
【备赛】2025警铮杯准备
比赛范围
以下是本次比赛的考核范围(仅供参考):
- Linux:选择题
- [x] 文字教程(从Linux简介到Linux vi/vim命令):https://www.runoob.com/linux/linux-file-content-manage.html
- [x] 视频教程(P1-P26):https://www.bilibili.com/video/BV1n84y1i7td
- Mysql:客观题+实操题
- [x] 文字教程(从Mysql安装到Mysql delete语句):https://www.runoob.com/mysql/mysql-administration.html
- [x] 视频教程( (P1-P26)):https://www.bilibili.com/video/BV1iF411z7Pu
- Python:客观题+实操题
- [x] 文字教程(第一章-第六章匿名函数):
https://blog.csdn.net/weixin_42399800/article/details/143822422 - [ ] 视频教程(第一阶段-第一章-01-初识Python——第一阶段-第九章-07-安装第三方包,第二阶段-第一章-01-初识对象——第二阶段-第一章-03-类和对象):
https://www.bilibili.com/video/BV1qW4y1a7fU
- 数字警务技术应用:
电子数据取证(理论题+实操题):电⼦数据取证基础知识、windows取证、⼿机取证、服务器取证、数据分析
网络安全与攻防(实操题):图片隐写,图片修复,stegsolve应用,压缩包密码爆破,压缩包伪加密,流量分析,osint社工,脚本编写,base家族编码,凯撒密码,栅栏密码,rsa,异或,exe程序逆向分析,exe程序脱壳
警务大数据(实操题):
- [ ] excel应用(数据清洗,数据分析)
网站开发(客观题):前后端语言用法,网站开发体系内容,二进制转换,全栈开发,网站开发与web服务器
学习笔记
Linux视频+文字教程
- 硬件、软件(操作系统)
- Linux系统的组成
- Linux系统内核:提供系统最核心的功能,如:调度CPU、调度内存、调度文件系统、调度网络通讯、调度IO等。
- 系统级应用程序:可以理解为出厂自带程序,可供用户快速上手操作系统,如:文件管理器、任务管理器、图片查看、音乐播放等。
- Linux系统发行版
- 内核无法被用户直接使用,需要配合应用程序才能被用户使用。
- 在内核之上,封装系统级应用程序,组合在一起就称之为Linux发行版。
kali ssh连接finalshell
- kali默认是禁用ssh 我们需要修改配置文件设置开机自启动。
- 输入:sudo -i (进入root管理员用户)
- 输入:vim /etc/ssh/sshd_config 回车 (编辑配置文件)
- 输入::set nu 回车(显示行数)
- 输入:按i键进入编辑模式找到第34行,将#去掉 后面变成yes(允许root用户登录)
- 找到第57行,将#去掉 后面变成yes(允许密码登录)
- 按Esc键退出编辑 输入:wq 保存文件
- 输入:systemctl start ssh (开启ssh服务)
- 设置开机自启:update-rc.d ssh enable
- 输入 systemctl status ssh
- 注意:正常命令行输入命令是sshd而不是ssh这里是特殊情况!!!
命令
用户相关
- 添加:
useradd 选项 用户名

- 删除:
userdel 选项 用户名-r:把用户的主目录一起删除。
- 修改:
usermod 选项 用户名 - 切换root
- 可以通过
su - root,并输入密码 - 通过输入exit命令,退回上一个账户,无需密码
- 可以通过
- 查看:
id 用户名 - 查看:
getentgetent passwd- 用户名:密码(x):用户ID:组ID:描述信息(无用):HOME目录:执行终端(默认bash)
getent group- 包含3份信息,组名称:组认证(显示为×):组ID
sudo- 为普通用户配置sudo认证
- root输入visudo打开/etc/sudoers
- 最后添加
iteima ALL=(ALL) NOPASSD: ALL - 但是失败了
passwd-l锁定口令,即禁用账号。-u口令解锁。-d使账号无口令。-f强迫用户下次登录时修改口令。
groupadd 选项 用户组-gGID 指定新用户组的组标识号(GID)-o一般与-g选项同时使用,表示新用户组的GID可以与系统已有用户组的GID相同。
groupdel 用户组groupmod 选项 用户组-gGID 为用户组指定新的组标识号。-o与-g选项同时使用,用户组的新GID可以与系统已有用户组的GID相同。-n新用户组,将用户组的名字改为新名字
实例1:
- 切换用户组
newgrp root
ls
- ls [-a -l -h] [way]
- 直接输入ls命令,表示列出当前工作自录下的内容
- 当前工作自录是:
- Linux系统的命令行终端,在启动的时候,默认会加载当前登录用户的HOME目录作为当前工作目录,所以ls命令列出的是HOME目录的内容
- HOME自录:每个Linux操作用户在Linux系统的个人账户自录,路径在:/home/用户名
-a选项:all的意思,即列出全部文件(包含隐藏的文件/文件夹)- 以.开头的,表示是Linux系统的隐藏文件/文件夹(只要以.开头,就能自动隐藏)
-l选项:竖向排列显示-h选项,需要和-l选项搭配使用,以更加人性化的方式显示文件的大小单位-la,-al,-l -a都可以
cd:change directory
- cd不带参数回用户根目录
pwd:print working directory
-p:显示出确实的路径,而非使用链接 (link) 路径。
特殊路径符:
.表示当前目录,比如cd./Desktop表示切换到当前目录下的Desktop目录内,和cd Desktop效果一致..表示上一级目录,比如:cd..即可切换到上一级目录,cd ../..切换到上二级的目录~表示HOME目录,比如:cd ~即可切换到HOME目录或cd~/Desktop,切换到HOME内的Desktop目录
mkdir:Make Directory【蓝色深色/d】
- 通过mkdir命令可以创建新的目录(文件夹)
-m:配置文件的权限喔!直接配置,不需要看默认权限 (umask) 的脸色~-p可选,表示自动创建不存在的父目录,适用于创建连续多层级的目录- 注意:创建文件夹需要修改权限,操作在HOME目录内默认有权限
rmdir (删除空的目录)
rmdir [-p] 目录名称-p:从该目录起,一次删除多级空目录
touch创建文件【浅色/- 】
可以通过touch命令创建文件语法:touchLinux路径
·touch命令无选项,参数必填,表示要创建的文件路径,相对、绝对、特殊路径符均可以使用
查看文件内容
cat/tac命令
- 可以通过cat命令查看文件的内容。
- -b :列出行号,仅针对非空白行做行号显示,空白行不标行号!
- -n :列印出行号,连同空白行也会有行号,与 -b 的选项不同;
- -v :列出一些看不出来的特殊字符
tac从最后一行开始显示,可以看出tac是cat的倒着写!
nl
nl -bnw 文件-b:指定行号指定的方式,主要有两种:-b a:表示不论是否为空行,也同样列出行号(类似 cat -n);-b t:如果有空行,空的那一行不要列出行号(默认值);
more命令
- more支持翻页
- 在查看的过程中,通过空格翻页,通过q退出查看
/字串:代表在这个显示的内容当中,向下搜寻『字串』这个关键字;:f:立刻显示出档名以及目前显示的行数;- b 或 [ctrl]-b :代表往回翻页,不过这动作只对文件有用,对管线无用。
less
- /字串 :向下搜寻『字串』的功能;
- ?字串 :向上搜寻『字串』的功能;
cp命令:copy
- cp命令可以用于复制文件\文件夹,cp命令来自英文单词:
cp [-r] 参数1 参数2-r选项,可选,用于复制文件夹使用,表示递归-i:若目标档(destination)已经存在时,在覆盖时会先询问动作的进行-p:连同文件的属性一起复制过去,而非使用默认属性(备份常用);- 参数1,Linux路径,表示被复制的文件或文件夹
- 参数2,Linux路径,表示要复制去的地方
rm:remove
- rm命令可用于删除文件、文件夹
rm [-r-f] 参数1 参数2 参数N-r选项用于删除文件夹-i:互动模式,在删除前会询问使用者是否动作-f表示force,强制删除(不会弹出提示确认信息)- 普通用户副除内容不会弹出提示,只有root管理员用户副除内容会有提示所以一般营通用户用不到-f选项
- 参数1、参数2、、参数N表示要除的文件或文件夹路径,按照空格隔开
mv:move
- mv命令可以用于移动文件\文件夹
- mv 参数1 参数2
- 参数1,Linux路径,表示被移动的文件或文件夹
- 参数2,Linux路径,表示要移动去的地方,如果目标不存在,则进行改名,确保目标存在
- rm命令支持通配符,用来做模糊匹配
which 命令名
- 输出命令文件位置
find 起始路径 -name “文件名”(可用通配符*)
- 按文件大小查找文件语法:
find 起始路径 -size +|-n[kMG]+、-表示大于和小于n表示大小数字- kMG表示大小单位,k(小写字母)表示kb,M表示MB,G表示GB
grep
- 从文件中通过关键字过滤文件
- grep [-n] 关键字 文件路径
- -n,可选,表示在结果中显示匹配的行的行号。
wc命令
- 统计文件的行数、单词数量等
wc [-c -m -l -w]文件路径- 直接使用就显示:行数,单词数,字节数,文件名
-c,统计bytes数量-m,统计字符数量-l,统计行数-w,统计单词数量
管道符 |
echo
- 带有空格或\等特殊符号,建议使用双引号包围
反引号 ``
- 包围内容作为命令执行
重定向符
- >,将左侧命令的结果,覆盖写入到符号右侧指定的文件中
- >>,将左侧命令的结果,追加写入到符号右侧指定的文件中
head/tail命令
head -n 20 文件路径- 默认显示前10行
tail [-f-num] Linux路径- -f,表示持续跟踪,ctrl+C强行终止
- -num,表示,查看尾部多少行,不填默认10行【-5,-10的意思不是-num字面意思】
vi vim:更多快捷键未看扔本地www了
- 命令/输入i/底线命令模式
- 使用:
vim 文件路径 - 底线命令模式:
:wq
| i | 切换到输入模式,在光标当前位置开始输入文本。 |
|---|---|
| x | 删除当前光标所在处的字符。 |
| : | 切换到底线命令模式,以在最底一行输入命令。 |
| a | 进入插入模式,在光标下一个位置开始输入文本。 |
| o | 在当前行的下方插入一个新行,并进入插入模式。 |
| O | 在当前行的上方插入一个新行,并进入插入模式。 |
| dd | 剪切当前行。 |
| yy | 复制当前行。 |
| p(小写) | 粘贴剪贴板内容到光标下方。 |
| P(大写) | 粘贴剪贴板内容到光标上方。 |
| u | 撤销上一次操作。 |
| Ctrl + r | 重做上一次撤销的操作。 |
| :w | 保存文件。 |
| :q | 退出 Vim 编辑器。 |
| :q! | 强制退出Vim 编辑器,不保存修改。 |
| :set nu | 显示行号 |
| :set paste | 设置粘贴模式 |
与用户账号有关的系统文件
- /etc/passwd文件是用户管理工作涉及的最重要的一个文件。
一行记录对应着一个用户,每行记录又被冒号(:)分隔为7个字段,其格式和具体含义如下:
