推荐一篇写的特别特别好的文章
所以你可以这样 “C:\Tools\DIE\die.exe” %DEBUGGEE% 添加你常用的工具(记得路径加双引号),然后把收藏夹——收藏工具箱选上。点击Die图标,将会启动并且分析当前在调试的模块。这样的方法好过安装什么PE查看器插件,让专业的工具做专业的事
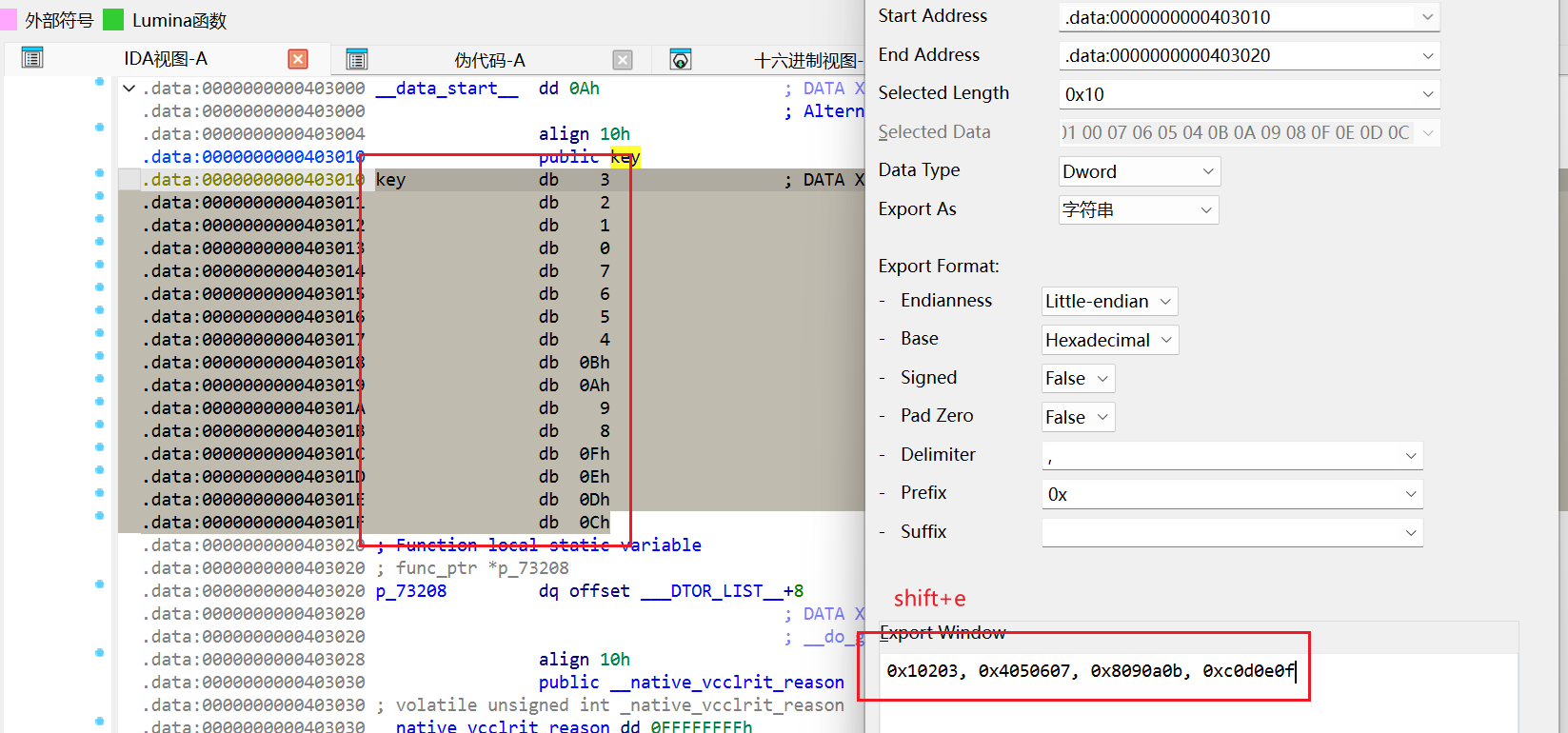
import idcimport idaapistartaddr=0x1100 endaddr=0x15FF lis=[] for i in range (startaddr,endaddr): flag=True for j in range (i,i+len (lis)): if idc.get_wide_byte(j)!=lis[j-i]: flag=False if flag==True : for addr in range (i,i+27 ): idc.patch_byte(addr,0x90 ) for i in range (startaddr,endaddr): idc.del_items(i) for i in range (startaddr,endaddr): if idc.get_wide_dword(i)==0xFA1E0FF3 : idaapi.add_func(i)
错误现象
根本原因 (Root Cause)
我们的修复操作
插件不加载 版本检测逻辑过时 :D810 检查代码认为 IDA 版本必须 >= 7.5,但其逻辑 if minor < 5 错误地拦截了 IDA 9.2 (因为 2 < 5)。修改 D810.py,重写版本检测逻辑,强制允许 IDA 9.x 加载。
Z3 模块报错 DLL 版本冲突 (DLL Hell) :IDA 自带的 libz3.dll 版本较旧,而 D810 依赖的 Python z3-solver 库需要新版 DLL。将 Python 环境中的 z3 库对应的 libz3.dll 复制并替换掉 IDA 根目录下的旧版文件。
Unicode Error 路径转义字符错误 :Windows 路径包含 \ (如 \Users),Python 字符串将其误读为转义符 (如 \U 开头被视为 Unicode)。修改 log.py 和 conf/__init__.py,使用 replace("\\", "/") 将反斜杠转换为正斜杠,或使用 IDA API 获取标准路径。
日志路径非法 权限与路径字符问题 :默认日志路径生成逻辑可能包含不可见字符或指向无权限目录。修改代码,强制将日志路径指向 IDA 的标准用户数据目录 (%APPDATA%\Hex-Rays\...)。
手动修复指南 **步骤一:安装插件** 将 `D810` 文件夹和 `D810.py` 复制到 IDA 的 `plugins` 目录。 **步骤二:修改版本检测 (关键)** 打开 `plugins\D810.py` ,找到类似 `if (major < 7) or (major == 7 and minor < 5):` 的代码,将其注释掉,或者改为强制允许所有 7.0 以上版本 if major < 7: return idaapi.PLUGIN_SKIP **步骤三:解决 Z3 冲突** 如果启动时报错 `Z3_solver_register_on_clause not found` : 1. 去 Python 安装目录 (`Lib\site-packages\z3\lib` ) 找到 `libz3.dll` 。2. 复制它,**覆盖** IDA 根目录下的同名文件 (建议先备份原文件)。**步骤四:修复日志路径错误** 打开 `plugins\d810\log.py` ,在 `configure_loggers` 函数开头添加强制修复路径分隔符: if isinstance(log_dir, str): log_ dir = log_dir.replace("\\", "/")
ptrace(PTRACE_POKEDATA, addr, addr, 3);
PTRACE_POKEDATA:该参数表示将一个值写入被调试进程的内存地址。
addr:这是目标内存地址。第一和第二个 addr 都是指向被调试进程的地址空间,代表要修改的内存位置。
3:这是要写入目标内存地址的值。
ptrace(PTRACE_CONT, 0, 0, 0);
PTRACE_CONT:让被调试的进程继续运行,类似于让被暂停的进程继续执行。
后面的参数为0,表示对当前进程无额外操作(pid 为0表示当前被调试的子进程,addr 和 data 设置为0表示没有其他控制)。
fork 函数
父进程中:fork() 返回子进程的进程ID(正值)。
子进程中:fork() 返回0。
出错时:fork() 返回-1。
反调试CheckRemoteDebuggerPresent + IsDebuggerPresent
百度 :键盘、转子和显示器
发送信息与接收信息的恩尼格玛密码机的设置必须相同:转子、其排列顺序,起始位置和接线板的连线
指示器
指示器步骤:转子的起始位置却是每发送一条信息就要更换的,因为如果一定数量的文件都按照相同的加密设置来加密的话,密码学家就会从中得到一些信息,并且有可能利用频率分析来破译这个密码
先按照密码本中的记录来设置机器,我们假设这时的转子位置为AOH,之后他会随意打三个字母,假设为EIN,接着为了保险起见,他会将这三个字母重新打一遍。这六个字母会被转换成其它六个字母,这里假设为XHTLOA。最后,操作员会将转子重新设置为EIN,即他一开始打的三个字母,之后输入密电原文
在接收方将信息解密时,他会使用相反的步骤。首先,他也会将转子按照密码本中的记录设置好,然后他就会打入密文中的头六个字母,即XHTLOA,如果发送方操作正确的话,显示板上就会显示EINEIN。这时接收方就会将转子设置为EIN,之后他就可将密电打入而得到原文了
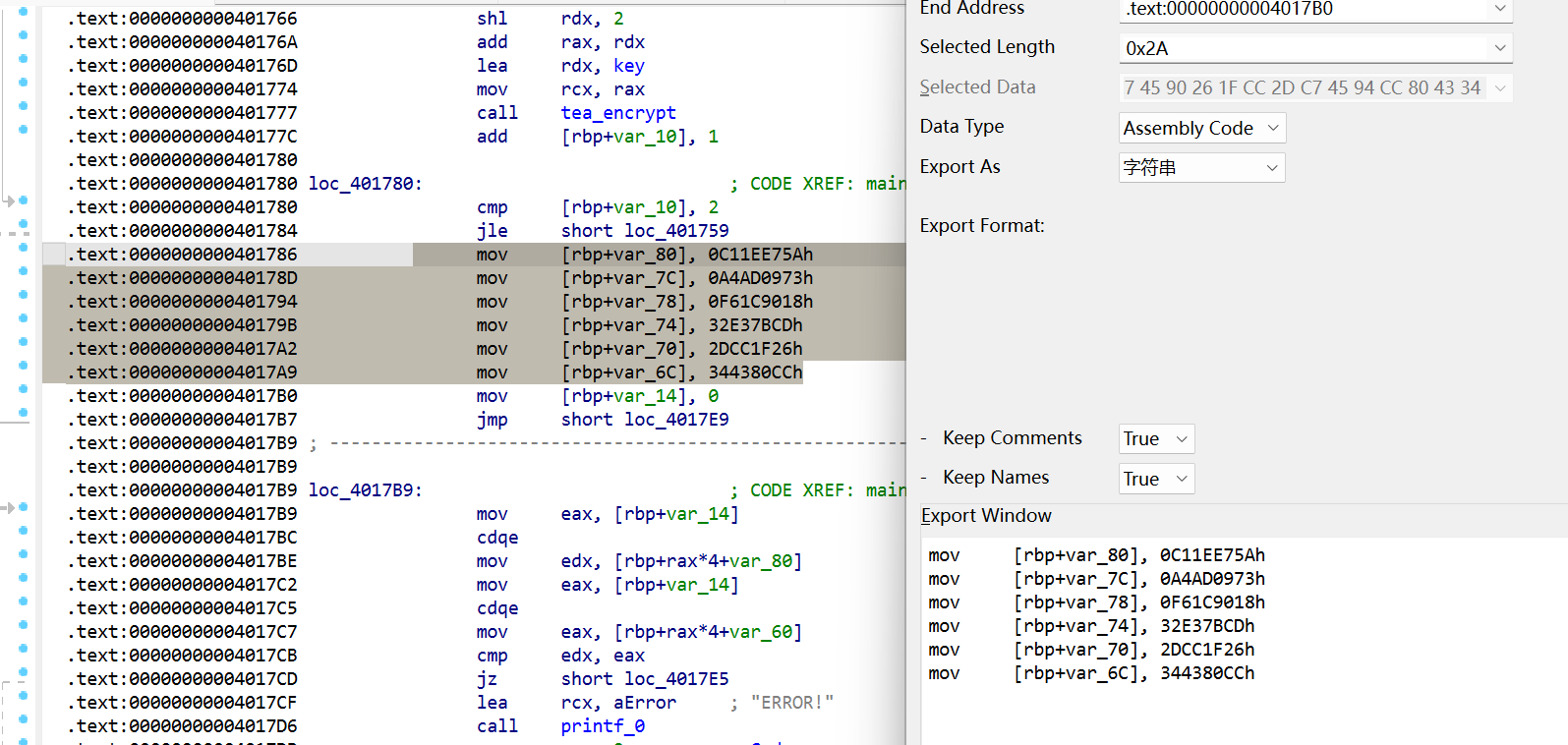
以加密解密速度快,实现简单著称DELTA常数 作为倍数,它来源于黄金分割数与232的乘积,以保证每一轮加密都不相同。但δ的精确值似乎并不重要,这里TEA把它定义为 δ=「(√5 - 1)231」,这个δ对应的数指就是0×9E3779B9,但有时该常数会以减法的形式出现,-0x61c88647=0×9E3779B9。
#include <stdio.h> #include <stdint.h> void encrypt (uint32_t * v, uint32_t * k) { uint32_t v0=v[0 ], v1=v[1 ], sum=0 , i; uint32_t delta=0x9e3779b9 ; uint32_t k0=k[0 ], k1=k[1 ], k2=k[2 ], k3=k[3 ]; for (i=0 ; i < 32 ; i++) { sum += delta; v0 += ((v1<<4 ) + k0) ^ (v1 + sum) ^ ((v1>>5 ) + k1); v1 += ((v0<<4 ) + k2) ^ (v0 + sum) ^ ((v0>>5 ) + k3); } v[0 ]=v0; v[1 ]=v1; } void decrypt (uint32_t * v, uint32_t * k) { uint32_t v0=v[0 ], v1=v[1 ], sum=0xC6EF3720 , i; uint32_t delta=0x9e3779b9 ; uint32_t k0=k[0 ], k1=k[1 ], k2=k[2 ], k3=k[3 ]; for (i=0 ; i<32 ; i++) { v1 -= ((v0<<4 ) + k2) ^ (v0 + sum) ^ ((v0>>5 ) + k3); v0 -= ((v1<<4 ) + k0) ^ (v1 + sum) ^ ((v1>>5 ) + k1); sum -= delta; } v[0 ]=v0; v[1 ]=v1; } int main () { uint32_t v[2 ]={1 ,2 },k[4 ]={2 ,2 ,3 ,4 }; printf ("加密前原始数据:%u %u\n" ,v[0 ],v[1 ]); encrypt(v, k); printf ("加密后的数据:%u %u\n" ,v[0 ],v[1 ]); decrypt(v, k); printf ("解密后的数据:%u %u\n" ,v[0 ],v[1 ]); return 0 ; }
