存空间取一个可以全局调用的名称,这个名称除了在自动汇编这个
脚本内使用外,还能在类似于手动添加地址的外部操作中使用。
d. aobscan
用法:aobscan(xx,FF FF FF)
解释: 找到含义 FF FF FF 这段字节数组的汇编代码的地址,并将其赋值给 xx(此时 xx 就代表了哪一个地址)(注意,FF FF FF为特征码,我在后面的ct表会详细讲诉这个函数的具体用法)
e. dealloc
用法:dealloc(xxx)
解释: 释放之前 alloc 分配的内存
f. unregistersymbol(xxx)
用法:unregistersymbol(xxx)
解释: 解除定义的全局变量xxx.
g. [ENABLE]与[DISABLE]
用法:搭配使用
解释: 若脚本被激活,那么执行[ENABLE]下的代码;若脚本被取消激活,那么执行[DISABLE]下的所有代码
《Wireshark网络分析就这么简单》
- https://www.yuque.com/fragrantveget/iqit07/ozmptxh5fg7gbv7x#《基于《Wireshark网络分析就这么简单》一书对wireshark的学习》
- 基于天宇同志文章的笔记
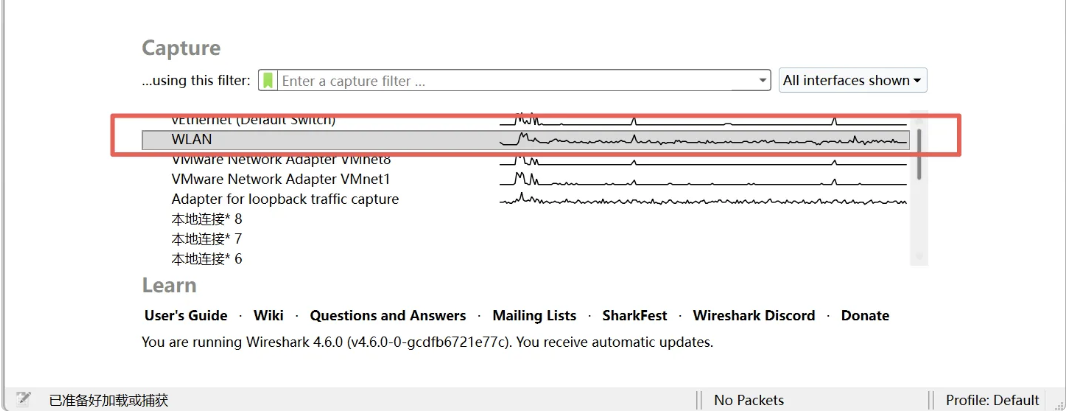
双击该网卡选项就会自动对本机进行流量抓包

问题:两台服务器A和B的网络配置如下,B的子网掩码本应该是255.255.255.0,被不小心配成了255.255.255.254,它们还能正常通信吗?
服务器A: |
- 服务器B ping服务器A的过程抓包
- 服务器B通过ARP广播查询默认网关192.168.26.2的MAC地址

- 为什么我ping的是服务器A的IP,B却去查询默认网关的MAC地址呢?
- 这是因为B根据自己的子网掩码计算出A属于不同子网,跨子网通信需要默认网关的转发,而要和默认网关通信,就需要获得其MAC地址
- 点击跳转子网掩码的知识点
- 默认网关192.168.26.2向B回复了自己的MAC地址
-
MAC地址的前3个字节标识厂商
-
00:50:56和00:0c:29都被分配给了Vmware公司(全球统一的标准)
-
后面找时间再看
https://blog.csdn.net/qq_34595352/article/details/111989105
https://www.yuque.com/fragrantveget/iqit07/ozmptxh5fg7gbv7x#《基于《Wireshark网络分析就这么简单》一书对wireshark的学习》
- 微信
- 支付宝