用户名:口令:用户标识号:组标识号:注释性描述:主目录:登录Shell |
- 许多Linux 系统(如SVR4)都使用了shadow技术,把真正的加密后的用户口令字存放到/etc/shadow文件中,而在/etc/passwd文件的口令字段中只存放一个特殊的字符,例如“x”或者“*”。
- 通常用户标识号的取值范围是0~65 535。0是超级用户root的标识号,1~99由系统保留,作为管理账号,普通用户的标识号从100开始。在Linux系统中,这个界限是500。
- “组标识号”字段记录的是用户所属的用户组,它对应着/etc/group文件中的一条记录。
- Shell是用户与Linux系统之间的接口。Linux的Shell有许多种,每种都有不同的特点。常用的有sh(Bourne Shell), csh(C Shell), ksh(Korn Shell), tcsh(TENEX/TOPS-20 type C Shell), bash(Bourne Again Shell)等。系统管理员可以根据系统情况和用户习惯为用户指定某个Shell。如果不指定Shell,那么系统使用sh为默认的登录Shell,即这个字段的值为/bin/sh。
finalshell小技巧
- ctrl+L清屏幕
与比赛关系不大
Linux 磁盘管理
- 放桌面www文件夹里了
- 网页地址:https://www.runoob.com/linux/linux-filesystem.html
拥有帐户文件
1、除了上面列出的伪用户外,还有许多标准的伪用户,例如:audit, cron, mail, usenet等,它们也都各自为相关的进程和文件所需要。
- 由于/etc/passwd文件是所有用户都可读的,如果用户的密码太简单或规律比较明显的话,一台普通的计算机就能够很容易地将它破解,因此对安全性要求较高的Linux系统都把加密后的口令字分离出来,单独存放在一个文件中,这个文件是/etc/shadow文件。 有超级用户才拥有该文件读权限,这就保证了用户密码的安全性。
2、/etc/shadow中的记录行与/etc/passwd中的一一对应,它由pwconv命令根据/etc/passwd中的数据自动产生 - 它的文件格式与/etc/passwd类似,由若干个字段组成,字段之间用":"隔开。这些字段是:
登录名:加密口令:最后一次修改时间:最小时间间隔:最大时间间隔:警告时间:不活动时间:失效时间:标志 |
- "登录名"是与/etc/passwd文件中的登录名相一致的用户账号
- "口令"字段存放的是加密后的用户口令字,长度为13个字符。如果为空,则对应用户没有口令,登录时不需要口令;如果含有不属于集合 { ./0-9A-Za-z }中的字符,则对应的用户不能登录。
- "最后一次修改时间"表示的是从某个时刻起,到用户最后一次修改口令时的天数。时间起点对不同的系统可能不一样。例如在SCO Linux 中,这个时间起点是1970年1月1日。
- "最小时间间隔"指的是两次修改口令之间所需的最小天数。
- "最大时间间隔"指的是口令保持有效的最大天数。
- "警告时间"字段表示的是从系统开始警告用户到用户密码正式失效之间的天数。
- "不活动时间"表示的是用户没有登录活动但账号仍能保持有效的最大天数。
- "失效时间"字段给出的是一个绝对的天数,如果使用了这个字段,那么就给出相应账号的生存期。期满后,该账号就不再是一个合法的账号,也就不能再用来登录了。
下面是/etc/shadow的一个例子:
# cat /etc/shadow |
3、用户组的所有信息都存放在/etc/group文件中。
- 将用户分组是Linux 系统中对用户进行管理及控制访问权限的一种手段。
- 每个用户都属于某个用户组;一个组中可以有多个用户,一个用户也可以属于不同的组。
- 当一个用户同时是多个组中的成员时,在/etc/passwd文件中记录的是用户所属的主组,也就是登录时所属的默认组,而其他组称为附加组。
- 用户要访问属于附加组的文件时,必须首先使用newgrp命令使自己成为所要访问的组中的成员。
- 用户组的所有信息都存放在/etc/group文件中。此文件的格式也类似于/etc/passwd文件,由冒号(:)隔开若干个字段,这些字段有:
组名:口令:组标识号:组内用户列表 |
- "组名"是用户组的名称,由字母或数字构成。与/etc/passwd中的登录名一样,组名不应重复。
- "口令"字段存放的是用户组加密后的口令字。一般Linux 系统的用户组都没有口令,即这个字段一般为空,或者是*。
- "组标识号"与用户标识号类似,也是一个整数,被系统内部用来标识组。
- "组内用户列表"是属于这个组的所有用户的列表,不同用户之间用逗号(,)分隔。这个用户组可能是用户的主组,也可能是附加组。
/etc/group文件的一个例子如下:
root::0:root |
四、添加批量用户
- 添加和删除用户对每位Linux系统管理员都是轻而易举的事,比较棘手的是如果要添加几十个、上百个甚至上千个用户时,我们不太可能还使用useradd一个一个地添加,必然要找一种简便的创建大量用户的方法。Linux系统提供了创建大量用户的工具,可以让您立即创建大量用户,方法如下:
(1)先编辑一个文本用户文件。 - 每一列按照/etc/passwd密码文件的格式书写,要注意每个用户的用户名、UID、宿主目录都不可以相同,其中密码栏可以留做空白或输入x号。一个范例文件user.txt内容如下:
user001::600:100:user:/home/user001:/bin/bash |
(2)以root身份执行命令 /usr/sbin/newusers,从刚创建的用户文件user.txt中导入数据,创建用户:
# newusers < user.txt |
- 然后可以执行命令 vipw 或 vi /etc/passwd 检查 /etc/passwd 文件是否已经出现这些用户的数据,并且用户的宿主目录是否已经创建。
(3)执行命令/usr/sbin/pwunconv。 - 将 /etc/shadow 产生的 shadow 密码解码,然后回写到 /etc/passwd 中,并将/etc/shadow的shadow密码栏删掉。这是为了方便下一步的密码转换工作,即先取消 shadow password 功能。
# pwunconv |
(4)编辑每个用户的密码对照文件。
- 格式为:
用户名:密码 |
- 实例文件 passwd.txt 内容如下:
user001:123456 |
(5)以 root 身份执行命令 /usr/sbin/chpasswd。
创建用户密码,chpasswd 会将经过 /usr/bin/passwd 命令编码过的密码写入 /etc/passwd 的密码栏。
# chpasswd < passwd.txt |
(6)确定密码经编码写入/etc/passwd的密码栏后。
执行命令 /usr/sbin/pwconv 将密码编码为 shadow password,并将结果写入 /etc/shadow。
# pwconv |
- 这样就完成了大量用户的创建了,之后您可以到/home下检查这些用户宿主目录的权限设置是否都正确,并登录验证用户密码是否正确。
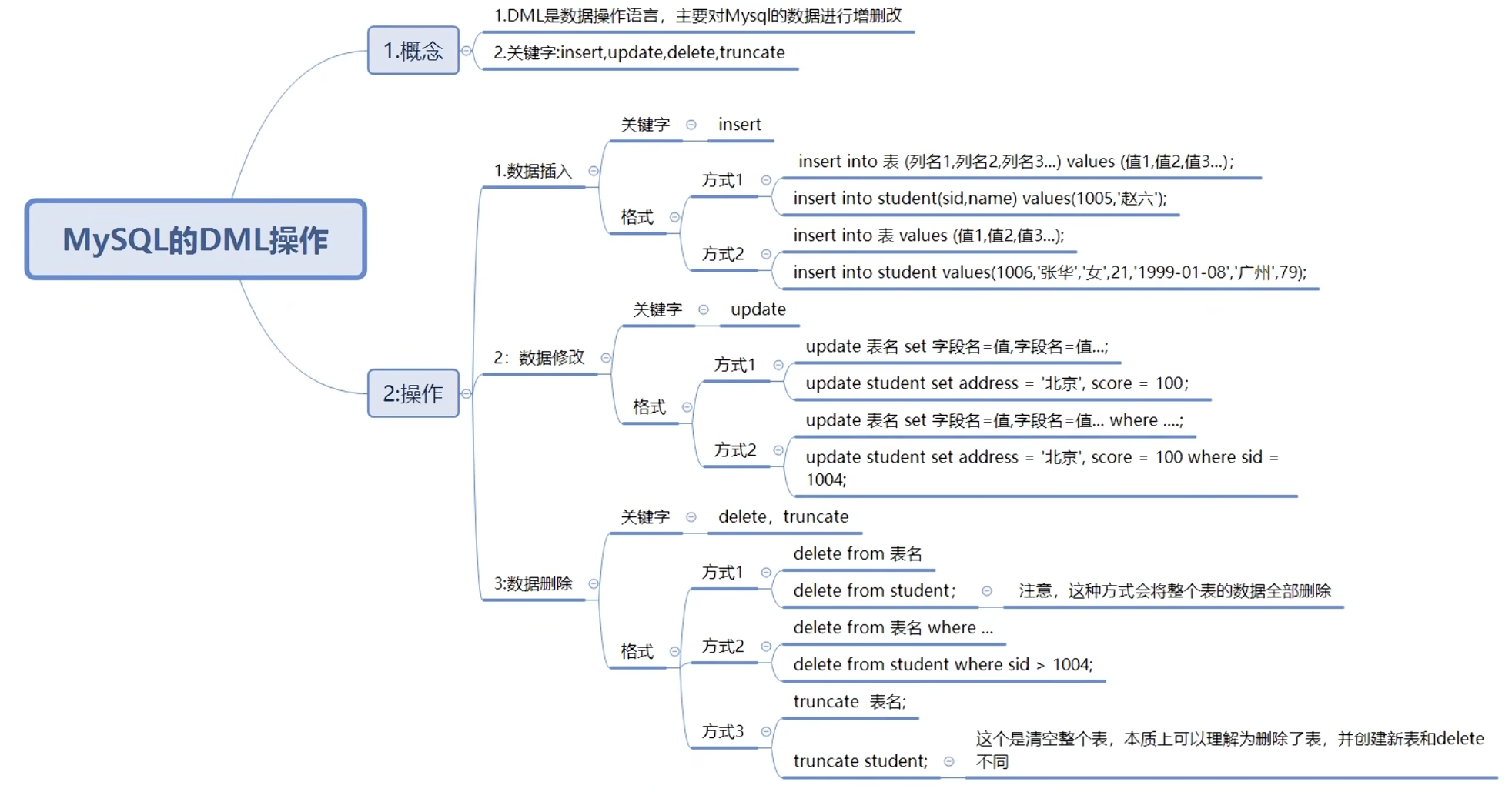
MySQL
安装——小皮面板
mysql -u root -p登录,密码默认为root
MySQL视频教程
- 计算机语言概述
计算机语言(programminglanguage)可以简单的理解为一种计算机和人都能识别的语言。- 机器语言、汇编语言、高级语言
- SQL的概述
- SQL全称:StructuredQuery,Language,是结构化查询语言,用于访问和处理数据库的标准的计算机语言。
- 非过程化语言,与其他语言可以结合
- 对大小写不敏感,以;结尾
- 注释方式
--#/**/
- 数据库分类
- 关系型数据库(RDBMS)
- Oracle数据库(老大,最挣钱的数据库)
- MySQL数据库(最流行中型数据库)
- SQLserver数据库(Windows上最好的数据库)
- PostgreSQL(功能最强大的开源数据库)
- SQLite(最流行的嵌入式数据库)
- 非关系型数据库(NoSQL)
- Redis(最好的缓存数据库)
- MongoDB(最好的文档型数据库)
- Elasticsearch(最好的搜索服务)
- Cassandra(最好的列式数据库)
- HBase(优秀的分布式、列式数据库)
- 关系型数据库(RDBMS)
- alpha是测试版本
- 数据类型
- 暂时跳过,本地保存www文件夹:MySQL 数据类型 _ 菜鸟教程.html
- DDL数据定义语言
- 查看show databases;
- 创建create [if not exists] database;
- CREATE DATABASE [IF NOT EXISTS] database_name
[CHARACTER SET charset_name]
[COLLATE collation_name];
- CREATE DATABASE [IF NOT EXISTS] database_name
- 切换use database;
- 删除drop database [if exists] database;
- 修改编码alter database mydb1 character set uft8;
- 插入
- INSERT INTO users (username, email, birthdate, is_active)
VALUES (‘test’, ‘test@runoob.com’, ‘1990-01-01’, true);
- INSERT INTO users (username, email, birthdate, is_active)
- 创建表
use mydb1; |
MySQL文字教程
- 优先级:
- 关联条件 > where
- 指定主机和端口连接(适用于远程连接):
mysql -h 主机名或IP地址 -P 端口号 -u 用户名 -p - 选择数据库:
USE database_name; - where
- AND OR LIKE模糊匹配 IN NOT BETWEEN /IS NULL/IS NOT NULL
- LIKE子句中使用百分号%字符来表示任意字符
- MySQL 的 WHERE 子句的字符串比较是不区分大小写的。 你可以使用 BINARY 关键字来设定 WHERE 子句的字符串比较是区分大小写的
SELECT column1, column2, ... |
- UNION
- 使用 UNION ALL 不去除重复行
- ORDER BY(排序) 语句可以按照一个或多个列的值进行升序(ASC默认)或降序(DESC)排序
ORDER BY department_id ASC, hire_date DESC;
- 按第三列(salary)降序 DESC 排序,然后按第一列(first_name)升序 ASC 排序。
- 从 MySQL 8.0.16 版本开始,可以使用 NULLS FIRST 或 NULLS LAST 处理 NULL 值
ORDER BY price DESC NULLS LAST;
ORDER BY price DESC NULLS FIRST; - QROUP BY
SELECT customer_id, SUM(order_amount) AS total_amount |
select coalesce(a,b,c)
参数说明:如果 anull,则选择 b;如果 bnull,则选择 c;如果 a!=null,则选择 a;如果 a b c 都为 null ,则返回为 null(没意义)。
SELECT coalesce(name, '总数'), |
- 连接
- INNER JOIN:返回两个表中满足连接条件的匹配行
SELECT column1, column2, ...