识别特征:
标准DELTA常数(魔数)
如果改了ida findcypto插件就识别不出来了
密钥为16字节(4个DWORD)
加密轮数为16/32/64轮
加密结构中存在左4右5移位 以及异或运算 (v (2^n)==v<<n
加密结构中存在轮加/减相同常数的语句
TEA标准中使用的32轮加密,而腾讯只用了16轮。
TEA 算法被发现存在缺陷,作为回应,设计者提出了一个 TEA 的升级版本——XTEA。
#include <stdio.h> #include <stdint.h> void encipher (unsigned int num_rounds, uint32_t v[2 ], uint32_t const key[4 ]) { unsigned int i; uint32_t v0=v[0 ], v1=v[1 ], sum=0 , delta=0x9E3779B9 ; for (i=0 ; i < num_rounds; i++) { v0 += (((v1 << 4 ) ^ (v1 >> 5 )) + v1) ^ (sum + key[sum & 3 ]); sum += delta; v1 += (((v0 << 4 ) ^ (v0 >> 5 )) + v0) ^ (sum + key[(sum>>11 ) & 3 ]); } v[0 ]=v0; v[1 ]=v1; } void decipher (unsigned int num_rounds, uint32_t v[2 ], uint32_t const key[4 ]) { unsigned int i; uint32_t v0=v[0 ], v1=v[1 ], delta=0x9E3779B9 , sum=delta*num_rounds; for (i=0 ; i < num_rounds; i++) { v1 -= (((v0 << 4 ) ^ (v0 >> 5 )) + v0) ^ (sum + key[(sum>>11 ) & 3 ]); sum -= delta; v0 -= (((v1 << 4 ) ^ (v1 >> 5 )) + v1) ^ (sum + key[sum & 3 ]); } v[0 ]=v0; v[1 ]=v1; } int main () { uint32_t v[2 ]={1 ,2 }; uint32_t const k[4 ]={2 ,2 ,3 ,4 }; unsigned int r=32 ; printf ("加密前原始数据:%u %u\n" ,v[0 ],v[1 ]); encipher(r, v, k); printf ("加密后的数据:%u %u\n" ,v[0 ],v[1 ]); decipher(r, v, k); printf ("解密后的数据:%u %u\n" ,v[0 ],v[1 ]); return 0 ; }
识别特征:
加密结构中存在右移11位并&3 的运算
最显眼的特征:原先TEA算法的v1 + sum变成了(sum + key[sum & 3])以及sum + key[(sum>>11) & 3]
可以魔改的点依然是Delta的值,轮数
exp:
#include <stdio.h> #include <stdint.h> void decrypt (uint32_t * v, uint32_t * k) { long delta=0x61C88647 ; for (int j = 0 ; j < 6 ; j += 2 ) { unsigned int v0 = v[j]; unsigned int v1 = v[j+1 ]; unsigned int v6 = 0 ; long sum = -delta*32 ; for (int i=0 ; i < 32 ; i++) { v1 -= (((v0 >> 5 ) ^ (16 * v0)) + v0) ^ (k[((sum >> 11 ) & 3 )] + sum); sum += delta; v0 -= (((v1 >> 5 ) ^ (16 * v1)) + v1) ^ (k[(sum & 3 )] + sum); } v[j]=v0; v[j+1 ]=v1; } } int main () { uint32_t enflag[] = {0xC11EE75A , 0xA4AD0973 , 0xF61C9018 , 0x32E37BCD , 0x2DCC1F26 , 0x344380CC }; uint32_t key[] = {0x00010203 ,0x04050607 ,0x08090A0B ,0x0C0D0E0F }; decrypt(enflag, key); printf ("%s" ,enflag); return 0 ; }
XXTEA,又称Corrected Block TEA,是XTEA的升级版 ,设计者是Roger Needham, David Wheeler。其实现过程要比前两种的算法略显复杂些,加密的明文不再是64bit(两个32位无符号整数),并且其加密轮数是由n ,即待加密数据个数决定的。
特点:原字符串长度可以不是4的倍数了
#include <stdio.h> #include <stdint.h> #define DELTA 0x9e3779b9 #define MX (((z>>5^y<<2) + (y> >3^z<<4)) ^ ((sum^y) + (key[(p&3)^e] ^ z))) void btea (uint32_t *v, int n, uint32_t const key[4 ]) { uint32_t y, z, sum; unsigned p, rounds, e; if (n > 1 ) { rounds = 6 + 52 /n; sum = 0 ; z = v[n-1 ]; do { sum += DELTA; e = (sum >> 2 ) & 3 ; for (p=0 ; p<n-1 ; p++) { y = v[p+1 ]; z = v[p] += MX; } y = v[0 ]; z = v[n-1 ] += MX; } while (--rounds); } else if (n < -1 ) { n = -n; rounds = 6 + 52 /n; sum = rounds*DELTA; y = v[0 ]; do { e = (sum >> 2 ) & 3 ; for (p=n-1 ; p>0 ; p--) { z = v[p-1 ]; y = v[p] -= MX; } z = v[n-1 ]; y = v[0 ] -= MX; sum -= DELTA; } while (--rounds); } } int main () { uint32_t v[2 ]= {1 ,2 }; uint32_t const k[4 ]= {2 ,2 ,3 ,4 }; int n= 2 ; printf ("加密前原始数据:%u %u\n" ,v[0 ],v[1 ]); btea(v, n, k); printf ("加密后的数据:%u %u\n" ,v[0 ],v[1 ]); btea(v, -n, k); printf ("解密后的数据:%u %u\n" ,v[0 ],v[1 ]); return 0 ; }