FROM table1
INNER JOIN table2 ON table1.column_name = table2.column_name;
--使用表别名
SELECT o.order_id, c.customer_name
FROM orders AS o
INNER JOIN customers AS c ON o.customer_id = c.customer_id;
-- 多表 INNER JOIN
SELECT orders.order_id, customers.customer_name, products.product_name
FROM orders
INNER JOIN customers ON orders.customer_id = customers.customer_id
INNER JOIN order_items ON orders.order_id = order_items.order_id
INNER JOIN products ON order_items.product_id = products.product_id;
-- 使用 WHERE 子句进行过滤
SELECT orders.order_id, customers.customer_name
FROM orders
INNER JOIN customers ON orders.customer_id = customers.customer_id
WHERE orders.order_date >= '2023-01-01';- LEFT JOIN:返回左表的所有行,并包括右表中匹配的行,如果右表中没有匹配的行,将返回NULL值
SELECT customers.customer_id, customers.customer_name, orders.order_id
FROM customers
LEFT JOIN orders ON customers.customer_id = orders.customer_id;
-- 使用表别名
SELECT c.customer_id, c.customer_name, o.order_id
FROM customers AS c
LEFT JOIN orders AS o ON c.customer_id = o.customer_id;
-- 多表 LEFT JOIN:
SELECT customers.customer_id, customers.customer_name, orders.order_id, products.product_name
FROM customers
LEFT JOIN orders ON customers.customer_id = orders.customer_id
LEFT JOIN order_items ON orders.order_id = order_items.order_id
LEFT JOIN products ON order_items.product_id = products.product_id;
-- 使用 WHERE 子句进行过滤:
SELECT customers.customer_id, customers.customer_name, orders.order_id
FROM customers
LEFT JOIN orders ON customers.customer_id = orders.customer_id
WHERE orders.order_date >= '2023-01-01' OR orders.order_id IS NULL;- RIGHT JOIN
- 不小心看多了。。。看到连接了
python文字教程
注释
- 快捷键:ctrl+/
- 如果需要撤销注释,选择注释行,按 ctrl+/ 将撤销注释。
数据类型
列表list[]:可变,有序,可重复
- .append()/.remove()/[number]
元组tuple():不可变,有序,可重复
集合set:无序,不可重复
字典{}
- 键必须为不可变数据类型;即字符串、整数、浮点数等,不能为列表
- 添加或更新键值对的方法:字典名[“键”] = “值”
- 判断键是否存在字典里面:“键” in 字典名
- 删除键与对应的值:del 字典名[“键”],如果键不存在,指令会报错。
- 返回字典的键、值、键值对的方法:.keys()/.values()/.items()
格式化字符串
-
format
"{0}{1}".format(one,two)输出onetwo"{one}{two}".format(one=one1,two=two1)输出one1twoo1
-
f:引用已定义的字符串变量。
name="老林" year ="虎"
message_content = f'''
律回春渐,新元肇启。
新岁甫至,福气东来。
金{year}贺岁,欢乐祥瑞。
金{year}敲门,五福临门。
给{name}及家人拜年啦!
新春快乐,{year}年大吉!
'''- 冒号+点+数字+f 来指定浮点数在格式化是保留几位小数
- 例子:
name = 1
gpa = 2
print(f"{0}你好,你的当前绩点为:{1:.2f}".format(name,gpa))
-
%:‘%s,%s’ % (name,name1)
- %d整数,%f浮点数
- %5d:表示将整数的宽度控制在5位,如数字11,被设置为5d,就会变成:[空格][空格][空格]11,用三个空格补足宽度。
- 小数点和小数部分也算入宽度计算
类
- 定义
class 类名: # 类的构造函数,主要作用是定义实例对象的属性,__init__是固定项 |
- 在子类A名称后的括号中写上父类B的名称,此时父类的方法就会继承到子类中
class A(B): |
- 如果子类程序中有__init__方法,则创建子类实例时优先调用子类的构造函数,导致实例只有子类的__init__中的属性参数,而父类的__init__属性参数不会被调用。
Python文件操作
open
f = open("./data.txt", "r", encoding="utf-8") # 默认r还有w模式 |
read()
- 运行read()方法会一次性读取文件里面的所有内容,并以字符串的形式返回。一般操作的文件以文本为主。其他类似word文件内有字体颜色、字号区分的文件,很可能读取有误。
- 运行read()方法后,再次调用时返回的结果为空,因为程序会记录文件读取到哪个位置,第一次运行read()时已经读到结尾,第二次运行时后面已经没有内容。
- 文件太大时不建议使用read()方法,因为读出来的内容会占用很大的内存。如果不需要一次性读取整个文件,可以在read()传一个数字,表示读多少个字节,下次调用read时会从上次结束位置继续往下读。
readline()
- 只读取文件一行内容,下次调用时继续读取下一行,根据换行符来判断什么时候结束本行。并且换行符会被当成读到的内容的一部分。读取到结尾后,继续读取将会返回空字符串,表示后面已经无内容。
f = open("./data.txt", "r", encoding="utf-8") |
readlines()
- 读取文件内容,并将每行作为列表元素返回。
f = open("./data.txt","r",encoding="utf-8") |
close()关闭文件
- 调用close方法后将会释放系统资源,每次调用文件完成后都应该关闭文件。
f = open("./data.txt") |
with open("./data.txt") as f: |
- 如上方式可以不用调用close方法关闭文件,文件操作完成后会自动关闭文件。注意对文件操作的代码需要缩进,缩进的代码块执行完毕后会自动关闭文件
open
with open("./data.txt","w", encoding="utf-8") as f: |
- open的第二个参数传入w,即为写文件模式,写文件模式找不到文件,不会像读文件模式那样报错,而是自动创建传入文件名的那个文件。第三个参数为encoding编码格式。
- 注:使用w模式打开文件进行写入时,如果文件已存在,将会把原有文件内容全部清空。
- 增加文件内容,则open()的第二个参数需要传入附加模式“a”参数
- 无论是"w"模式,还是"a"模式,都不能读取文件原本的内容,如果在这两个模式下调用read()方法,程序会报错不支持读操作(UnsupporttedOperation)。
- r+,同时支持读写文件
- open()方法的第二个参数传入”r+”参数,就可以同时支持读写文件
Python异常处理
- 需要注意的是,try/except语句在捕捉错误时,依次从上往下运行,如果第一个except已经捕捉到错误,之后的except将不会执行,与if/elif语句类似,只有第一个符合条件的分支会运行。
try: |
- else: 表示没有出现任何错误时执行的语句。
- finally: 无论是否发生错误,都会执行的语句。
Python测试
- assert 断言
- assert后面可以跟上任何布尔表达式,在assert后面跟上我们认为为True的表达式,如果assert后面的表达式最终求出来为True,则正常结束,继续运行后面的代码。如果求出来的结果为False,则会产生“AssertionError”断言错误。
unittest
- 自带库,需要import导入
- 测试方法命名必须以 test_ 开头。因为 unittest 库只把 test_ 开头的方法当作测试用例
- 没看懂测试这一块,后面再看
高阶函数(函数名作为变量)/匿名函数lambda变量:输出内容
python视频教程
- 太慢了,不看了
零碎
- pass 在Python中是一个空语句,什么都不做,占位语句
- range的第三个参数为步长,不指明的时候默认为1
- 函数运行完成后,没有写返回值,默认返回值为 None。
- from后面添加模块名,import后面添加函数名或变量名,需要引入多个的时候用逗号进行分隔,此方法在使用时不需要再带上模块名。
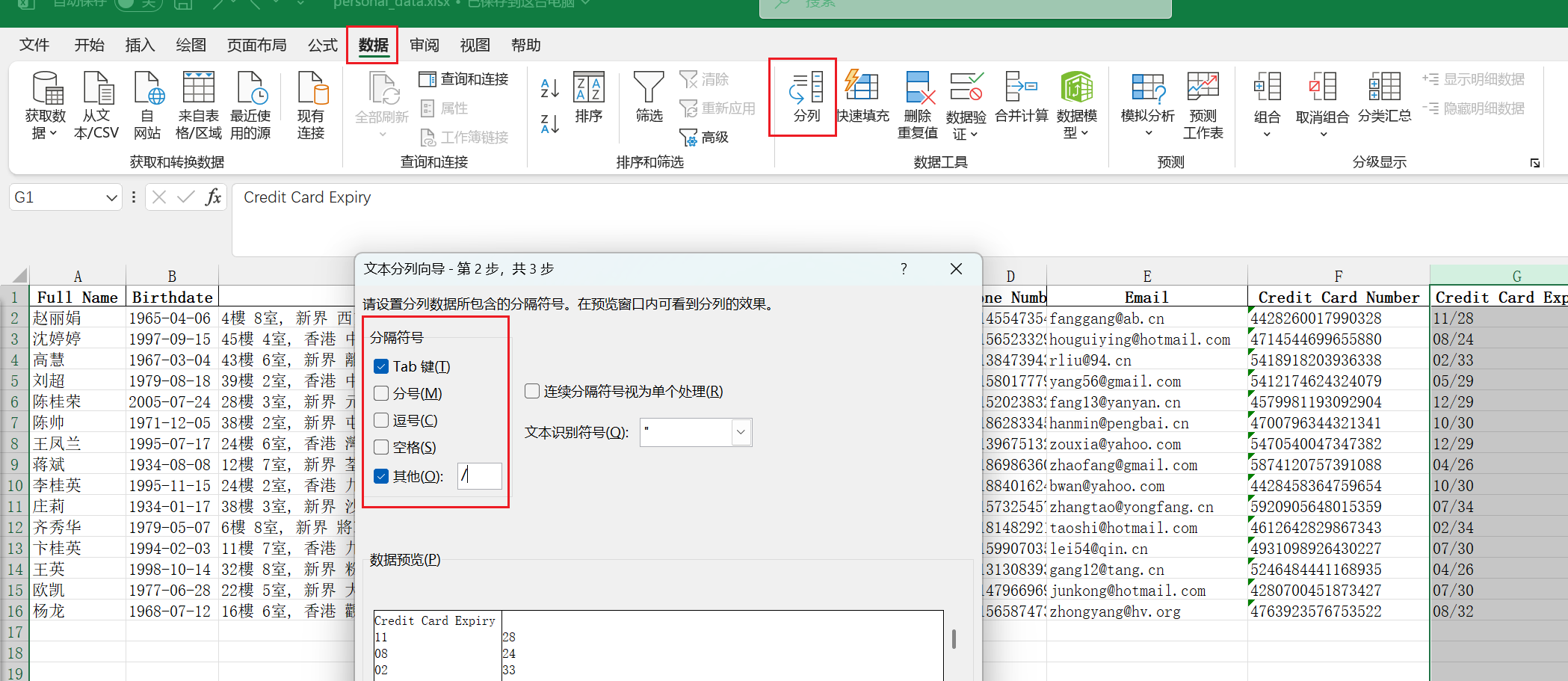
excel
- 分列
函数
- SUM(A1:A3)
- SUM(A1,A2,A3)
- 单条件求和sumif
- =SUMilF(range,criteria,sum_range)
- Range为条件区域,用于条件判断的单元格区域。
- Criteria是求和条件,由数字、逻辑表达式等组成的判定条件。
- Sum_range为实际求和区域,需要求和的单元格、区域或引用。
- eg:=SUMIF(A15:A25,“橡皮擦’,B15:B25)
- 多条件求和sumifs
题目
misc-base换表
import base64 |
模拟赛
1.1
1.1.2 多选题
-
以下哪个语句可以删除字典中的一个键值对?
A.del dict['key']
B.dict.remove('key')
C.dict.pop('key')
D.dict.clear()答案:ACD
**解析:**python的字典没有remove方法 -
以下关于 Python 异常处理的说法,正确的是?( )
A. 可以使用try - except块来捕获和处理异常
B. 可以有多个except块来捕获不同类型的异常
C. 还可以使用finally块,无论是否发生异常,finally块中的代码都会执行
D. 异常处理可以提高程序的健壮性,避免程序因为异常而崩溃答案:ABCD
**解析:**在 Python 中,try - except是基本的异常处理结构,try块中放置可能会出现异常的代码,except块用于捕获和处理异常。可以有多个except块,每个except块针对不同类型的异常进行处理。finally块是可选的,不管try块中是否发生异常,finally块中的代码都会执行,通常用于清理资源等操作。通过合理的异常处理,可以让程序在遇到异常情况时能够进行适当的处理,而不是直接崩溃,从而提高程序的健壮性。
1.1.3 判断题
for循环中的else子句,当for循环正常执行完(没有被break中断)后会执行,若for循环因为break跳出则else子句不会执行。
答案:错误
**解析:**建议写个代码运行试试。
1.1.4 实操题
1.1.4.2 文件操作与数据分析
题目描述:
假设你有一个名为data.txt的文本文件,其中包含了多行数据,每行数据都是一个由逗号分隔的数值列表。例如:
1,2,3,4,5 |
编写一个Python程序,完成以下任务:
- 读取文件
data.txt中的所有数据。 - 将每行数据转换为一个整数列表。
- 计算所有数值的总和和平均值。
- 找出最大值和最小值。
- 将结果输出到控制台。
实现过程:
- 使用文件操作函数来读取文件内容。
- 使用字符串的
split方法来分割每行数据。 - 使用列表和循环来处理数据。
- 使用内置的数学函数来计算总和、平均值、最大值和最小值。
代码框架:
filename = 'data.txt' |
答案:
filename = 'data.txt' |
1.2 Mysql
-
在MySQL中,如何删除表中的记录?(A)
A.DELETE FROM table_name WHERE condition; -
下列哪个命令用于删除数据库?(B)
B.DROP DATABASE database_name; -
在MySQL中,如果你想要创建一个列,该列可以存储任意长度的文本数据,并且不允许为空,你应该使用哪种数据类型和约束?(B)
B.TEXT NOT NULL -
在MySQL中,如何创建一个包含自增主键的表?(A)
A.CREATE TABLE table_name (id INT AUTO_INCREMENT, name VARCHAR(100), PRIMARY KEY (id));
1.3 Linux
1.3.1 单选题
-
Linux中,用于实时查找文件的命令是?
A.find
B.grep
C.locate
D.which答案: A
解析:find命令用于在指定目录中查找文件。虽然locate也可以查找文件,但它是基于预先构建的数据库,而find是实时搜索。 -
在 Linux 中,要将一个文件的拥有者改为
user1,应该使用以下哪个命令?A.
chown user1 file.txt答案:A
解析:
chmod命令是用于改变文件或目录的权限,usermod主要用于修改用户账户的属性,groupmod用于修改用户组的属性。而chown命令是用于改变文件的所有者,chown user1 file.txt会将file.txt的所有者改为user1。 -
在 Linux 中,以下哪个命令用于创建新用户?
A.
useradd答案:A
-
在 Linux 系统中,要将命令的输出追加到一个文件中,应该使用以下哪个符号?
B.>>答案:B
解析:
>符号是将命令的输出重定向到一个文件,如果文件存在则覆盖其内容。>>符号是将命令的输出追加到一个文件的末尾。<是用于输入重定向,<<用于这里文档(将一段文本作为输入传递给命令),所以答案是 B。 -
以下关于 Linux 文件系统的说法,错误的是?
D. 一个分区只能挂载一个文件系统,一个文件系统也只能挂载在一个分区上
答案:D
**解析:**Linux 文件系统是树形结构,从根目录
/开始构建层次。不同的 Linux 发行版可以使用如 ext4、XFS 等不同的文件系统类型。挂载点必须是一个已经存在的目录,这样才能将文件系统挂载到该目录下。但是一个分区通常挂载一个文件系统,但一个文件系统可以挂载在多个分区上,例如通过软连接等方式,所以 D 选项错误。
2.3 网络安全与攻防
2.3.1 misc部分
-
校徽: 这校徽的颜色对吗?分辨一下!!!
答案:flag{just_a_cqpc_logo}
解析:
-
Tom: tom把flag藏哪儿了? 3分
答案:flag{8565-hs12-a968s-6dhj54-g5jk5}
解析:-
flag1
binwalk检测有两段zlib信息,无第二文件头尾信息
找png数据块IDATX
找到第二段有明显sRGB标识,确定公用文件头尾,删除表层图片数据部分,得flag1
还要改宽高!!!! -
flag2
文件尾明显base64数据,解密得到第二段flag
-
-
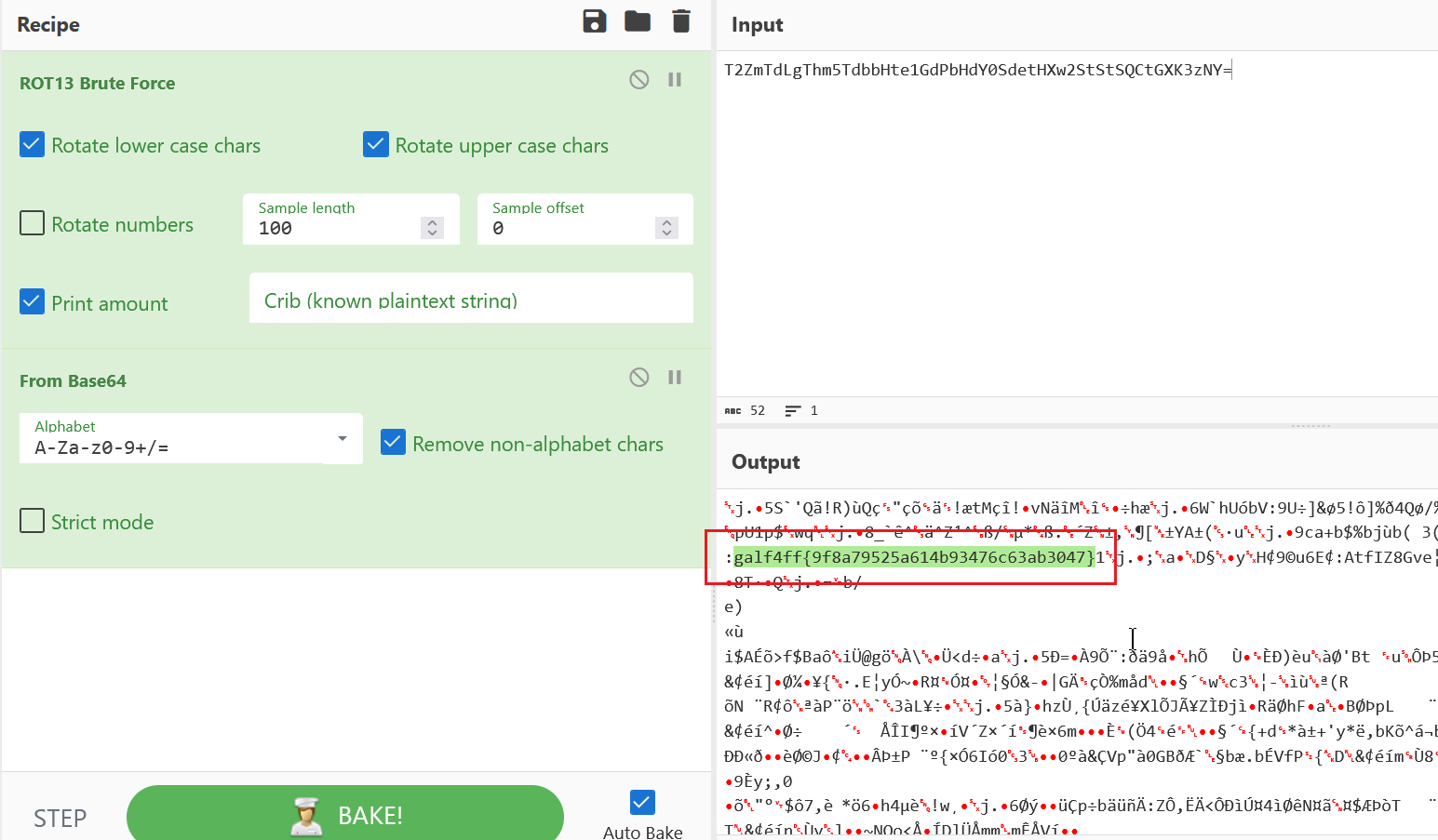
编码:这是什么编码,你能看出来吗?好像不止一种!!! 3分
答案:flag{ff4a8f9259716a539b4c674ba3674031}
**解析:**rot13爆破+base64;然后转换端序
端序转换
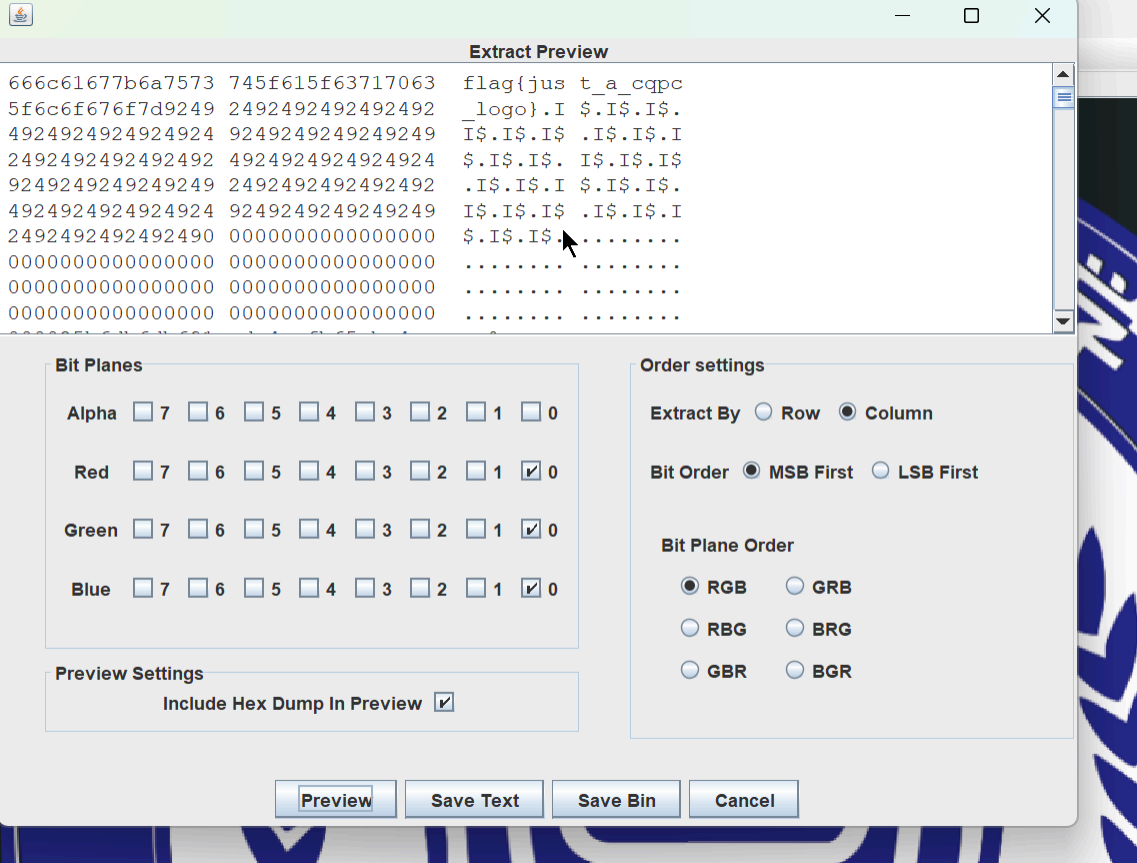

 找到第二段有明显sRGB标识,确定公用文件头尾,删除表层图片数据部分,得flag1
找到第二段有明显sRGB标识,确定公用文件头尾,删除表层图片数据部分,得flag1

def swap_groups(b, w): |
-
流量1:简单流量,签个到吧…
答案:flag{do_you_know_NaiLong} -
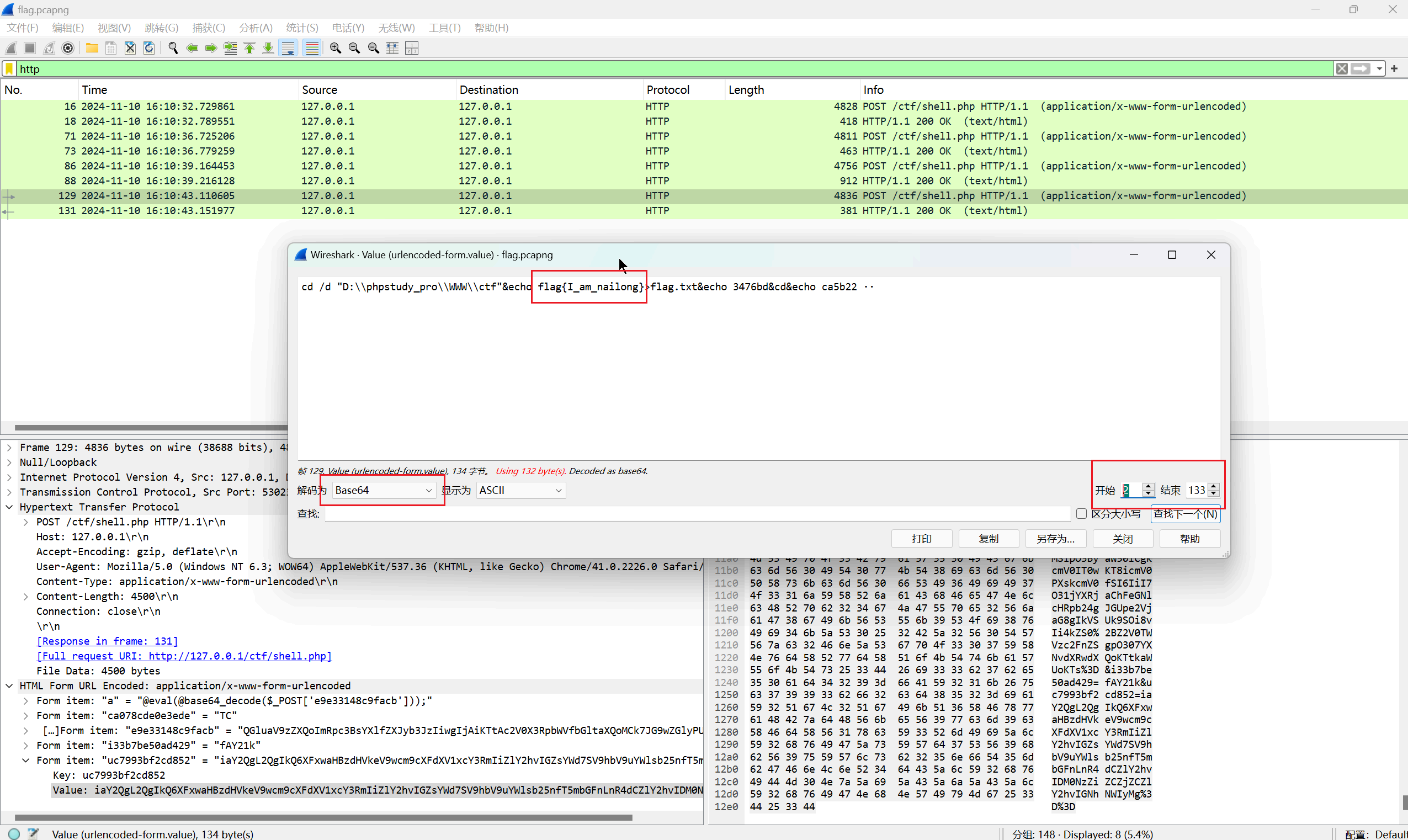
流量2: 是谁连接了shell,他干了什么!!!