#include <stdio.h> #include <stdint.h> #define DELTA 0x9E3779B9 #define MX (((z>>5 ^ y<<2) + (y> >3 ^ z<<4)) ^ ((sum^y) + (key[(p&3)^e] ^ z))) void btea (uint32_t * v, int n, const uint32_t key[4 ]) { uint32_t y, z, sum; unsigned p, rounds, e; if (n < -1 ) { n = -n; rounds = 6 + 52 / n; sum = rounds * DELTA; y = v[0 ]; do { e = (sum >> 2 ) & 3 ; for (p = n - 1 ; p > 0 ; p--) { z = v[p - 1 ]; y = v[p] -= MX; } z = v[n - 1 ]; y = v[0 ] -= MX; sum -= DELTA; } while (--rounds); } } int main () { uint32_t v[12 ] = { 0x8c12d3dfU L, 0x5f4c4137U L, 0x1a9d3d02U L, 0x2d1294b7U L, 0xfb622b37U L, 0xd18d84e3U L, 0x64c4592U L, 0x16985cabU L, 0xfdb06d69U L, 0xfb30b1e3U L, 0x925c2fd3U L, 0x2e1bb40cU L }; const uint32_t * k = (const uint32_t *)"keykeykey" ; btea(v, -12 , k); printf ("%s\n" , (char *)v); return 0 ; }
XXTEA算法的解密同样只是对加密算法的数据处理顺序进行倒置,同时加法改减法(减法改加法)。
识别特征:
轮数一般为 rounds = 6 + 52 / n,比较明显,一般很少改动
xxtea算法的例题很少见,感觉见的最多的是xtea及其变形。每一道题都有不同,不能死套着脚本,应该根据题的不同而进行修改,比如轮数,魔数,异或等的一些改变。
识别特征:
可能存在针对64bit以及128bit数字的操作(输入的msg和key)
存在先进行位移,然后异或 的类似操作((z>>5^y<<2)这类混合变换)
前面一个复杂的混合变换的结果可能会叠加到另一个值上,两者相互叠加(Feistel 结构)
获取密钥的时候,会使用某一个常量值作为下标(key[(sum>>11) & 3])
会在算法开始定义一个delta,并且这个值不断的参与算法,但是从来不会受到输入的影响 (delta数值,根据见过的题目中很少会直接使用0x9e3779b9)
借鉴于一位大佬写的博客https://www.kn0sky.com/?p=279
快速幂引入
为了方便大家理解,我会用两种角度去讲解快速幂算法,二进制与指数折半,其实这两个的本质是一样的,只是分析的角度有些许不同,大家可以按照适合自己的角度去理解快速幂算法,当然两种角度都了解了,那更是最好了。
快速幂 二进制
核心思想:利用二进制来加速运算
c 中 & 作为双目运算符/按位与:a & b,只有a、b都是 1 结果才为 1
long long int quik_power (int base, int power) { long long int result = 1 ; while (power > 0 ) { if (power & 1 ) result *= base; base *= base; power >>= 1 ; } return result; }
快速幂 指数折半
核心思想:每一次运算都把指数折半,底数变其平方
快速幂一般不会独立使用,常常配合取余运算法则来使用。
需要了解一下关于取余的公式
(a + b) % p = (a % p + b % p) % p (a - b) % p = (a % p - b % p ) % p (a * b) % p = (a % p * b % p) % p
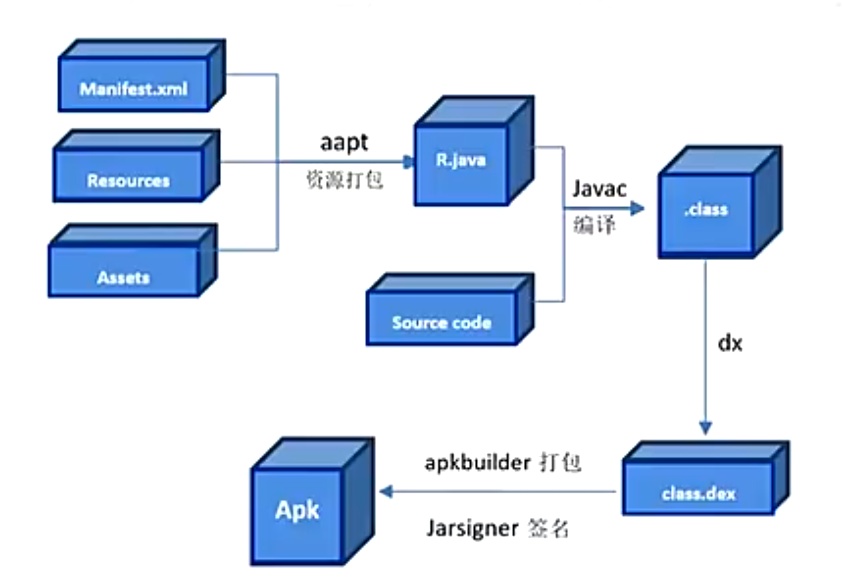
APK 是 Android PacKage 的缩写,是 Android 源文件打包后的安装包。apk 其实就是一个 zip 格式的压缩包。想要知道 apk 包含了什么,可以修改后缀名为zip,然后用解压缩工具打开 apk 文件。 如果有代码混淆和加密 ,通过普通解压缩工具打开里面的文件或目录会看到各种乱码。
文件目录:
assets 不经过 aapt 编译的资源文件,apk 中不用编译的资源(其他类型的文件)通常放在 /assets 目录和 /res/raw 目录下
drawable 图片
lib .so 文件 放到IDA64位里逆向
META-INF 文件摘要,摘要加密和签名证书文件目录
CERT.RSA 公钥和加密算法描述
CERT.SF 加密文件,它是使用私钥对摘要明文加密后得到的 密文信息,只有使用私钥配对的公钥才能解密该文件
MANIFEST.MF 程序清单文件,它包含包中所有文件的摘要明文
res 资源文件目录,二进制格式
layout 布局
menu 菜单
resources.arsc 经过 aapt 编译过的资源文件
classes.dex 可执行文件
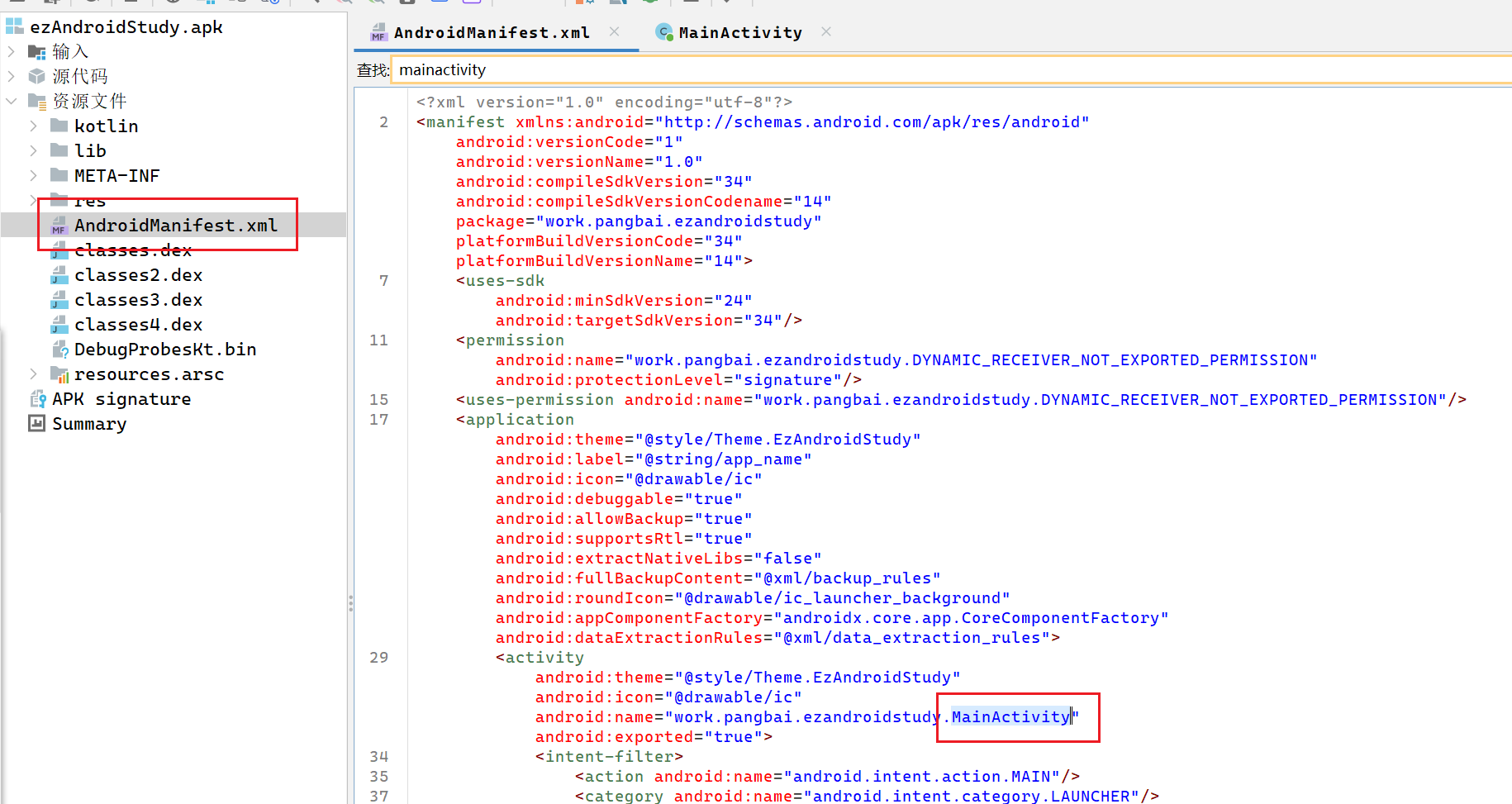
AndroidManifest.xml 配置文件,做题时可以先查找 AndroidManifest.xml 文件里的 Activity 标签,一个Activity相当于一个页面,可以快速找到MainActivity并跳转。
assets 文件夹 :程序资源目录
assets 文件夹用于保存需要保持原始文件的资源文件夹,开发过程中拖了什么到里面,打包完之后里面还是什么。
一般用于存放音频,网页(帮助页面之类的),字体等文件。
主要需要知道的点是,它与 res 文件夹的区分以及如何在应用中访问该文件夹的资源,如它可以有多级目录而 res 则只有两级。
res 文件夹 :资源文件夹
它里面存放的所有文件都会被映射到 R 文件中,生成对应的资源 ID,便于代码中通过 ID 直接访问。
其中的资源文件包括了动画(anim),图像(drwable),布局(layout),常量值(values),颜色值(colors),尺寸值(dimens),字符串(strings),自定义样式(styles)等。
在编译时会自动生成索引文件(R.java),在 Java 代码中用 R.xxx.yyy 来引用。
而 assets 目录下资源文件不会生成索引,在 Java 代码中需要使用 AssetManager 来访问。一般使用 Java 开发的 Android 工程使用的资源文件都会放在 res下。
lib 文件夹 :so 文件存放位置
该目录存放着应用需要的 native 库文件。
文件夹下有时会多一个层级,这是根据不同CPU 型号而划分的,如 ARM,ARM-v7a,x86等。
META-INF :签名证书目录AndroidManifest.xml :全局配置文件
它包含了这个应用的很多配置信息,例如包名、版本号、所需权限、注册的服务等。可以根据这个文件在相当程度上了解这个应用的一些信息。
该文件是被编译为二进制的 XML 文件,可以通过一些工具(如 apktool、jadx、jeb、AndroidKiller 等)反编译后进行查看。也可以通过 android studio —> build —> Analyze Apk 来分析 apk
android studio下载地址:https://developer.android.com/studio?hl=zh-cn
有点难用我就先不用这玩意了(指免费版本
dex 文件 :classes.dex 文件,是 Android 系统运行于 Dalvik Virtual Machine 上的可执行文件,也是Android 应用程序的核心所在。
项目工程中的 Java 源码通过 javac 生成 class 文件,再通过 dx 工具转换为 classes.dex,注意到我们这里有 classes2.dex 和 classes3.dex。这是方法数超过一个 dex 的上限,分 dex 的结果。
resource.arsc 文件 :字符串、资源索引文件。它记录了资源文件,资源文件位置(各个维度的路径)和资源 id 的映射关系。并且将所有的 string 都存放在了 string pool 中,节省了在查找资源时,字符串处理的开销。META-INF 文件夹 :该目录的主要作用是用于保证 APK 的完整性以及安全性。该文件夹下,主要有三个文件。MANIFEST.MF :这个文件保存整个apk文件中 所有文件的文件名 + SHA-1后的编码值。这也就意味着,MANIFEST.MF 象征着 apk 包的完整性。
1.编译器将您的源代码转换成 DEX 文件(Dalvik 可执行文件,其中包括在 Android 设备上运行的字节码),并将其他所有内容转换成编译后的资源。
2.打包器将 DEX 文件和编译后的资源组合成 APK 或 AAB(具体取决于所选的 build 目标)。
3.打包器使用调试或发布密钥库为 APK 或 AAB 签名。
4.在生成最终 APK 之前,打包器会使用 zipalign 工具对应用进行优化,以减少其在设备上运行时所占用的内存
这是学习安卓逆向时要了解的知识。
1. jadx
jadx是一款开源的DEX到Java的反汇编工具。它支持apk、dex、jar、class、zip、aar等文件。比较方便的是可以搜索。jadx还支持对Smali代码的调试,单步,设置断点,修改寄存器的值,修改类属性等相关功能。
官方地址:https://github.com/skylot/jadx/
jadx的文本搜索功能比较高效,可以同时从类名,方法名,代码等选择搜索字段
在jadx中还有很多功能比如将反编译的文件保存为Gradle项目
右键点击方法名
跳到声明 ,这样就能找到该方法的位置。查找用例 ,右键点击方法名,就可以找到调用该方法的位置了。
2. JEB工具
JEB是一款强大的安卓APK逆向分析工具。JEB安装好后,在它的安装目录下分别有jeb_linux.sh , jeb_macos.sh和jeb_wincon.bat这3个文件,它们是不同操作系统的启动程序,分别对应Linux,macOS和 Windows操作系统。运行jeb_wincon.bat文件启动JEB,首次启动时的速度可能稍慢。
常用功能:
在安卓逆向动态分析中动态调试有两种方法:
3. GDA
GDA 不只是一款反编译器,同时也是一款轻便且功能强大的综合性逆向分析利器,不依赖 java 环境。支持 apk, dex, odex, oat, jar, class, aar文件的反编译,支持python及java脚本自动化分析。其包含多个由作者独立研究的高速分析引擎:反编译引擎、漏洞检测引擎、 恶意行为检测引擎、污点传播分析引擎、反混淆引擎、apk壳检测引擎等等
详细的应用操作可以学习这篇博客:https://zhuanlan.zhihu.com/p/28354064
刚入门,学的不多,思路待补充
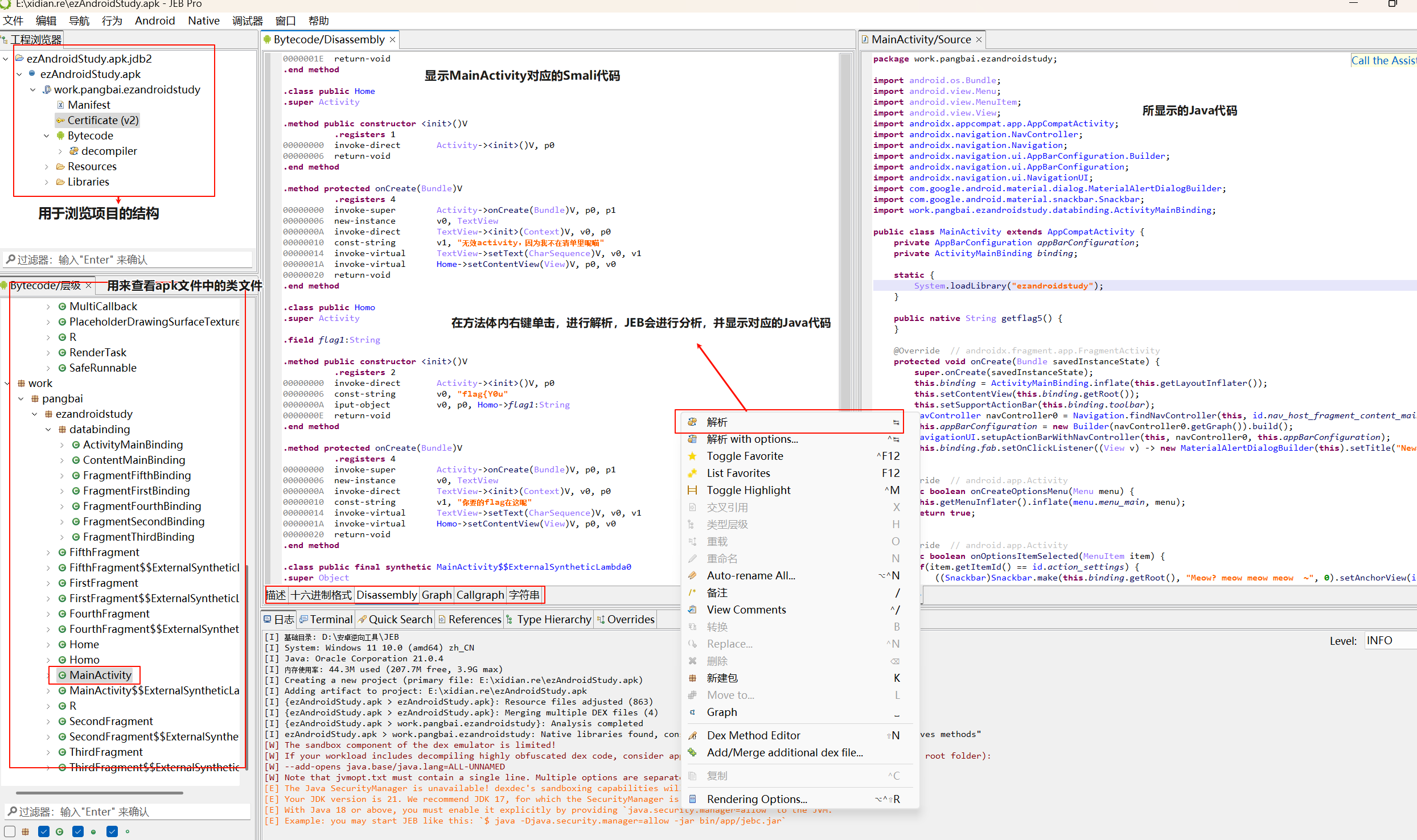
拿到apk文件,用安卓逆向工具打开(我一般用jadx),然后找到MainActivity
找到并打开AndroidManifest.xml,然后找到文件里的 Activity 标签,一个Activity相当于一个页面,可以快速找到MainActivity并跳转。
分析MainActivity的Java源代码,看如何对flag加密,进行静态分析。
如果有 native 标签说明函数是 C 语言编写的,主体在 so 文件,需要逆向so文件
使用 blutter: Flutter Mobile Application Reverse Engineering Tool 进行逆向分析, asm/liekai 路径下为该项目核心的逻辑代码
import osimport shutilimport zipfilefrom pathlib import PathICU_LIB_URL = 'https://github.com/unicode-org/icu/releases/download/release-73-2/icu4c-73_2-Win64-MSVC2019.zip' CAPSTONE_LIB_URL = 'https://github.com/capstone-engine/capstone/releases/download/4.0.2/capstone-4.0.2-win64.zip' SCRIPT_DIR = os.path.dirname(os.path.realpath(__file__)) BIN_DIR = os.path.join(SCRIPT_DIR, '..' , 'bin' ) EXTERNAL_DIR = os.path.join(SCRIPT_DIR, '..' , 'external' ) ICU_WINDOWS_FILE = os.path.join(EXTERNAL_DIR, 'icu4c-73_2-Win64-MSVC2019.zip' ) ICU_WINDOWS_DIR = os.path.join(EXTERNAL_DIR, 'icu-windows' ) CAPSTONE_DIR = os.path.join(EXTERNAL_DIR, 'capstone' ) CAPSTONE_ZIP_FILE = os.path.join(EXTERNAL_DIR, 'capstone-4.0.2-win64.zip' ) Path(BIN_DIR).mkdir(parents=True , exist_ok=True ) Path(EXTERNAL_DIR).mkdir(parents=True , exist_ok=True ) if os.path.exists(CAPSTONE_DIR): shutil.rmtree(CAPSTONE_DIR) if os.path.exists(ICU_WINDOWS_DIR): shutil.rmtree(ICU_WINDOWS_DIR) print ('Checking ICU library file...' )if not os.path.exists(ICU_WINDOWS_FILE): print (f'Error: ICU zip file not found at {ICU_WINDOWS_FILE} ' ) exit(1 ) print ('Extracting ICU library from local file' )with zipfile.ZipFile(ICU_WINDOWS_FILE, 'r' ) as z: z.extractall(ICU_WINDOWS_DIR) nested_zip = None for root, dirs, files in os.walk(ICU_WINDOWS_DIR): if 'icu-windows.zip' in files: nested_zip = os.path.join(root, 'icu-windows.zip' ) break if nested_zip: print (f'Found nested zip file: {nested_zip} ' ) print ('Extracting nested ICU zip...' ) temp_dir = os.path.join(EXTERNAL_DIR, 'icu_temp' ) if os.path.exists(temp_dir): shutil.rmtree(temp_dir) Path(temp_dir).mkdir(parents=True , exist_ok=True ) with zipfile.ZipFile(nested_zip, 'r' ) as z: z.extractall(temp_dir) shutil.rmtree(ICU_WINDOWS_DIR) for root, dirs, files in os.walk(temp_dir): if 'bin64' in dirs: bin64_path = os.path.join(root, 'bin64' ) for item in os.listdir(bin64_path): src = os.path.join(bin64_path, item) dst = os.path.join(ICU_WINDOWS_DIR, item) if os.path.isfile(src): Path(ICU_WINDOWS_DIR).mkdir(parents=True , exist_ok=True ) shutil.copy(src, dst) break shutil.rmtree(temp_dir) else : print ('No nested zip found, looking for dll files directly' ) print ('Checking Capstone library file...' )if not os.path.exists(CAPSTONE_ZIP_FILE): print (f'Error: Capstone zip file not found at {CAPSTONE_ZIP_FILE} ' ) exit(1 ) print ('Extracting Capstone library from local file' )with zipfile.ZipFile(CAPSTONE_ZIP_FILE, 'r' ) as z: first_file = z.namelist()[0 ] capstone_zip_dir = first_file.split('/' )[0 ] if '/' in first_file else first_file.split('\\' )[0 ] z.extractall(EXTERNAL_DIR) extracted_capstone = os.path.join(EXTERNAL_DIR, capstone_zip_dir) if os.path.exists(extracted_capstone): if os.path.exists(CAPSTONE_DIR): shutil.rmtree(CAPSTONE_DIR) os.rename(extracted_capstone, CAPSTONE_DIR) print (f'Capstone extracted to {CAPSTONE_DIR} ' ) else : print (f'Error: Could not find extracted capstone at {extracted_capstone} ' ) print ('Copying dlls to bin directory' )capstone_dll = os.path.join(CAPSTONE_DIR, 'capstone.dll' ) if os.path.exists(capstone_dll): shutil.copy(capstone_dll, BIN_DIR) print ('Copied capstone.dll' ) else : print (f'Error: capstone.dll not found at {capstone_dll} ' ) icu_dll_copied = 0 if os.path.exists(ICU_WINDOWS_DIR): for dll in ['icudt73.dll' , 'icuuc73.dll' ]: src = os.path.join(ICU_WINDOWS_DIR, dll) if os.path.exists(src): shutil.copy(src, BIN_DIR) print (f'Copied {dll} ' ) icu_dll_copied += 1 else : print (f'Warning: {dll} not found at {src} ' ) if icu_dll_copied == 2 : print ('Successfully copied all required DLLs' ) else : print (f'Warning: Only copied {icu_dll_copied} of 2 required ICU DLLs' ) print ('Done' )
本地下载 github 内容到 external 文件夹然后运行该脚本
使用:
python blutter.py 路径\app\lib\arm64-v8a 输出目录
Unity3D 最大的一个特点是一次制作,多平台部署,而这一核心功能是靠 Mono 实现的。可以说一直以来 Mono 是 Unity3D 核心中的核心,是 Unity3D 跨平台的根本。这种形式一直持续到 2014 年年中,Unity3D 官方博客上发了一篇 “The future of scripting in unity ” 的文章,引出了 IL2CPP 的概念,这种相比 Mono 来说安全性更强的方式。
Mono打包逆向
Mono打包方式逆向比较简单,其核心代码都在 game/data/Managed/AssemblyCSarp.dll 这个 dll 文件中,使用 dnSpy 进行分析,几乎就是可以明文随便篡改。
例题:
[BJDCTF2020]BJD hamburger competition
这个Mono还是比较好识别出来的, 游戏名_Data -> Managed -> AssemblyCSarp.dll
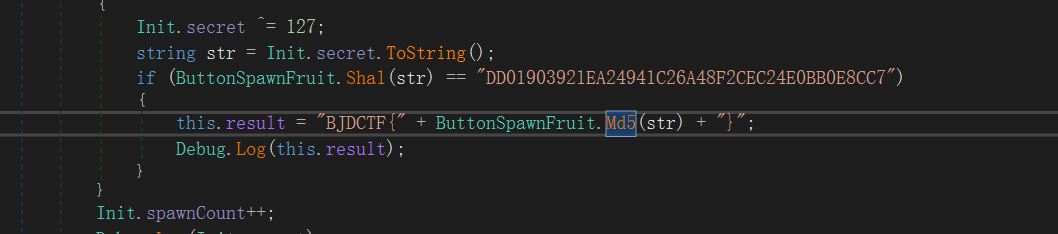
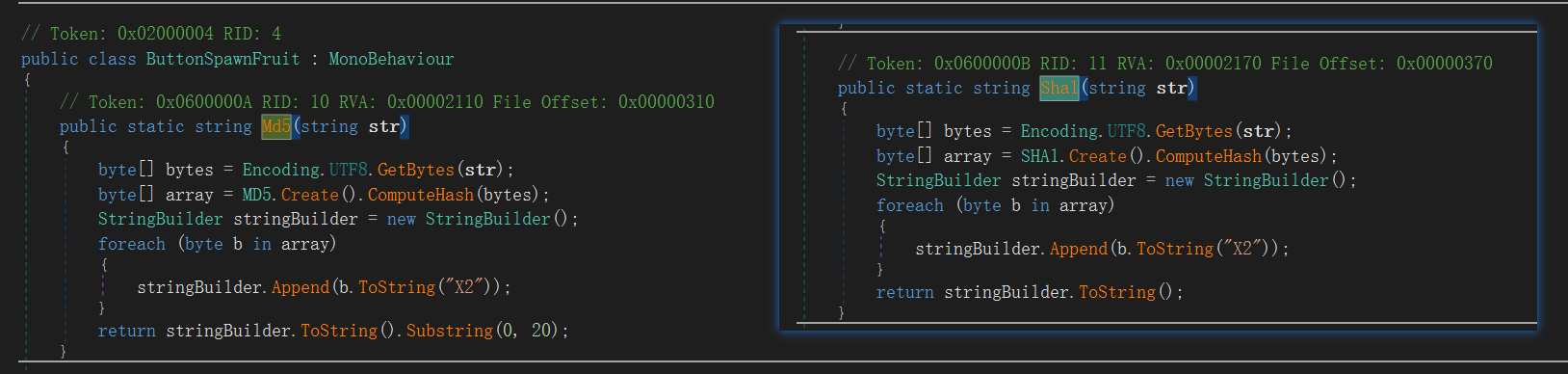
将AssemblyCSarp.dll放入dnSpy里面进行分析,找到ButtonSpawnFruit(),里面有md5和sha1,点进去进行交叉引用
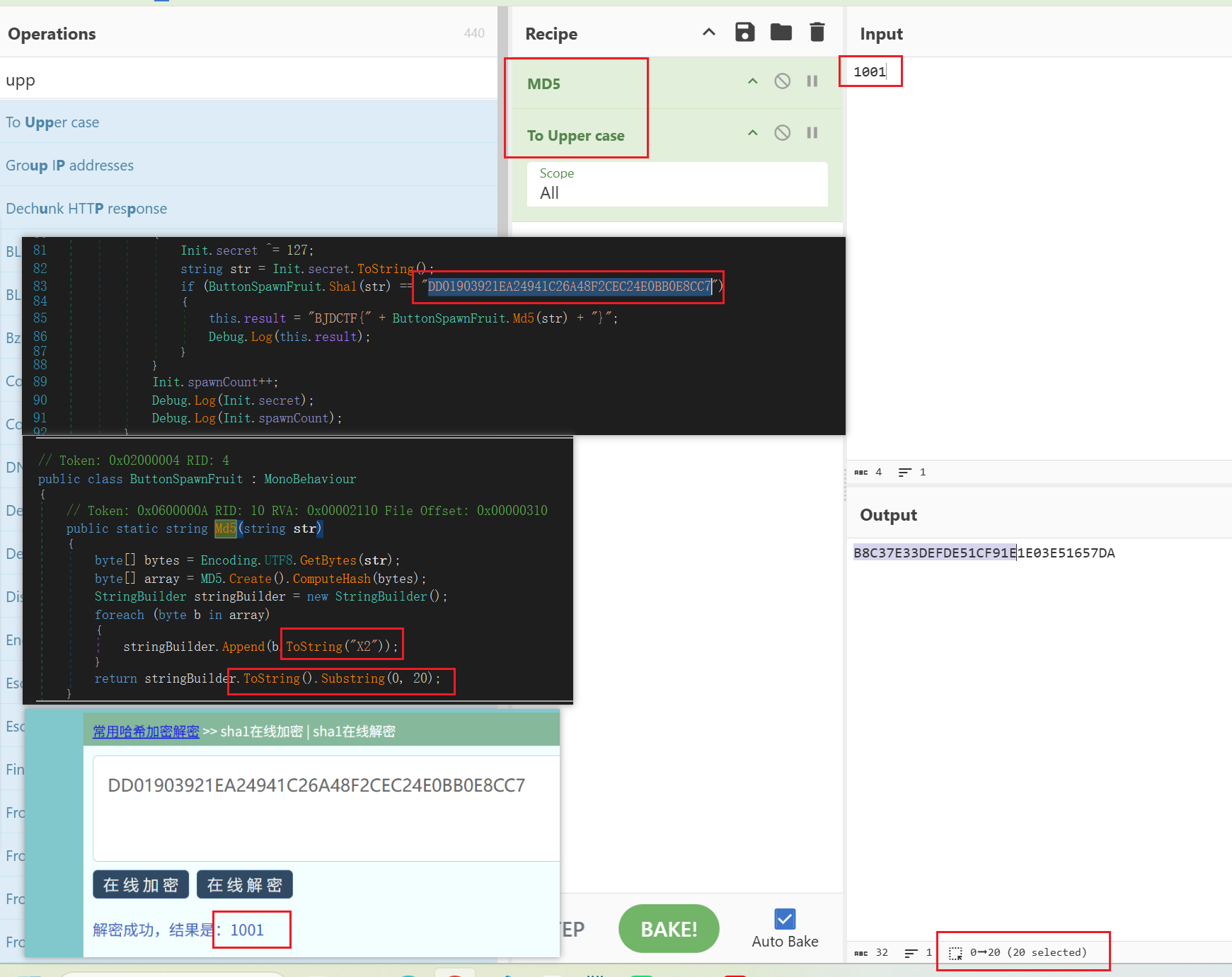
可以推测,每一个菜都对应着一种操作,这与上菜的顺序有关,按照一定的顺序加菜,使得 str 的 Sha1与那一串相等,然后将 str 进行md5加密,但是这里要注意,要看看Sha1加密和md5是否都是标准的。
Sha1和 md5都是标准的,但是md5是取前20个字符,X表示的是大写16进制,x表示小写16进制
在 C# 中,Substring(0, 20) 会返回从索引 0 开始的20个字符(即从位置 0 到位置 19)。
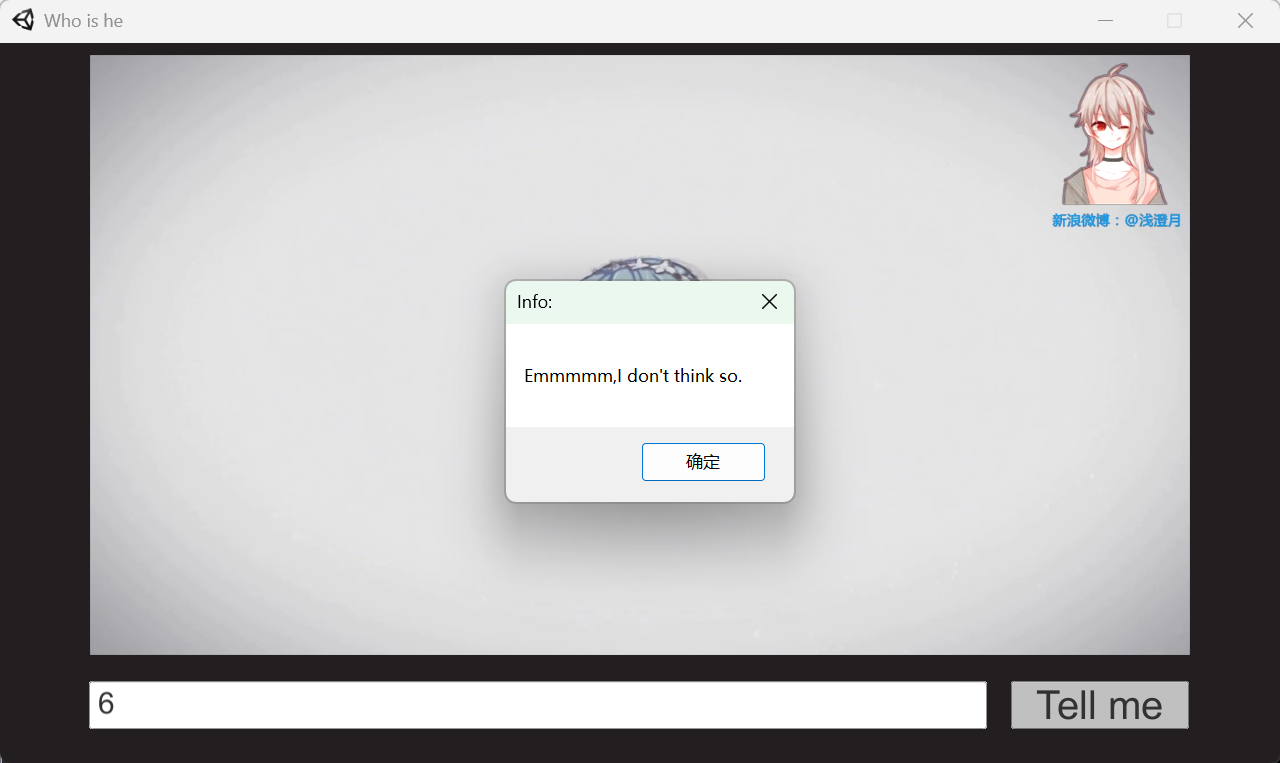
[SCTF2019]Who is he
ai:加密模式是 DES CBC(因为 DESCryptoServiceProvider 默认 CBC),密钥和IV相同
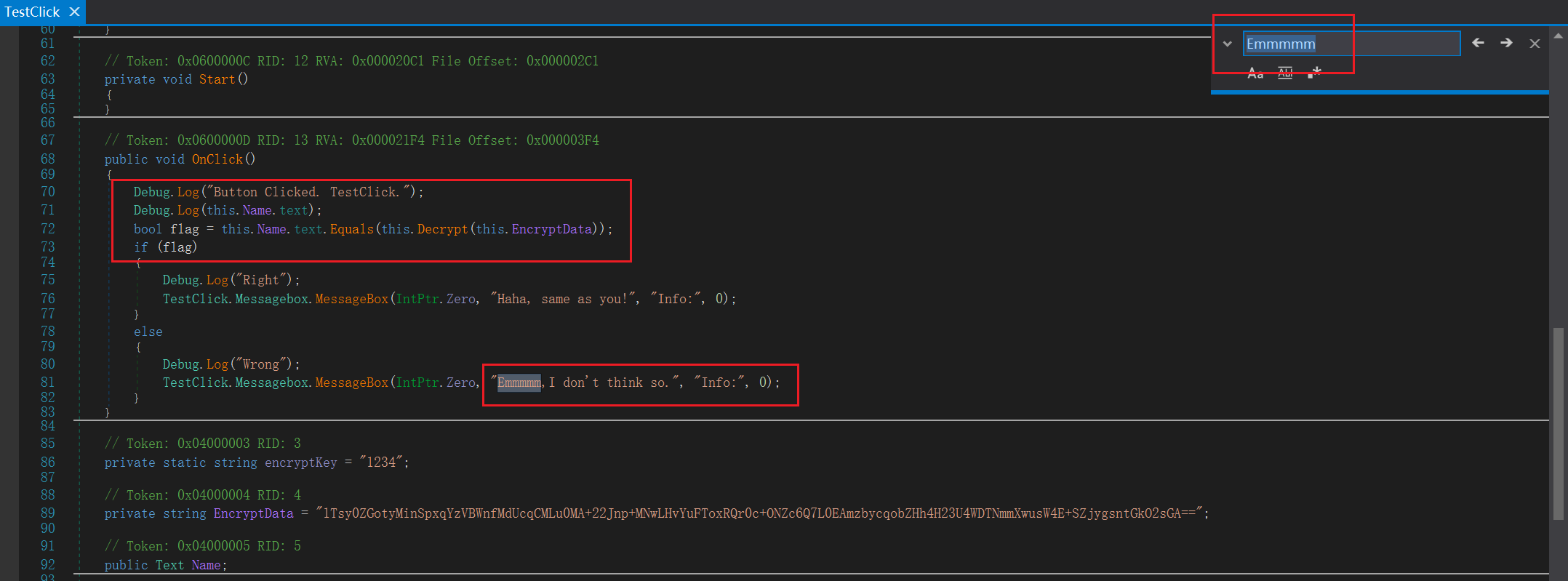
同样的方法,将AssemblyCSarp.dll放入dnSpy里面进行分析,里面密文和key都有
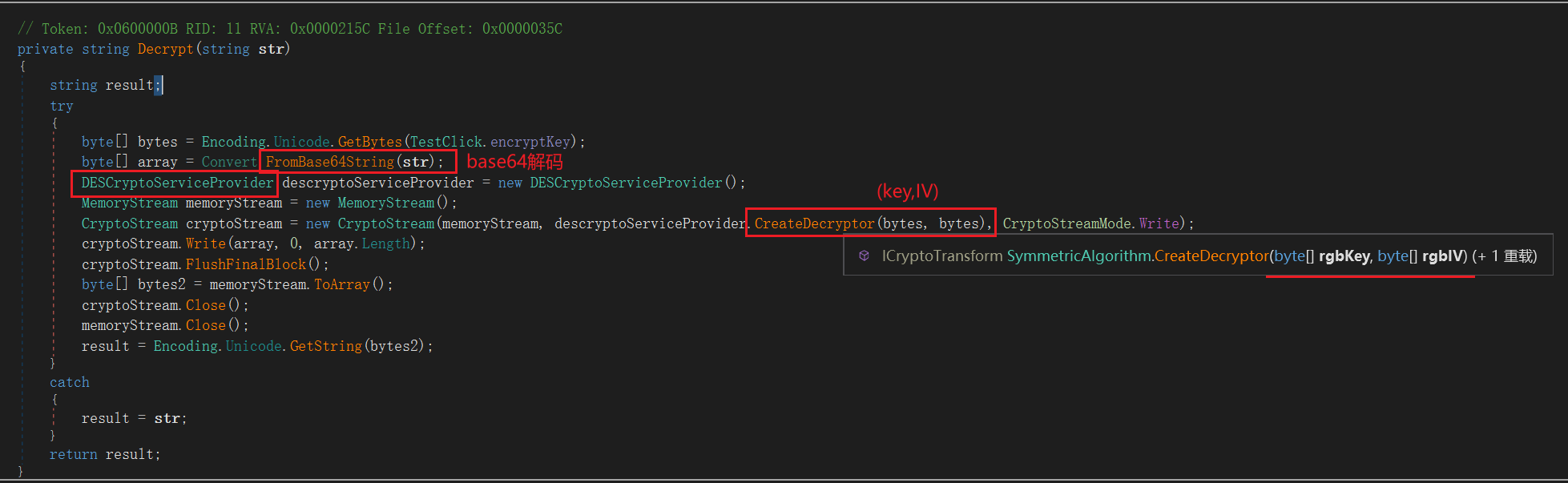
这个解密过程是先进行base64解密,然后再进行DES-CBC模式解密,其中找不到iv是因为key=iv=”1234”。
如果不指定模式,就是CBC
除非代码中显式设置了 Mode 属性,例如:
descryptoServiceProvider.Mode = CipherMode.ECB;
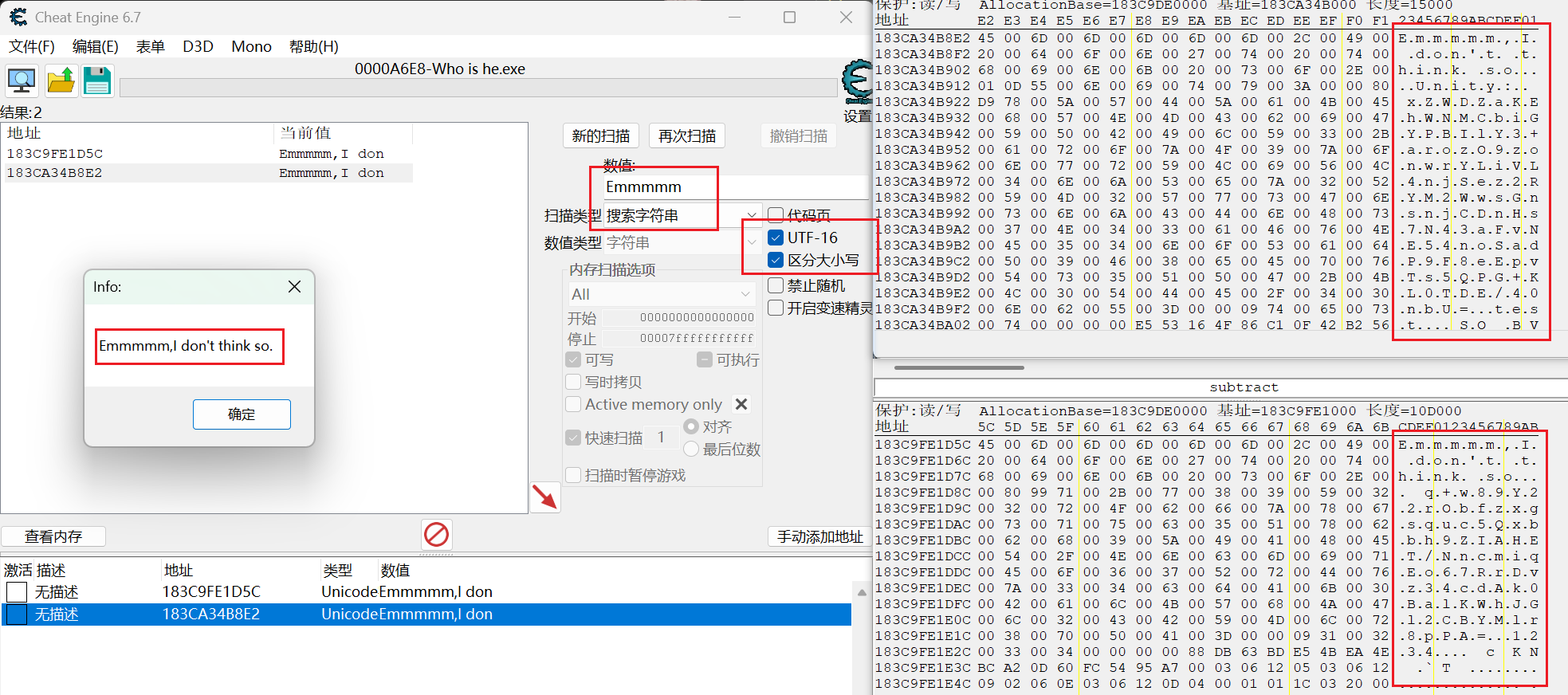
需要注意的是:dnSpy里的字符串是用UTF-16编码存储的,也就是宽字节(双字节) Cheat Engine
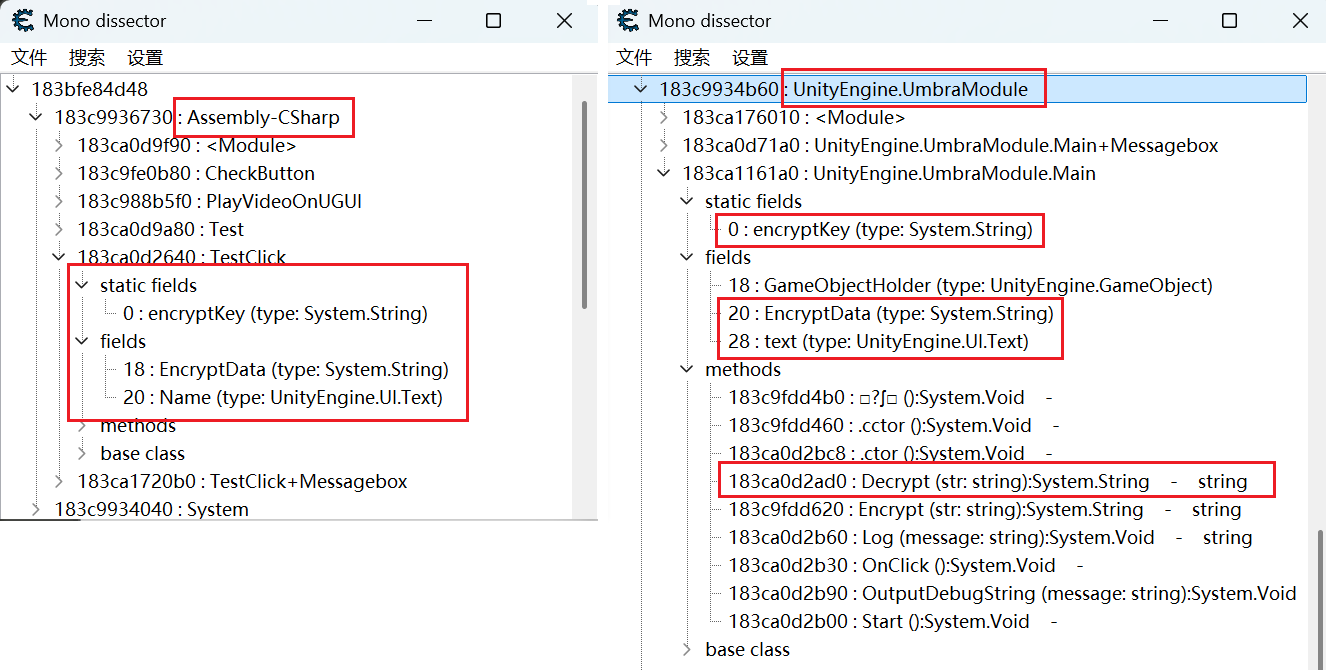
然后打开CE和那个游戏,在CE里选择这个游戏进程,会看到出现了Mono,点击它选择分析Mono。就会看到这些dll,找到刚才可疑的3个dll与AssemblyCSarp.dll对比。
Mono → Dissect mono 打开 “Mono Dissector” 窗口
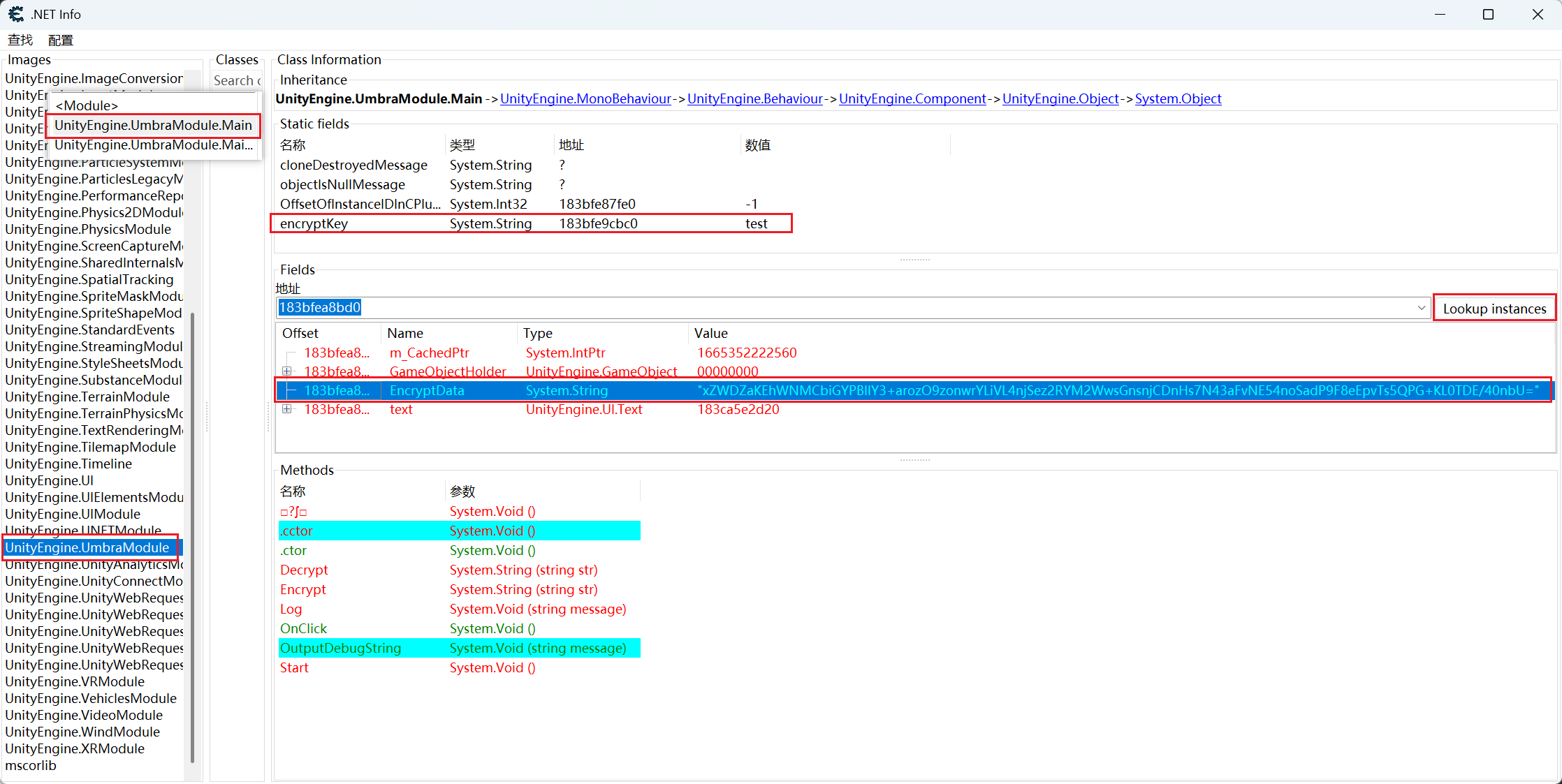
两者对比会发现,真正的密文和key都在UnityEngine.UmbraModule 里面。我们可以换成 Mono ->.Net Info 进行分析,在这里面找到UnityEngine.UmbraModule程序集,里面有个.Main类,打开看看。