答案:flag{I_am_nailong}解析:
复现不出来,选最后一个From item后ctrl+shift+o 查看分组字节流,base解码可以得到 -
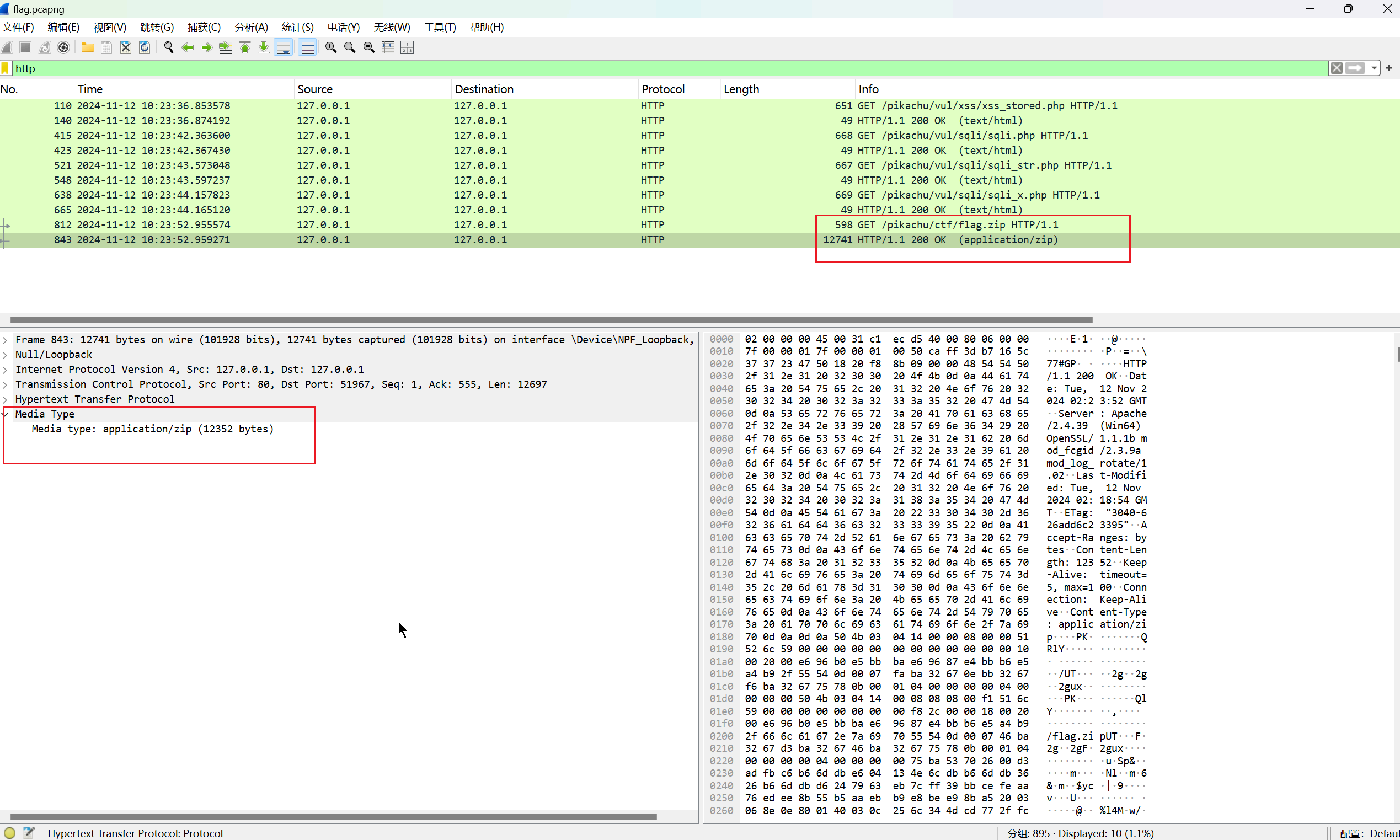
流量3:好像下载了什么东西??? 3分
答案:flag{I_have_learnt_wareshark!!!}
解析:- 打开流量包,发现下载了一个flag.zip, 把它分离出来;得到flag.zip
- 第二步:
- 第三步:
- 打开流量包,发现下载了一个flag.zip, 把它分离出来;得到flag.zip