第二种方法
两个地址有关分别定位内存中的位置,可以看到这两个真假密文和key
from Crypto.Cipher import DESimport base64enc = "1Tsy0ZGotyMinSpxqYzVBWnfMdUcqCMLu0MA+22Jnp+MNwLHvYuFToxRQr0c+ONZc6Q7L0EAmzbycqobZHh4H23U4WDTNmmXwusW4E+SZjygsntGkO2sGA==" key = b'1\x002\x003\x004\x00' des = DES.new(key, DES.MODE_CBC, iv=key) dec = des.decrypt(base64.b64decode(enc)) print (dec.decode('utf16' ))enc1 = "xZWDZaKEhWNMCbiGYPBIlY3+arozO9zonwrYLiVL4njSez2RYM2WwsGnsnjCDnHs7N43aFvNE54noSadP9F8eEpvTs5QPG+KL0TDE/40nbU=" key1 = b't\x00e\x00s\x00t\x00' aaa = DES.new(key1, DES.MODE_CBC, iv=key1) ddd = aaa.decrypt(base64.b64decode(enc1)) print (ddd.decode('utf16' ))
第三种方法:使用uniref框架解出真的密文
uniref框架:https://github.com/in1nit1t/uniref
uniref 是一个辅助分析 Unity 应用的框架。它可以帮助我们取获取 Unity 应用中的类、方法、成员变量等的反射信息,也可以实时地查看和操作它们。
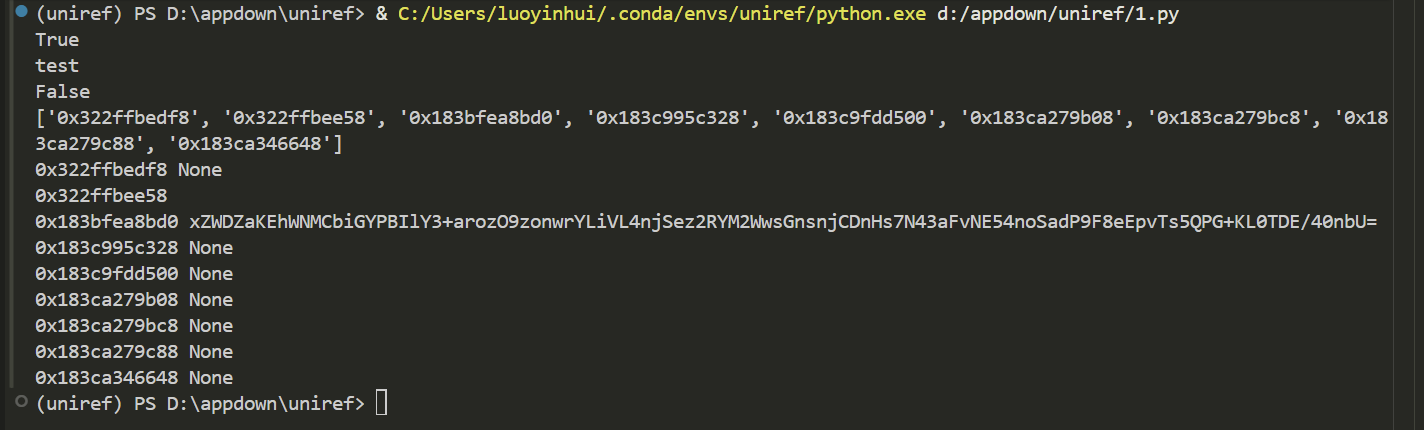
from uniref import WinUniRefref = WinUniRef("Who is he.exe" ) main = ref.find_class_in_image("UnityEngine.UmbraModule" , "UnityEngine.UmbraModule.Main" ) key = main.find_field("encryptKey" ) print (key.is_static()) print (key.value)enc = main.find_field("EncryptData" ) print (enc.is_static()) addresses = main.guess_instance_address() print (list (map (hex , addresses)))for addr in addresses: enc.set_instance(addr) print (hex (addr), enc.value)
IL2CPP 将游戏 C# 代码转换为 C++ 代码,然后编译为各平台 Native 代码。现在市面上的很多游戏基本上都是用Il2cpp的方式打包的。
global-metadata.dat 文件里面记录了所有的 C# 中的类名、方法名、属性名、字符串等地址信息。目前对于il2cpp逆向都以Android中的.so文件居多。
IL2CPP 打包的应用在逆向前会多一步操作,即使用项目 Il2CppDumper 和应用程序目录中的 global-metadata.dat 和 GameAssembly.dll 来获得 dll 的符号信息。之后再通过 IDA 加载 GameAssembly.dll 及符号信息来进行逆向分析(常规 C 语言逆向)。
打开后在Data文件夹 里看到 il2cpp_data ,这就是il2cpp打包的unity游戏。
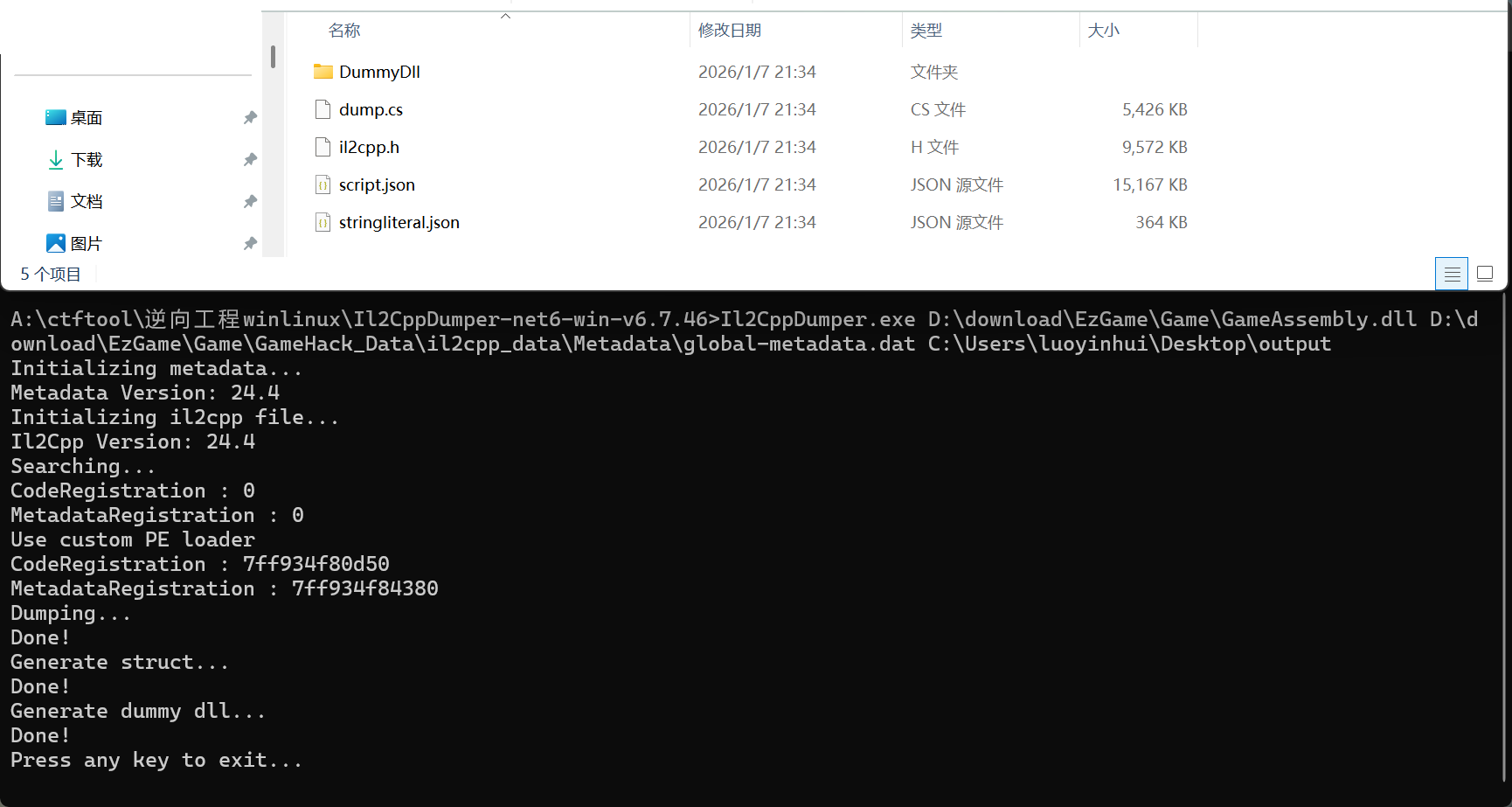
需要的工具:Il2CppDumper 下载使用:https://github.com/Perfare/Il2CppDumper
命令
Il2CppDumper.exe GameAssembly.dll的路径(第一个参数) global-metadata.dat的路径(第二个参数) 输出的路径(第三个参数)
dump.cs :这个文件会把 C# 的 dll 代码的类、方法、字段列出来
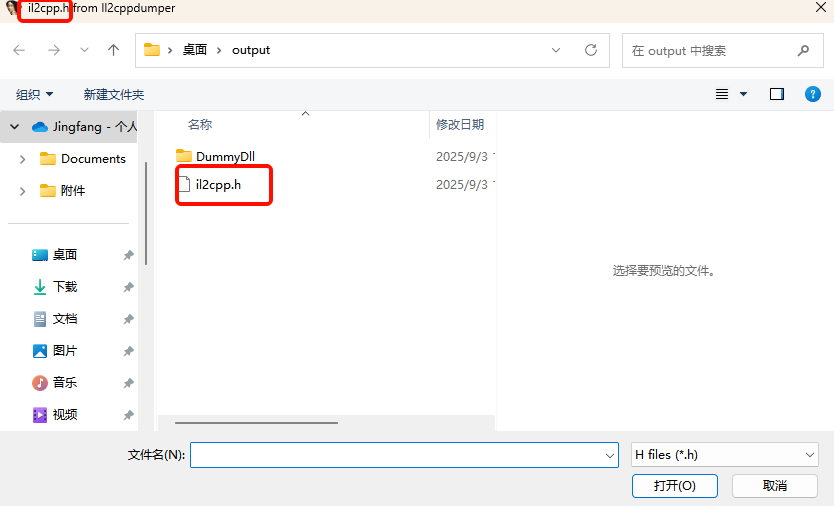
IL2cpp.h :生成的 cpp 头文件,从头文件里可以看到相关的数据结构
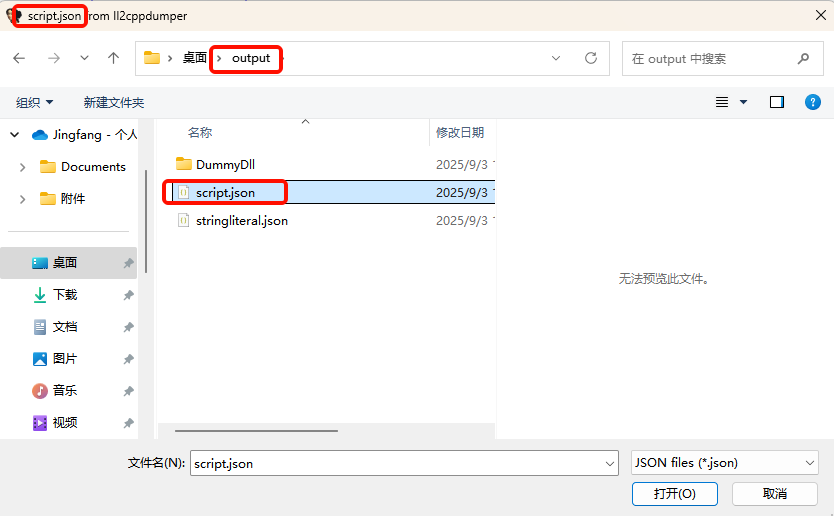
script.json :以 json 格式显示类的方法信息
stringliteral.json :以 json 的格式显示所有字符串信息
DummyDll :进入该目录,可以看到很多dll,其中就有 Assembly-CSharp.dll 和我们刚刚的 dump.cs 内容是一致的
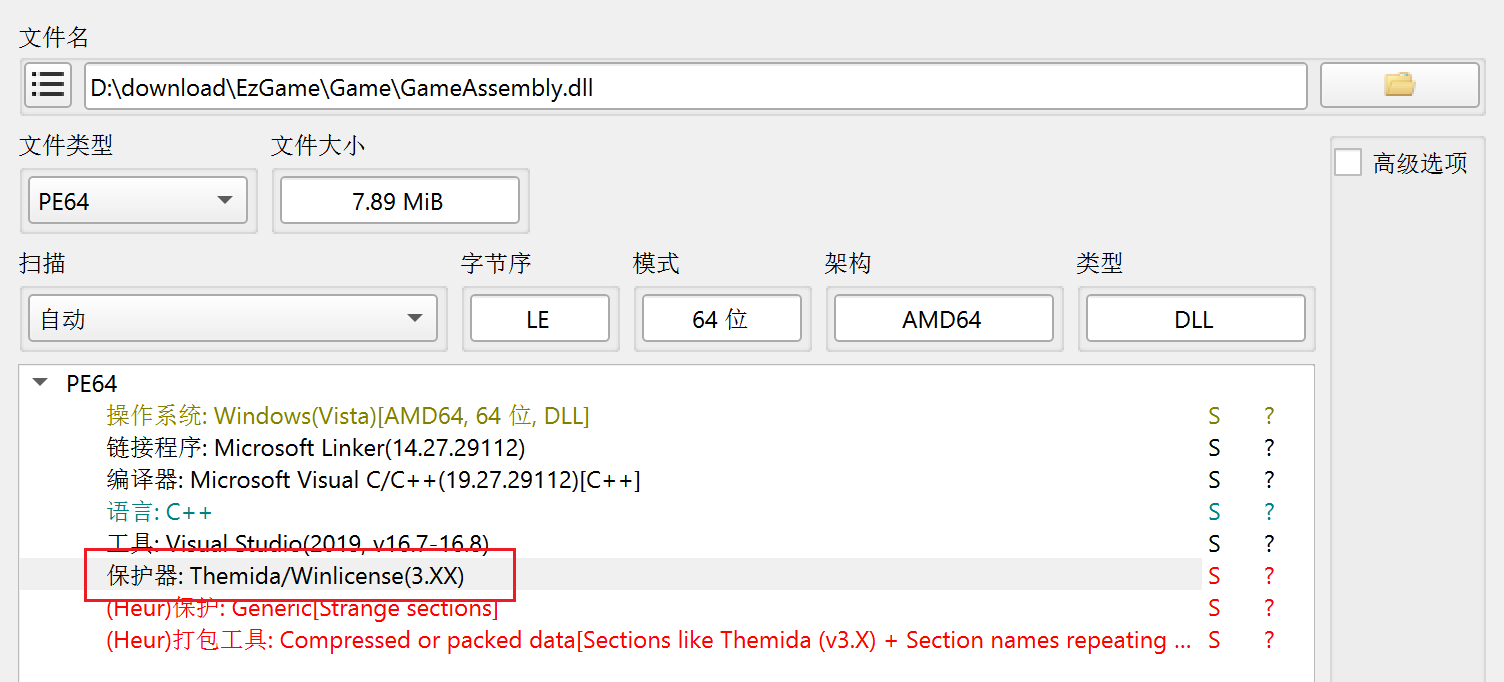
接下来使用IDA来加载 GameAssembly.dll ,但是这个题加了个Themida的壳,很难脱,这个壳是一款商业级的壳,特点是保护强度高,经常被用来保护游戏、外挂、商业软件。
其实到这里这个常规的方法就行不通了,下面是拿这道题来演示一下,常规的流程是什么。
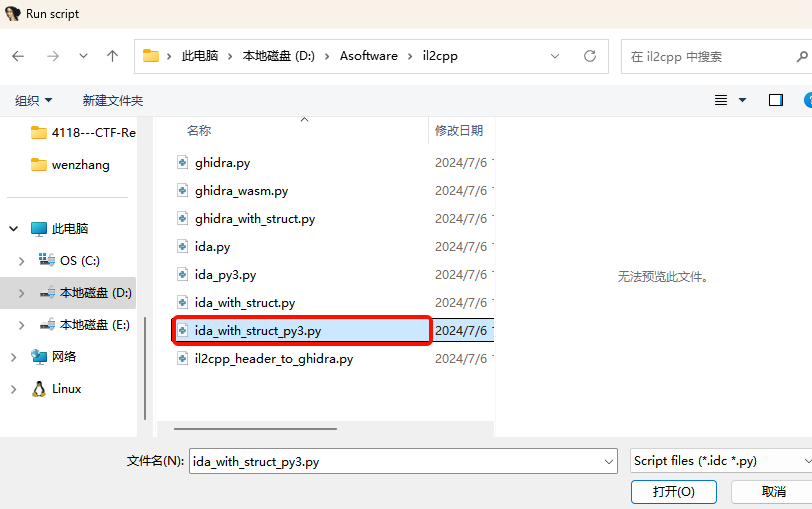
选择 File -> Script file 去应用 ida_with_struct_py3.py文件。
然后选择该文件
再导入头文件
然后就来等待它分析就好了。那这种方法行不通,换CE来看看。
C# 的所有源代码文件,默认编码为 UTF-8,注意,是源代码文件,而不是 C# 中的 string。ASP.NET 源代码,如 ASPX/CS,在浏览器响应回去客户端之后,编码默认为 UTF-8。可以通过 ContentType 请求头信息更改默认编码。比如:ContentType: application/json, charset=utf-8。https://blog.csdn.net/u011127019/article/details/99629697
https://majikoo1028.github.io/2021/04/20/MRCTF-EzGame/ 官方WP 的做法是通过反编译得到得信息结合il2Cpp的API写dll注入脚本来解的
与上一题相同的方法,看到GetFlag很容易猜想到主要逻辑就在这。
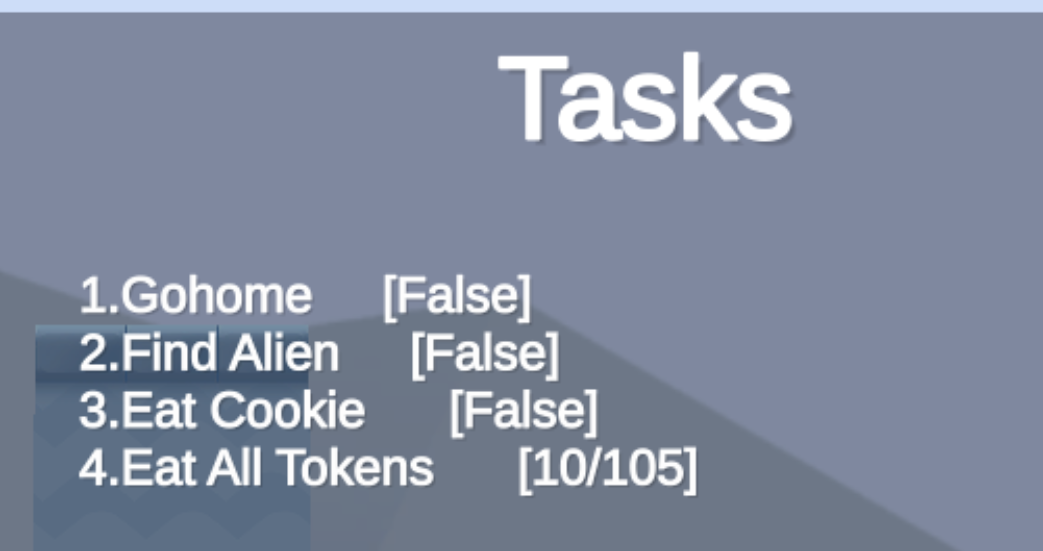
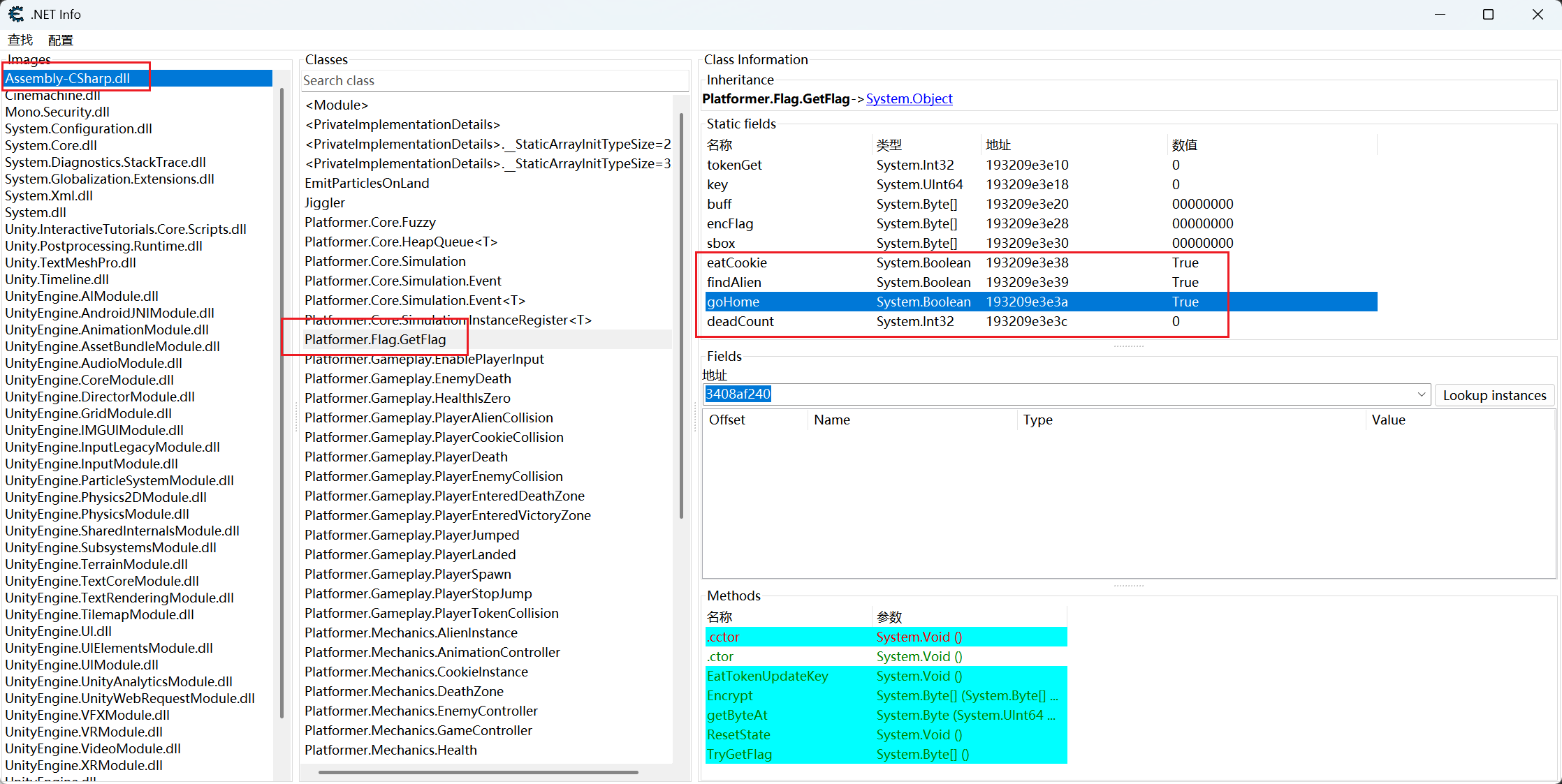
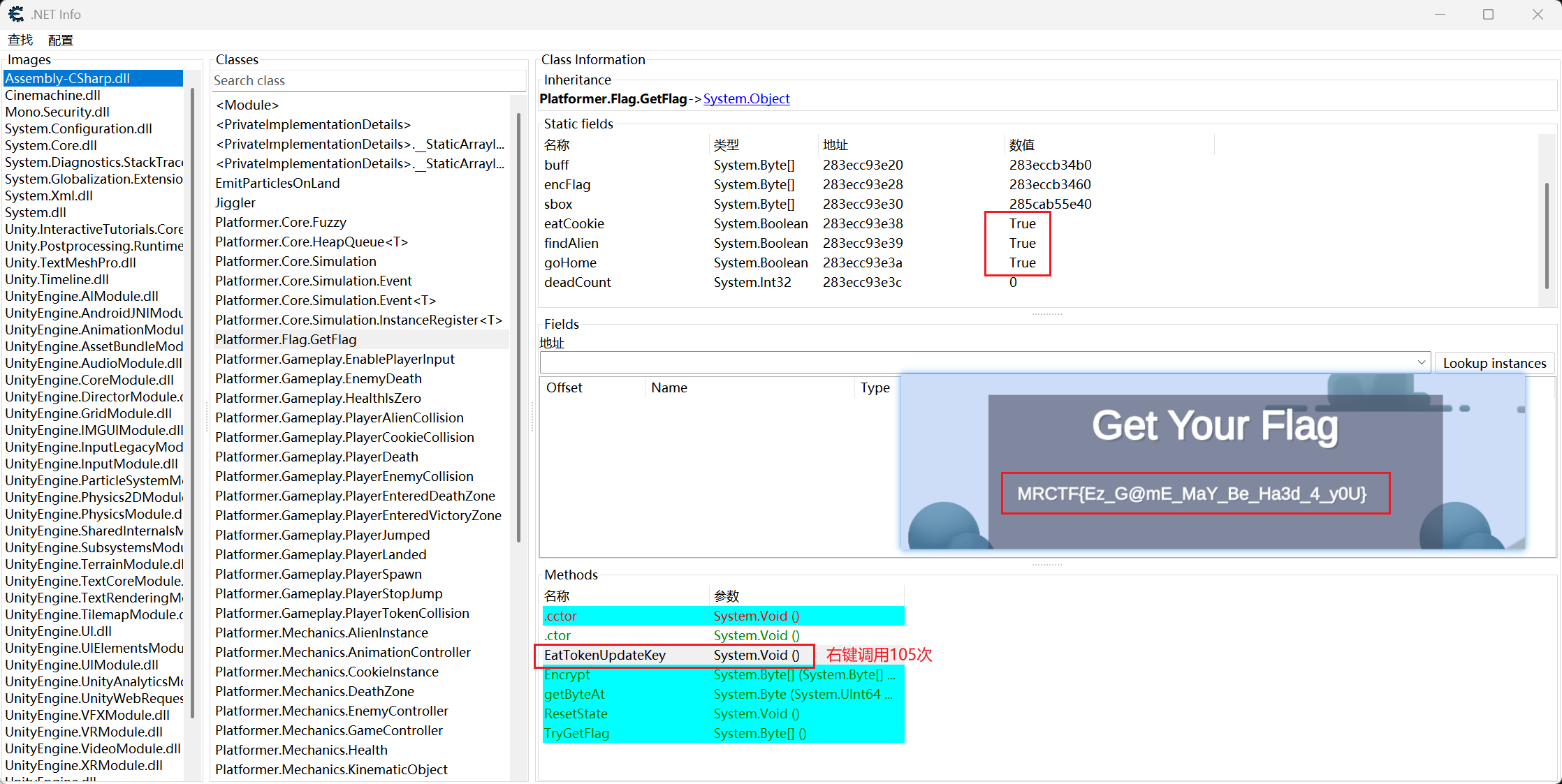
from uniref import WinUniRefref = WinUniRef("GameHack.exe" ) get_flag = ref.find_class_in_image("Assembly-CSharp.dll" , "Platformer.Flag.GetFlag" ) eat_cookie = get_flag.find_field("eatCookie" ) find_alien = get_flag.find_field("findAlien" ) go_home = get_flag.find_field("goHome" ) eat_cookie.value = True find_alien.value = True go_home.value = True update = get_flag.find_method("EatTokenUpdateKey" ) print (update.is_static())for i in range (105 ): update()
这个游戏一打开仅仅就是一个flag验证的程序,逻辑应该比较简单。大概率是 GameAssembly.dll 有壳
无论是Android或者是Windows都能够使用unity引擎进行开发。安卓unity游戏的核心逻辑一般位于 assets\bin\Data\Managed\Assembly-CSharp.dll
使用jeb 打开这个apk文件,直接在找到assets\bin\Data\Managed\Assembly-CSharp.dll 这个位置打开。
使用 .NET 框架提供的编译器可以直接将源程序编译为 .exe 或 .dll 文件,但此时编译出来的程序代码并不是 CPU 能直接执行的机器代码,而是一种中间语言 IL(Intermediate Language)的代码。
这个时候再放入IDA里面进行分析,就不太行了。放入DIE里面查看,出现如下
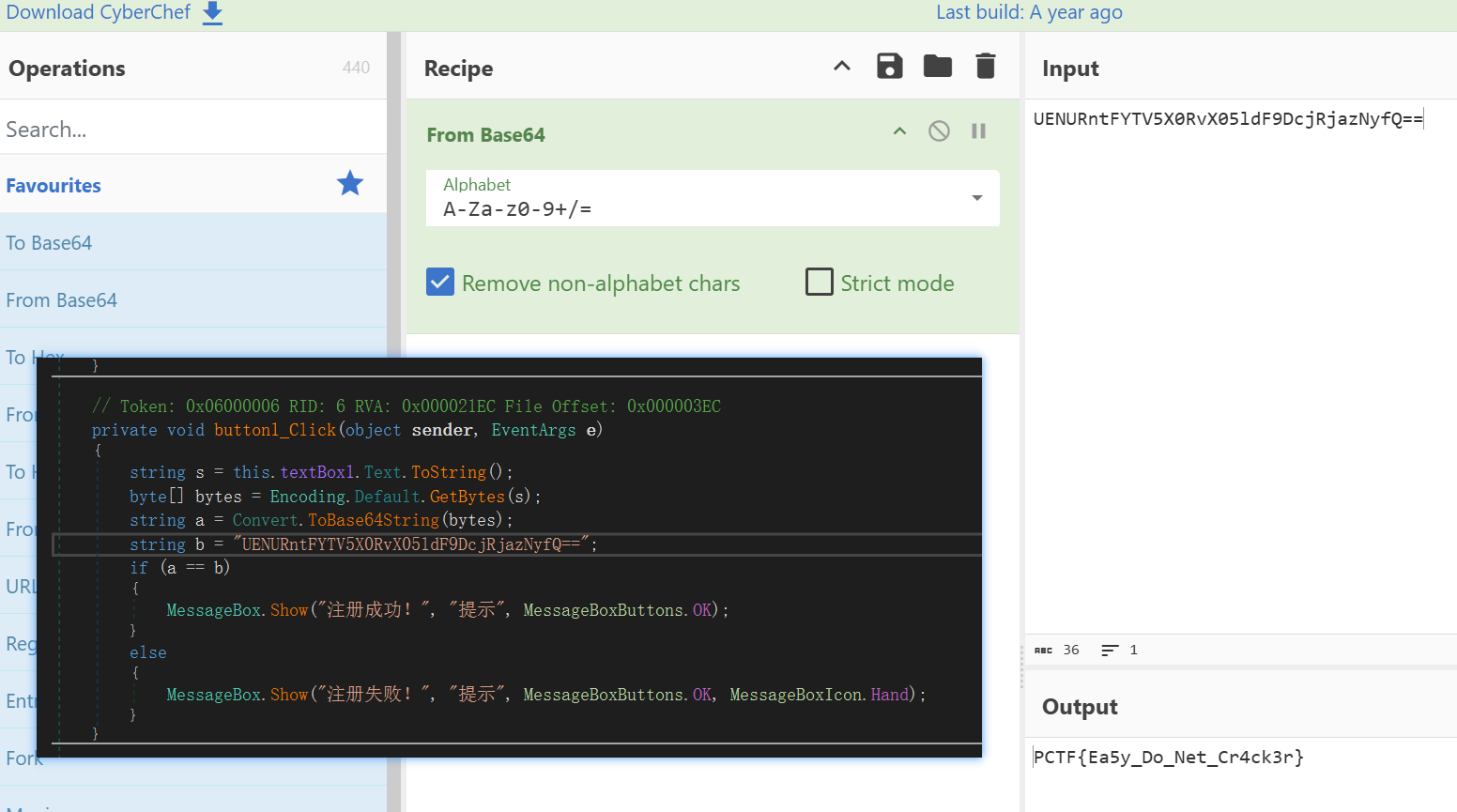
这可以使用新的工具dnSpy ,它是C#逆向的好帮手。
dnSpy 是一个.NET调试器和反编译器,可以在无源码的情况下,进行代码调试和修改。遇到此类题目,我们可以把它放到dnSpy里面进行分析。
运行一下看看
把它放到dnSpy里面进行分析,但是发现本该显示form1的字样的地方成了一串字符,这就加壳混淆了
这个时候需要使用de4dot来帮助,它是是一个很强的.Net程序脱壳,反混淆工具,支持对于以下工具混淆过的代码的清理:如Xenocode、.NET Reactor、MaxtoCode、Eazfuscator.NET 、Agile.NET 、Phoenix Protector、MancoObfuscator 、CodeWall、NetZ .NET Packer 、Rpx .NET Packer、Mpress .NET Packer、ExePack.NET Packer、Sixxpack .NET Packer、Rummage Obfuscator、Obfusasm Obfuscator、Confuser1.7、Agile.NET 、Babel.NET 、CodeFort、CodeVeil、CodeWall、CryptoObfuscator、DeepSea
Obfuscator、Dotfuscator、 Goliath.NET 、ILProtector、MPRESS、Rummage、SmartAssembly、Skater.NET 、Spices.Net 等。
使用方法:直接 de4dot exe所在的位置 就好,会生成一个xxx-cleaned.exe
然后把新的exe再放入dnSpy里面进行分析
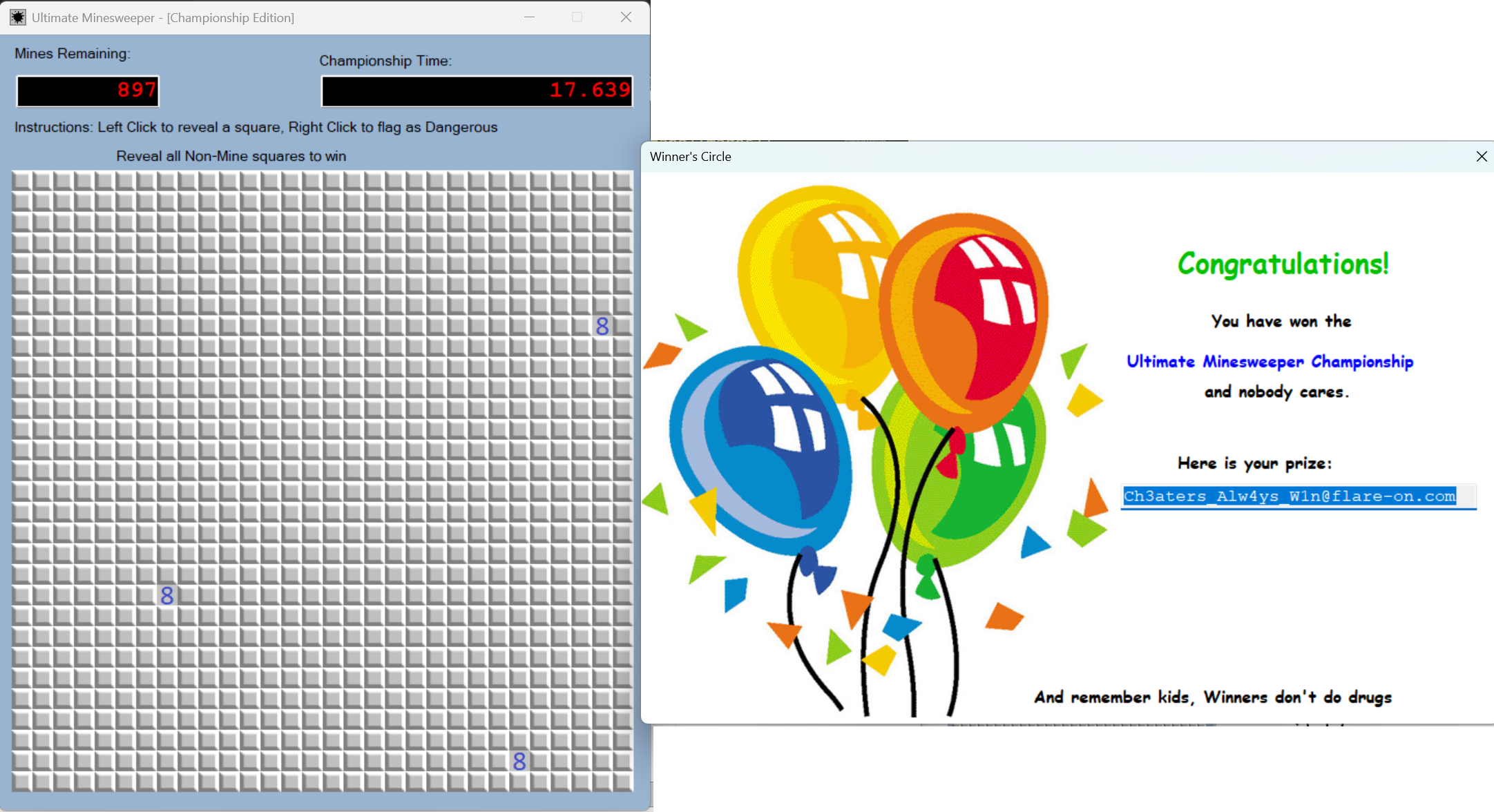
先查壳,无壳32位,是net写的。我们试着运行一下程序,发现是个扫雷游戏,而且这个只要扫到雷就会弹出失败的弹窗然后退出游戏。
把它放到dnSpy里面进行分析,能找到MainForm 部分,这里就是重要部分
里面有GetKey 方法,这应该就是flag的生成逻辑
分析后发现,这从输入 revealedCells生成一个动态伪随机数种子,用于扰乱一个固定的字节数组 array2,最后返回扰乱后的结果字符串,想要逆向过去还是很难的。往上翻看,发现了扫雷的校验逻辑
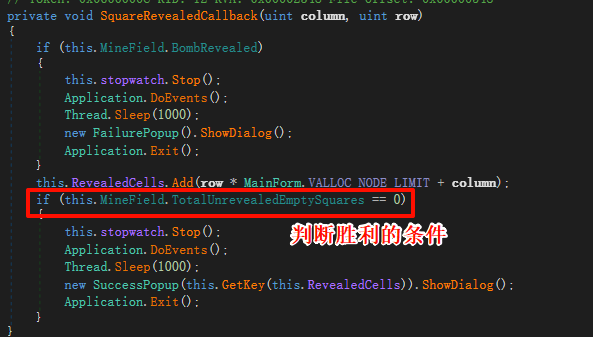
上面红框是扫到雷 后,弹出失败的弹窗并退出游戏,下面的是将所有非雷块都扫了而且没扫到雷 就能通过这个游戏,会调用GetKey方法获取flag弹出胜利弹窗。
第一种方法: 我们只需要把上面扫到雷的失败弹窗部分的代码(也就是红框框住的)都删掉,然后保存,就能一直扫雷不会弹出失败弹窗,也不会退出了。然后记住正确的位置,再在原来的程序上点击就能顺利通关了。
第二种方法:
TotalUnrevealedEmptySquares 是代表着剩下还没被揭开的”非雷”方块数量
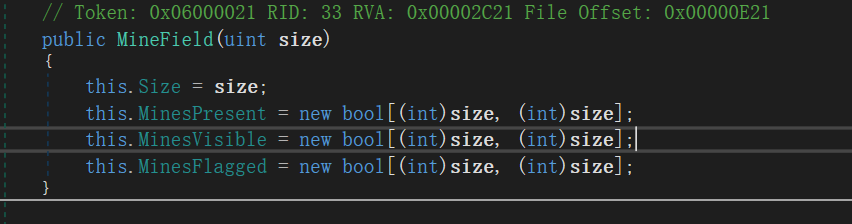
点进去,然后下翻找到初始化棋盘部分,如下所示
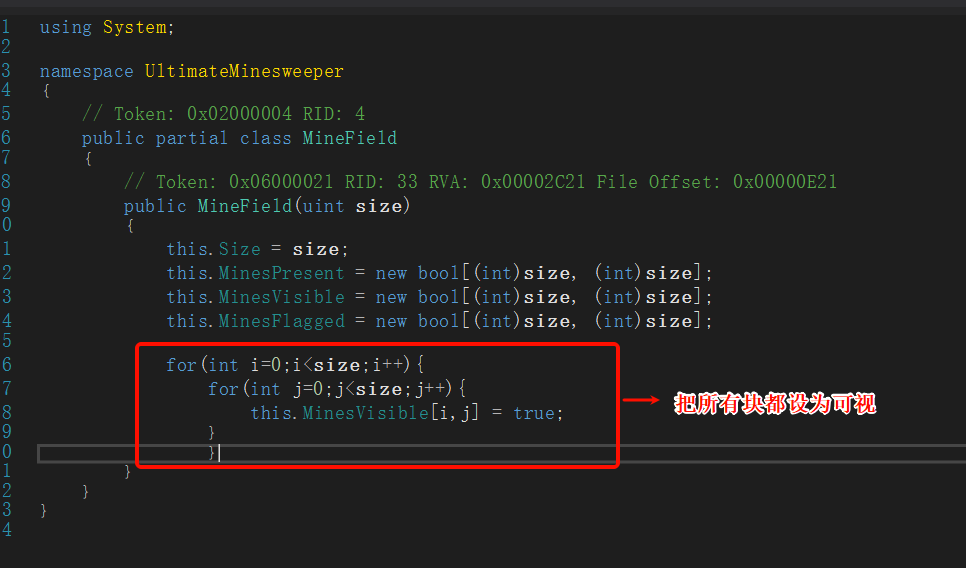
MinesPresent → 存储“是否有雷”。 MinesVisible → 存储“是否被翻开”。 MinesFlagged → 存储“是否被插旗”。
选中这部分后,右键选择编辑方法
using System;namespace UltimateMinesweeper{ public partial class MineField { public MineField (uint size) { this .Size = size; this .MinesPresent = new bool [(int )size, (int )size]; this .MinesVisible = new bool [(int )size, (int )size]; this .MinesFlagged = new bool [(int )size, (int )size]; for (int i =0 ;i<size;i++){ for (int j=0 ;j<size;j++){ this .MinesVisible[i,j] = true ; } } } } }
true代表可视,false代表不可视。初始化全部都是false。这个是遍历所有方块都改成true。然后点击编译就🆗了。
最后保存模块 ,打开就透明可视了。
识别pyc文件
法一:03 F3 0D 0A |3B 0C 0D 0A |4F 0C 0D 0A |6C 0C 0D 0A |9E 0C 0D 0A |EE 0C 0D 0A |17 0D 0D 0A |33 0D 0D 0A |42 0D 0D 0A |55 0D 0D 0A |61 0D 0D 0A |6F 0D 0D 0A |A7 0D 0D 0A |CB 0D 0D 0A |
法二:魔数识别脚本
第二种,先下载pyinstxtractor.py工具(工具箱里面有嘿嘿嘿),可以从网上搜索并自行下载,安装uncompyle库,使用pip命令安装。在cmd中输入命令。uncompyle6 文件名.pyc > 文件名.py
decompyle3 -o output.py input.pyc但是output.py必须存在再运行
pycdc -o output.py main.pyc终极大法:https://pylingual.io/
die看到语言是Python,打包工具是Pylnstaller,就是考察exe转pyc,转pypython pyinstxtractor.py 文件名.exe 再回车一下,
from z3 import *a1 = [Int(f'a{i} ' ) for i in range (10 )] constraints = [ ] solver = Solver() solver.add(constraints) if solver.check() == sat: m = solver.model() flag_inner = '' .join(chr (m[ai].as_long()) for ai in a1) print ('flag:' , flag_inner) ''' import struct if solver.check() == sat: m = solver.model() x = [m[ai].as_long() for ai in a] print('Raw values:', x) print('Hex:', [hex(v) for v in x]) # 整数打包多个字符时 byte_data = b''.join(struct.pack('<I', value) for value in x) result_string = byte_data.decode('ascii', errors='ignore') print('Flag (struct):', result_string) ''' else : print ('no ans!' )
一阶命题逻辑公式由项(变量或常量)与扩展布尔结构组成,在 z3 当中我们可以通过如下方式创建变量实例:
整型