-
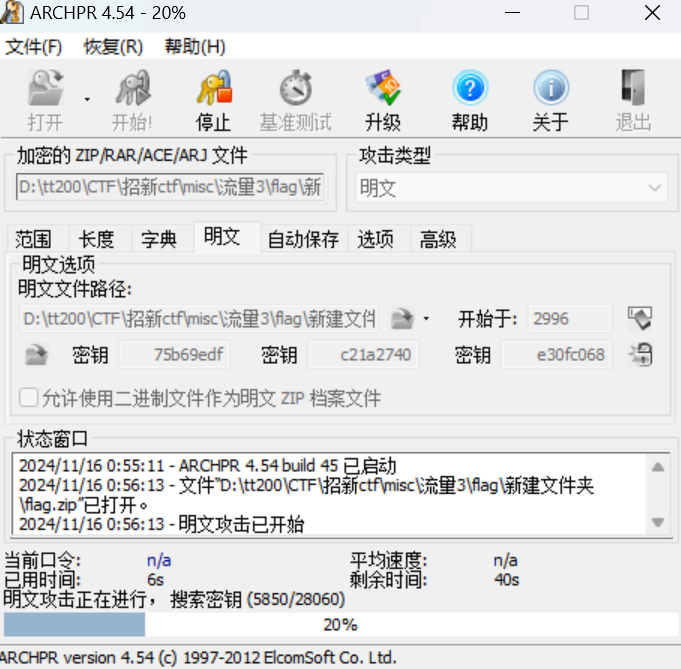
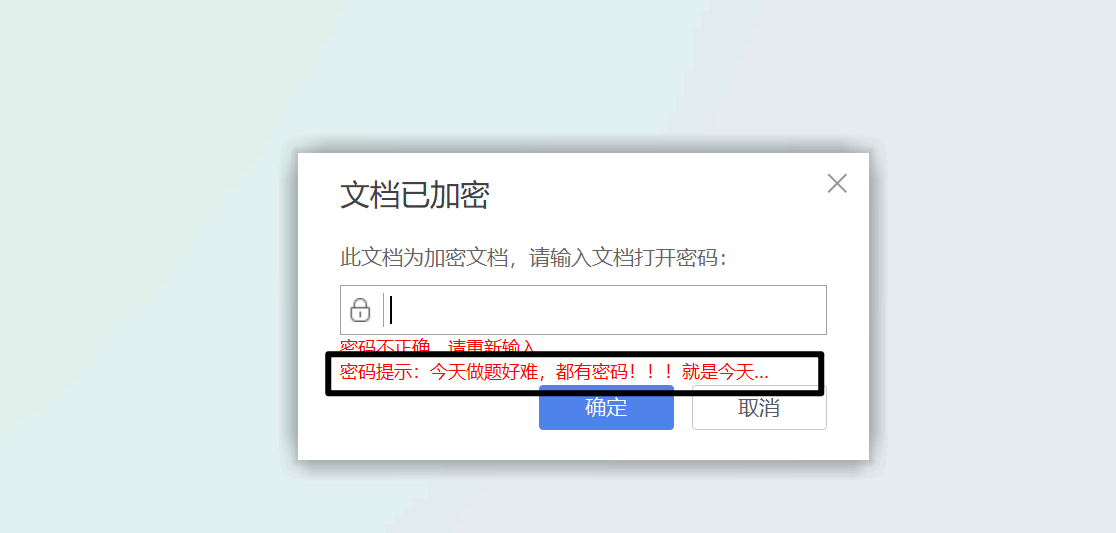
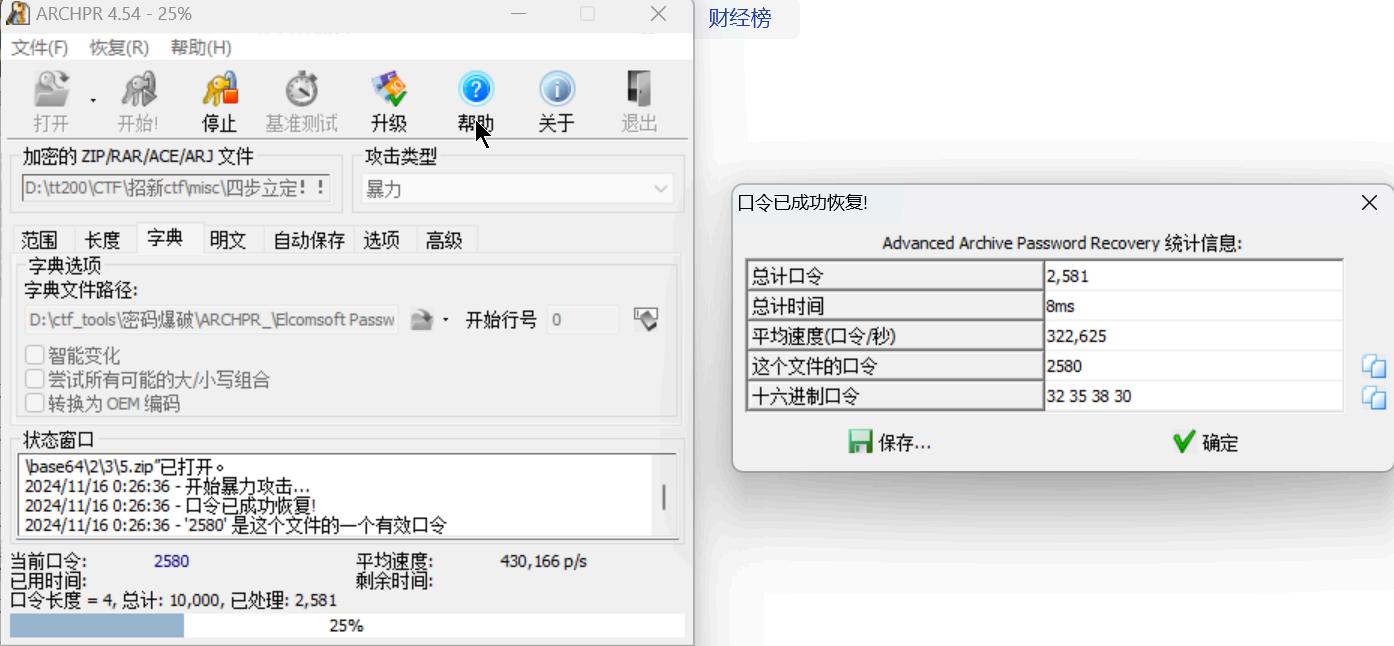
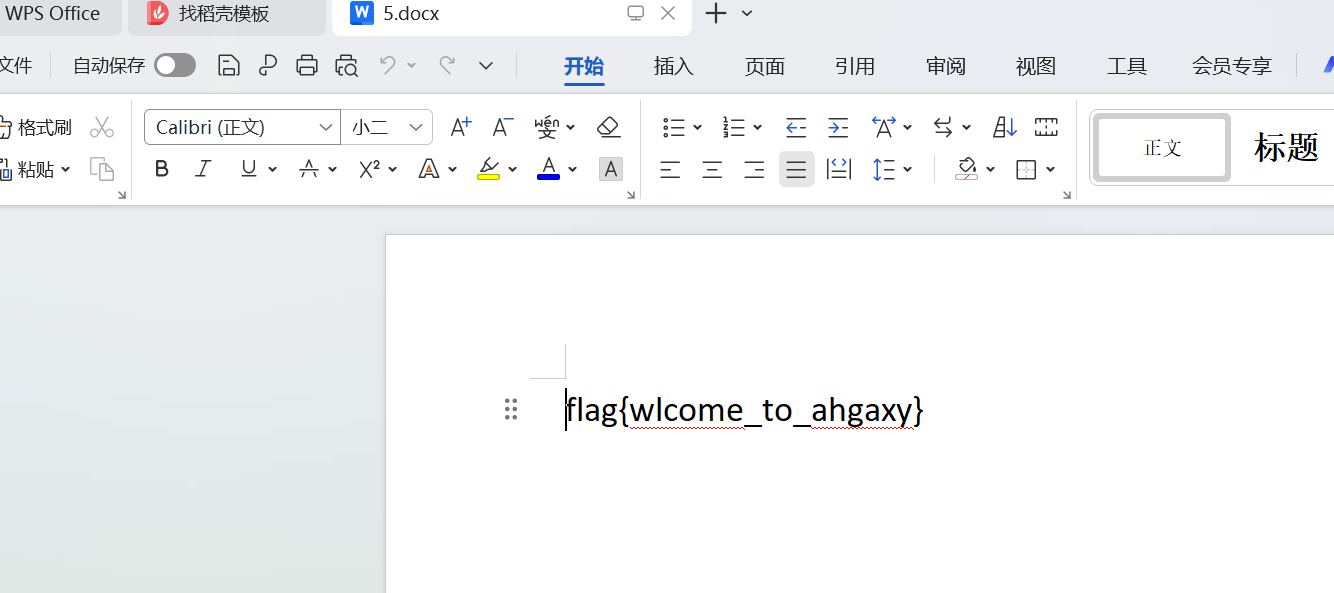
四步立定:青龙;白虎;朱雀;玄武 3分
答案:flag{wlcome_to_ahgaxy}
解析:- 第一步:base64转为zip文件,得到base64.zip
- 第一步:base64转为zip文件,得到base64.zip
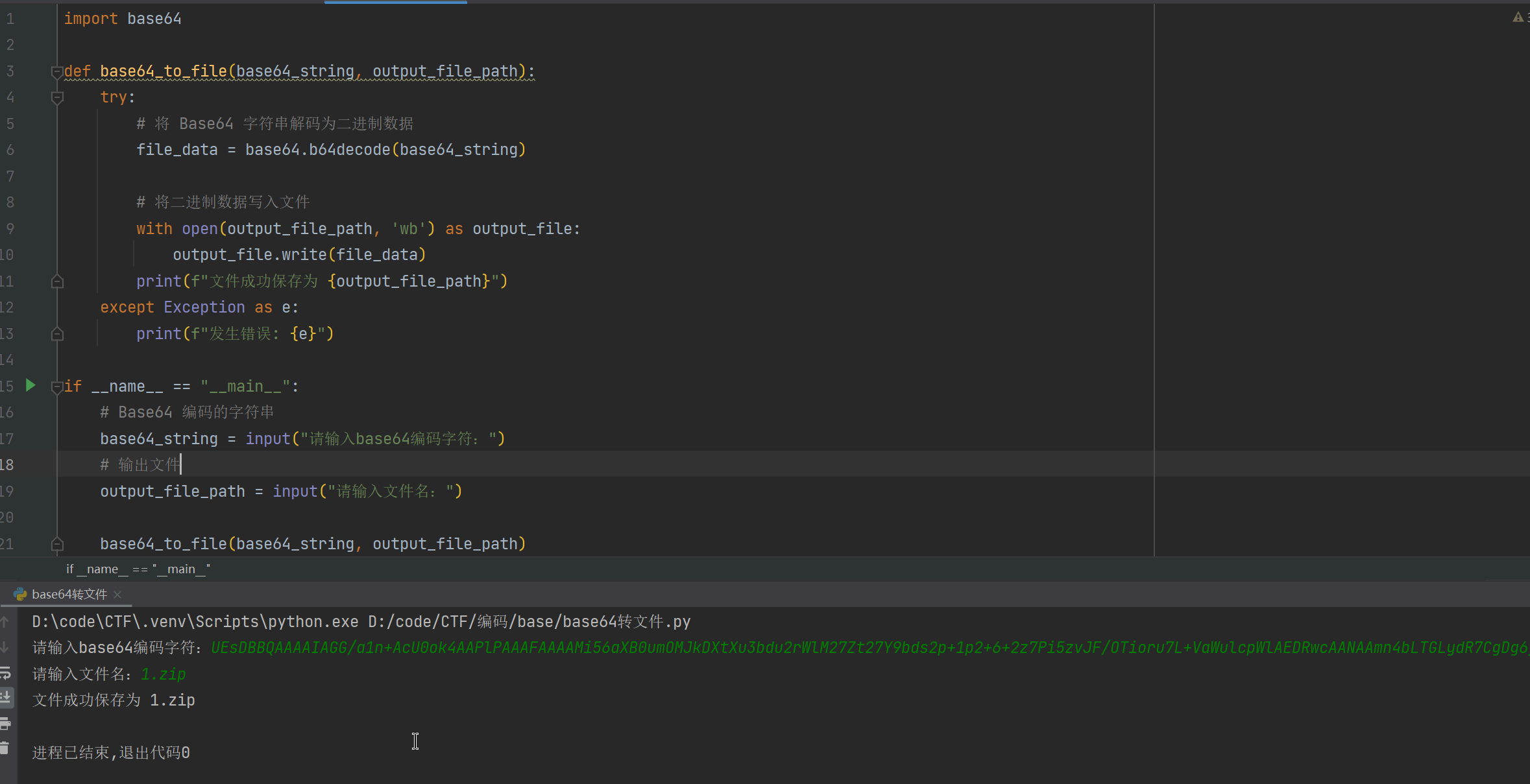
import base64 |
- 第二步:
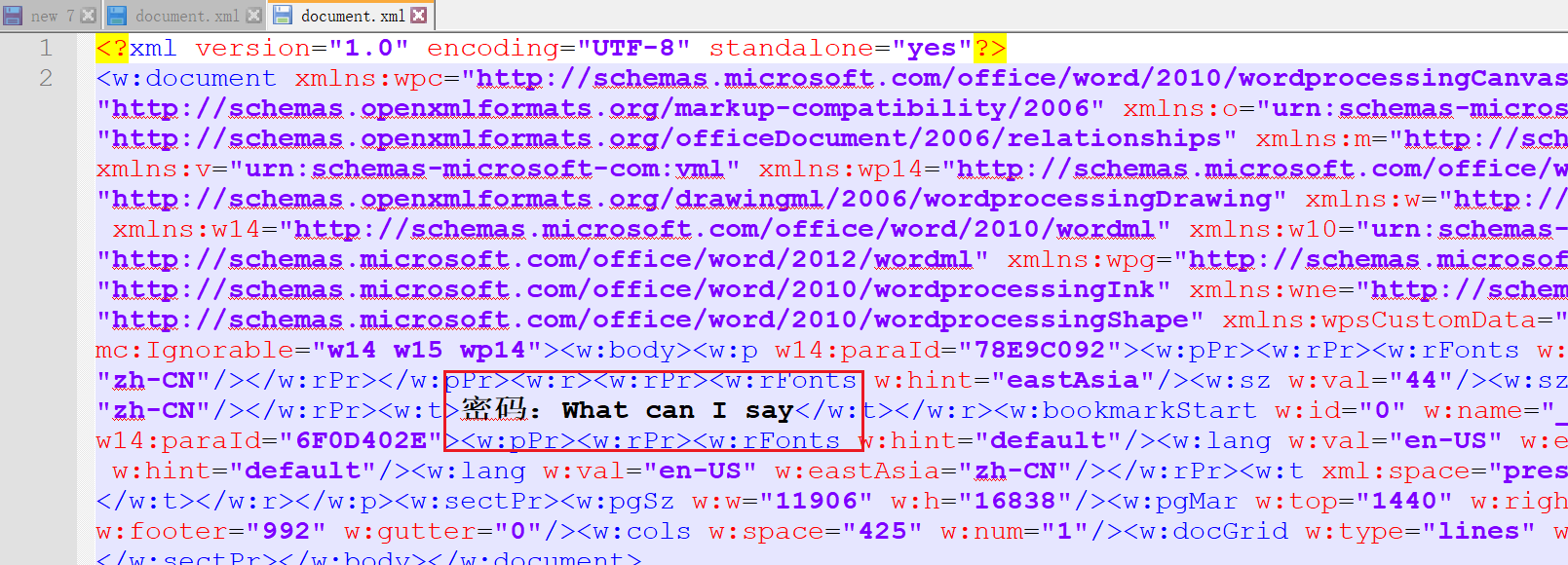
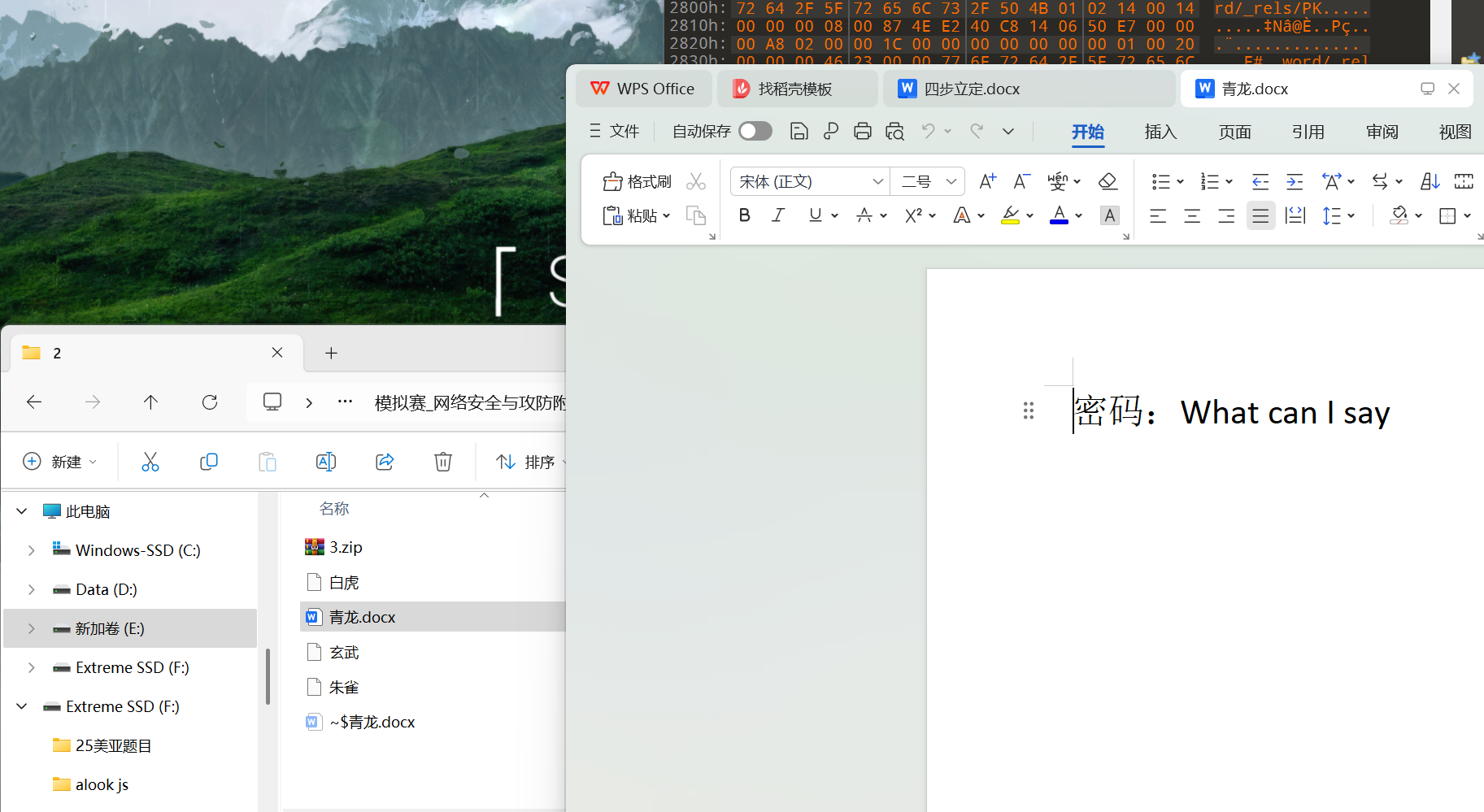
- 010拼起来,看不懂wp在干什么
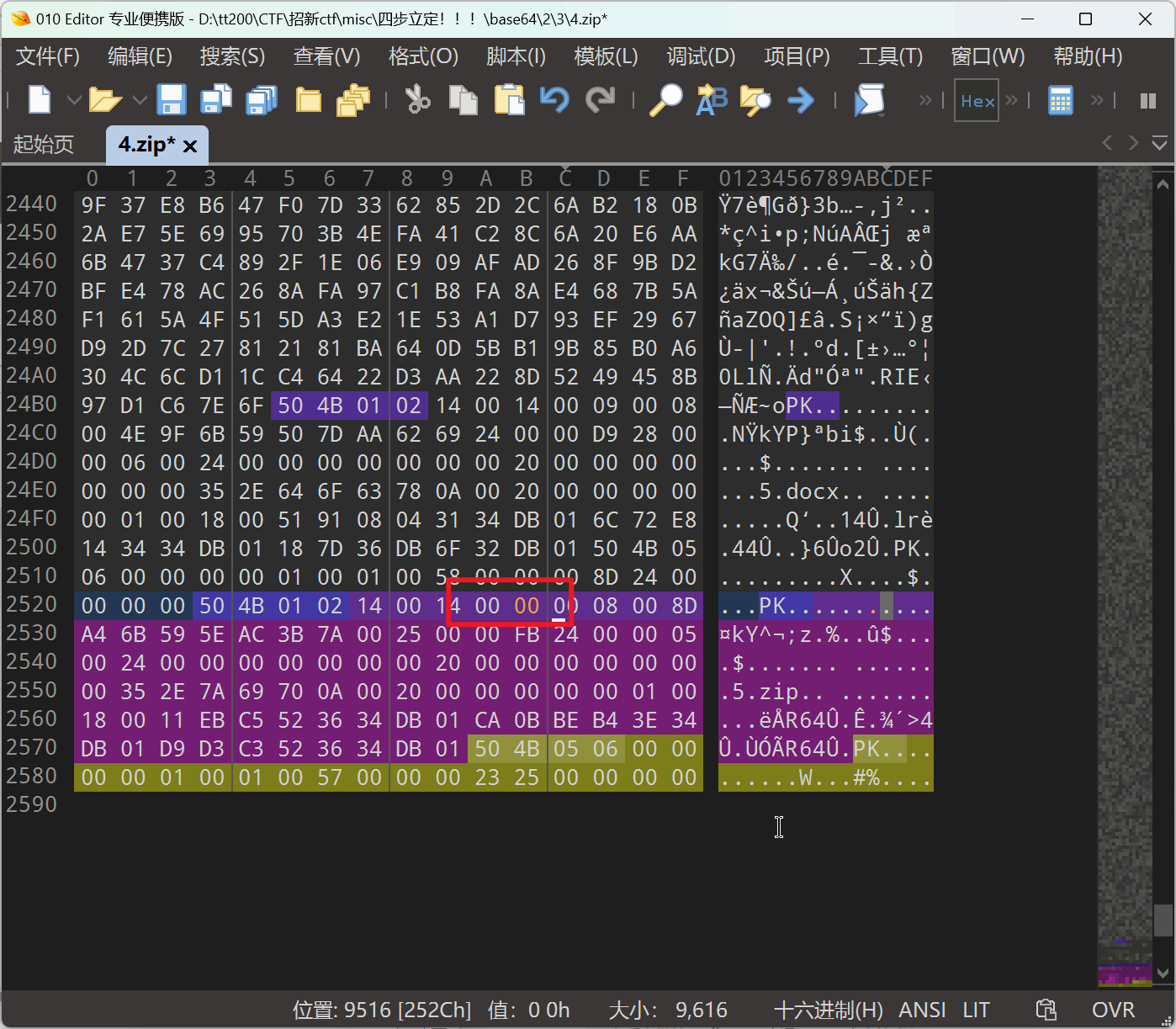
- 第三步
- 第四步:
2.3.2 crypto部分
- 异或2:你真的懂异或吗?
答案:flag{too_young_too_simple}
解析:
a = 'oehnr}ffVpf|gnV}ffVz`dyelt' |
-
异或3:你真真真真真真的懂异或吗? 3分
答案:flag{just_so_so}
解析:-
第一步:确定key为递增的
-
第二步
secret = 'gnbc~lr{}UxcR}`m'
flag = ''
key=1
for i in secret:
flag += chr(ord(i)^key)
key+=1
print(flag)
-

2.3.3 reverse
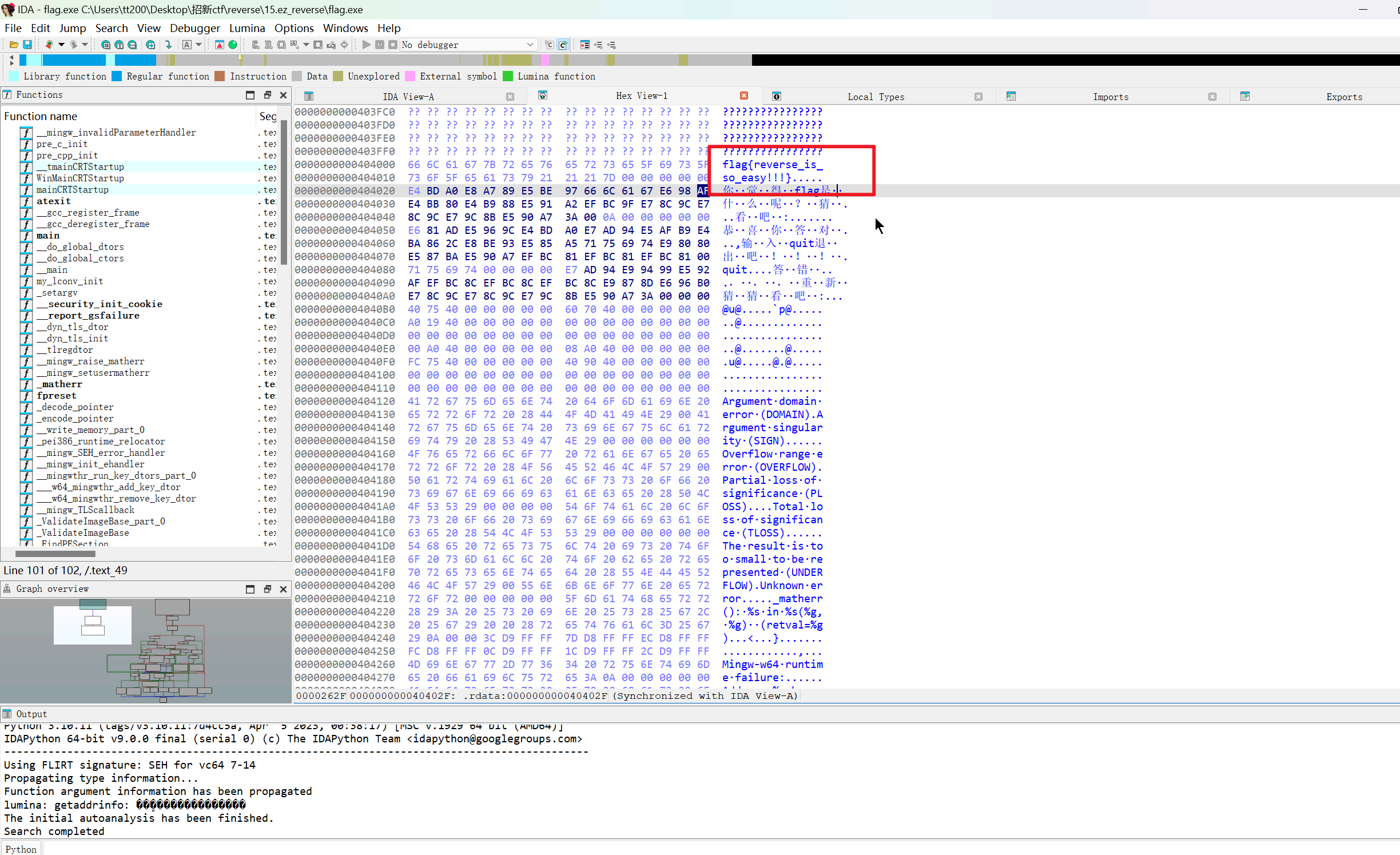
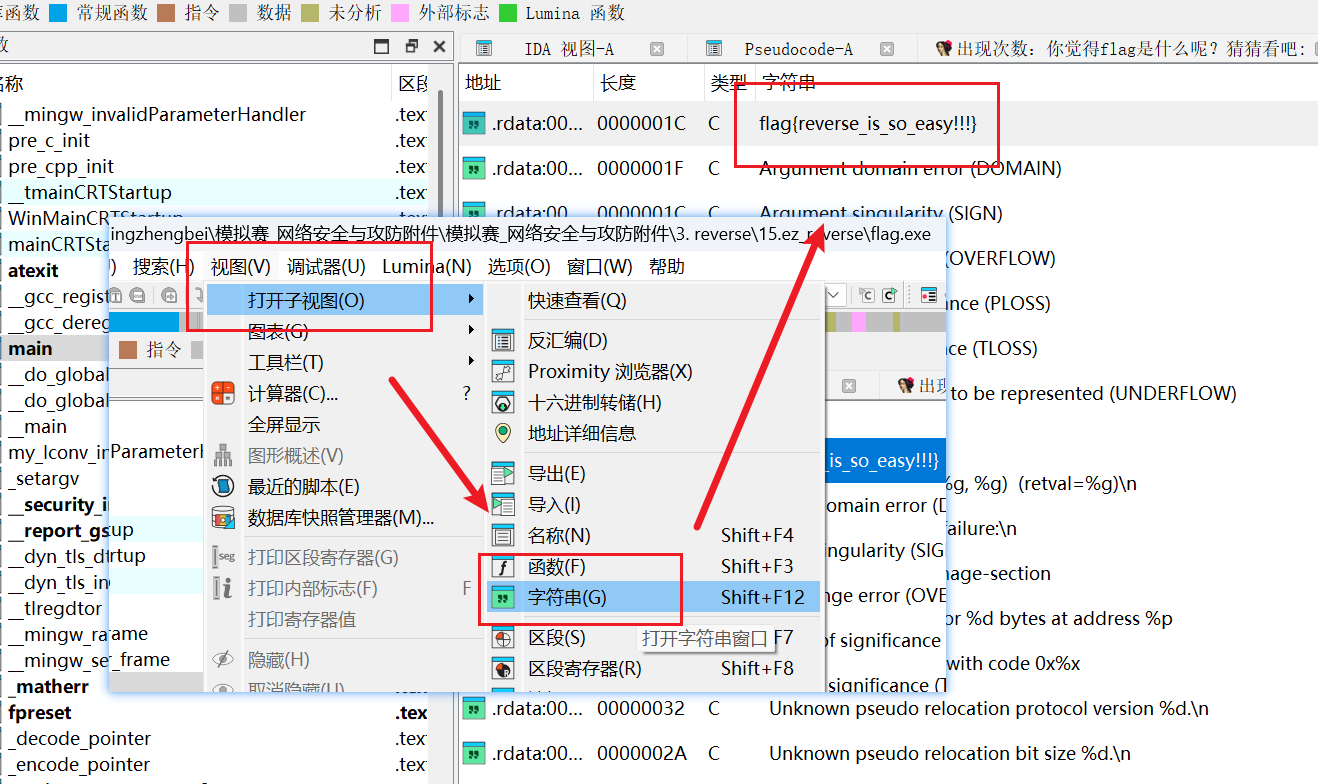
- ez_reverse:flag是什么呢?猜猜看吧!!!
答案:flag{reverse_is_so_easy!!!}
解析:
- 微信
- 支付宝