>>> import z3>>> x = z3.Int(name = 'x' )
实数类型
>>> y = z3.Real(name = 'y' )
位向量
>>> z = z3.BitVec(name = 'z' , bv = 32 )
布尔类型
>>> p = z3.Bool(name = 'p' )
整型与实数类型变量之间可以互相进行转换:
>>> z3.ToReal(x)ToReal(x) >>> z3.ToInt(y)ToInt(y)
除了 Python 原有的常量数据类型外,我们也可以使用 z3 自带的常量类型参与运算:
>>> z3.IntVal(val = 114514 ) 114514 >>> z3.RealVal(val = 1919810 ) 1919810 >>> z3.BitVecVal(val = 1145141919810 , bv = 32 ) 2680619074 >>> z3.BitVecVal(val = 1145141919810 , bv = 64 ) 1145141919810
x = Int('x' ) y = Int('y' ) solve(x > 2 , y < 10 , x + 2 *y == 7 )
s = Solver() print (s.check())s.push() s.pop()
>>> s.add(x * 5 == 10 )>>> s.add(y * 1 /2 == x)
对于布尔类型的式子而言,我们可以使用 z3 内置的 And()、Or()、Not()、Implies()蕴含 、if、==(等价)等方法进行布尔逻辑运算:
诶呀太有意思了前面逻辑学的居然还能用上~~
>>> s.add(z3.Implies(p, q))>>> s.add(r == z3.Not(q))>>> s.add(z3.Or(z3.Not(p), r))
If(布尔条件, 条件为真时的值, 条件为假时的值)
simplify()简化约束
x = Int('x' ) y = Int('y' ) print (simplify(x + y + 2 *x + 3 ))print (simplify(x < y + x + 2 ))print (simplify(And(x + 1 >= 3 , x**2 + x**2 + y**2 + 2 >= 5 )))
from z3 import *x, y = Bools('x y' ) solver.add(And(x, y)) solver.add(Or(x, y)) solver.add(Not(x)) a, b = BitVecs('a b' , 32 ) bitwise_and = a & b bitwise_or = a | b bitwise_not = ~a
使用 check() 方法检查约束是否是可满足的z3.sat :约束可以被满足z3.unsat :约束无法被满足
若约束可以被满足,则我们可以通过 model() 方法获取到一组解:
>>> s.model()[q = True , p = False , x = 2 , y = 4 , r = False ]
x = Int('x' ) y = Int('y' ) n = x + y >= 3 print ("num args: " , n.num_args())print ("children: " , n.children())print ("1st child:" , n.arg(0 ))print ("2nd child:" , n.arg(1 ))print ("operator: " , n.decl())print ("op name: " , n.decl().name())
s = Solver() print (s.assertions()) print (s.statistics())
from z3 import *x = Real('x' ) solve(3 *x == 1 ) set_option(rational_to_decimal=True ) solve(3 *x == 1 ) set_option(precision=30 ) solve(3 *x == 1 ) print (len ('0.333333333333333333333333333333?' ))
z3中最好不要使用python原生浮点会引入二进制近似误差
print (1 /3 ) print (RealVal(1 )/3 ) print (Q(1 ,3 )) x = Real('x' ) print (x + 1 /3 ) print (x + Q(1 ,3 )) print (x + "1/3" ) print (x + 0.25 )
通过加限制让z3代码可以运行
加位宽要注意可能溢出导致答案不一样,这种是没有提示的,慎用
a1 = [BitVec(f'a{i} ' , 16 ) for i in range (20 )] solver = Solver() '''for i in range(20): solver.add(a1[i] >= 32, a1[i] <= 126)'''
后一种是加上字符约束,固定在可见字符范围内,相对来说可靠
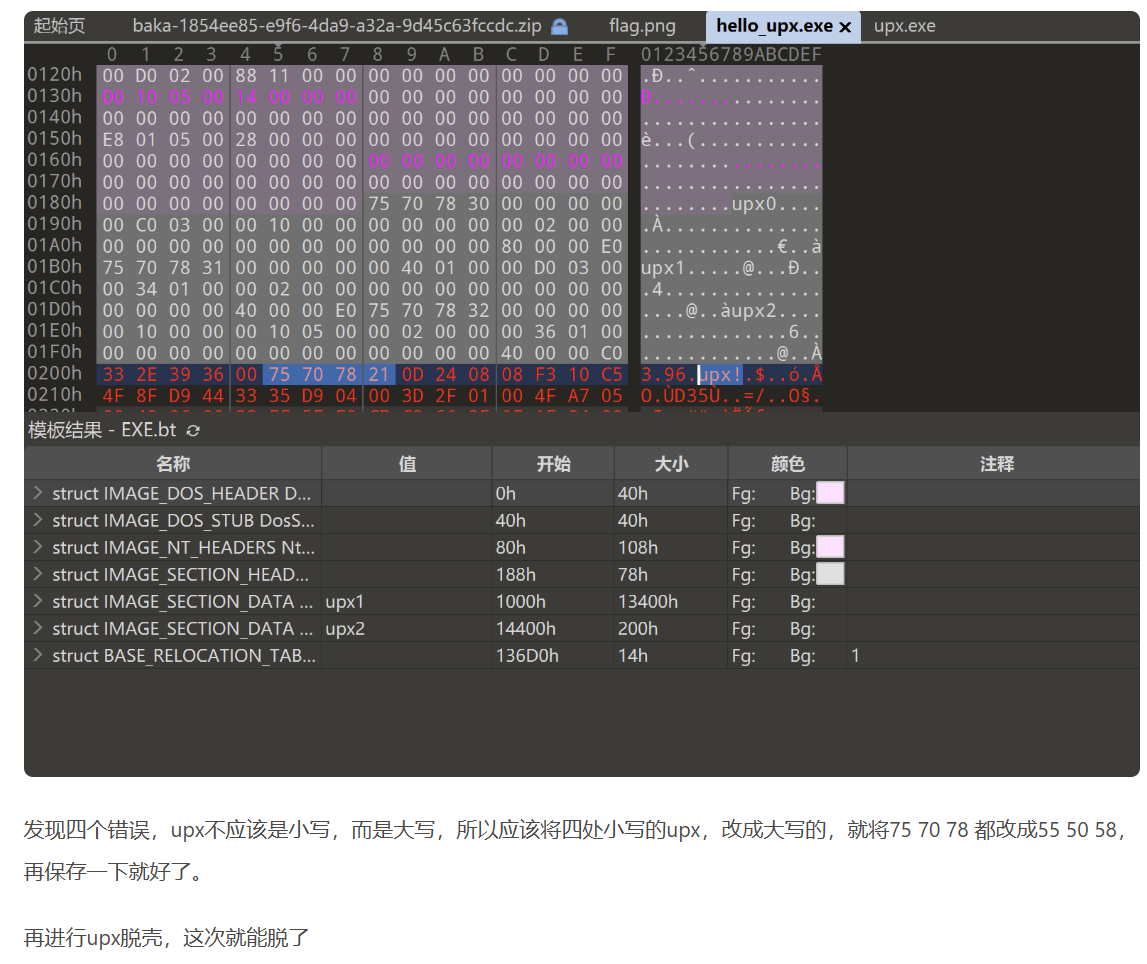
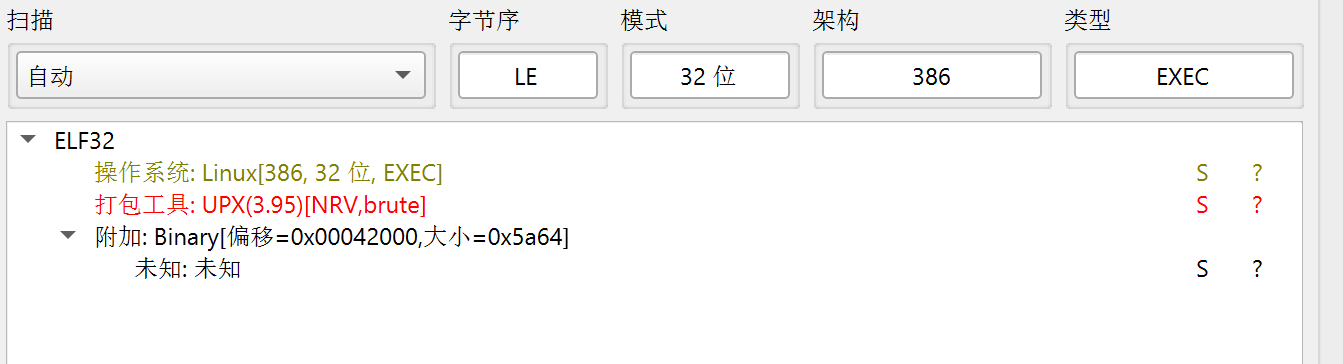
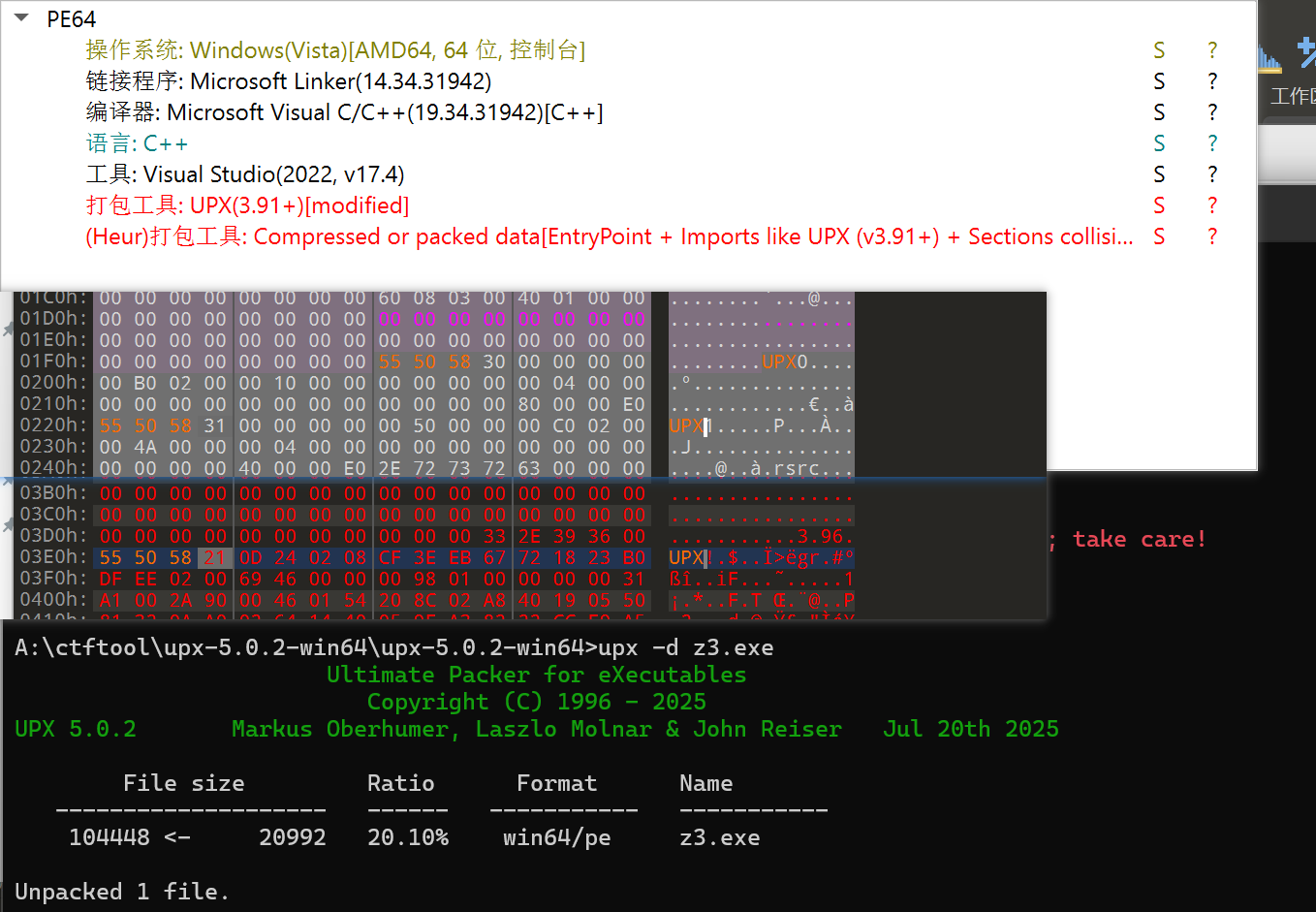
“壳”可以分为两类:压缩壳和加密壳。压缩壳的目的是压缩原程序的体积,很多恶意代码都采用压缩壳,以便于传输。加密壳也称保护壳,是指通过对原程序加密来防止文件被破解。一般而言,加密壳会增加文件的体积。常见的压缩壳包括UPX、ASPack、Nspack(北斗压缩壳)等,常见的加密壳有VMProtect、ASProtect等。所有的压缩壳都能被脱壳,但是加密壳脱壳的难度较大,因此比赛时出现压缩壳问题的概率较大。https://upx.github.io/)
小写的upx,改成大写的,就将75 70 78都改成55 50 58,再保存一下就好了。
>upx -1 要加壳的程序名.exe #更快 >upx -9 要加壳的程序名.exe #更好的压缩率
魔改UPX
修改UPX头
修改入口点
例题:NCTF2023的中文编程2UPX的版本号被抹去 ,那就是文件头被魔改了。这时候手动脱壳依然是有效的,不过有时候太麻烦,所以我们也可以手动把UPX头改回来。010Editor打开文件修改回UPX0、UPX1、UPX(注意在左边改,在右边改会把后面的.覆盖掉)
参考:
分类:
32 位:OllyDbg 脱壳(较简单,可参考网上大量教程)
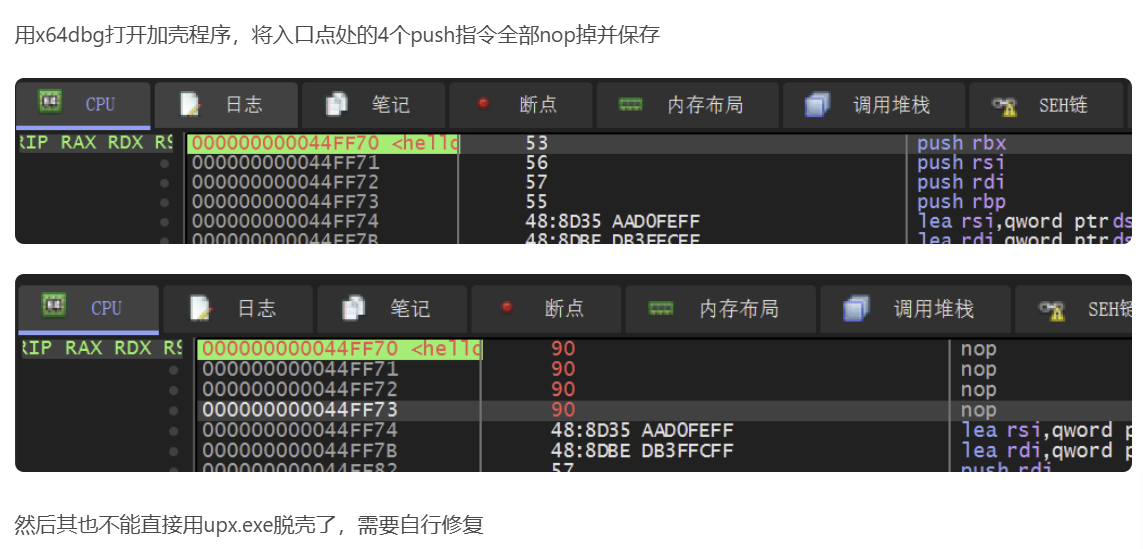
64 位:x64dbg 示例为 [SWPUCTF 2022 新生赛]upx 中的附件(64 位,UPX3.96 壳),可以用工具脱壳。下面尝试手动脱壳。
通过网盘分享的文件:3.手工脱壳.exe 链接: https://pan.baidu.com/s/1Ys1YIsbcS9nyWUYQ94bavw?pwd=njdc 提取码: njdc --来自百度网盘超级会员v8的分享
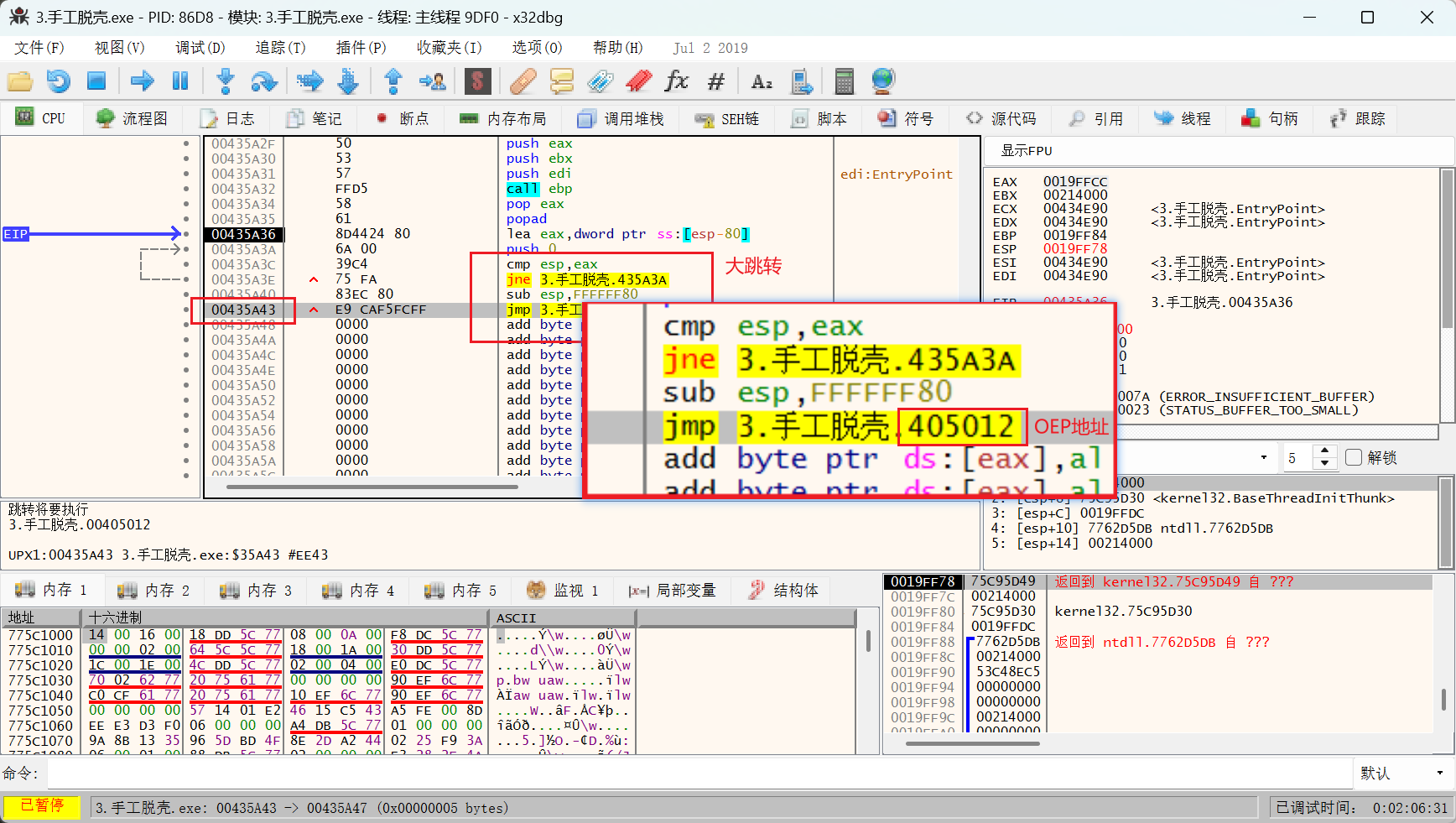
ESP 定律法 是脱壳的利器, 是应用频率最高的脱壳方法之一,它的原理在于利用程序中堆栈平衡来快速找到 OEP。
由于在程序自解密或者自解压过程中,不少壳会先将当前寄存器状态压栈,如使用 pushad,在解压结束后会将之前的寄存器值出栈,如使用 popad。因此在寄存器出栈时,往往程序代码被恢复,此时硬件断点触发。然后在程序当前位置,只需要少许单步操作,就很容易到达正确的 OEP 位置。
程序刚载入开始 pushad/pushfd
将寄存器压栈后就在 ESP/RSP 寄存器所在地址处设硬件访问断点
运行程序,触发断点
找到 pushad 。pushad = 一次性保存所有通用寄存器到栈。有的时候不是pushad,而是一连串的 push 将通用寄存器入栈也是一样的。
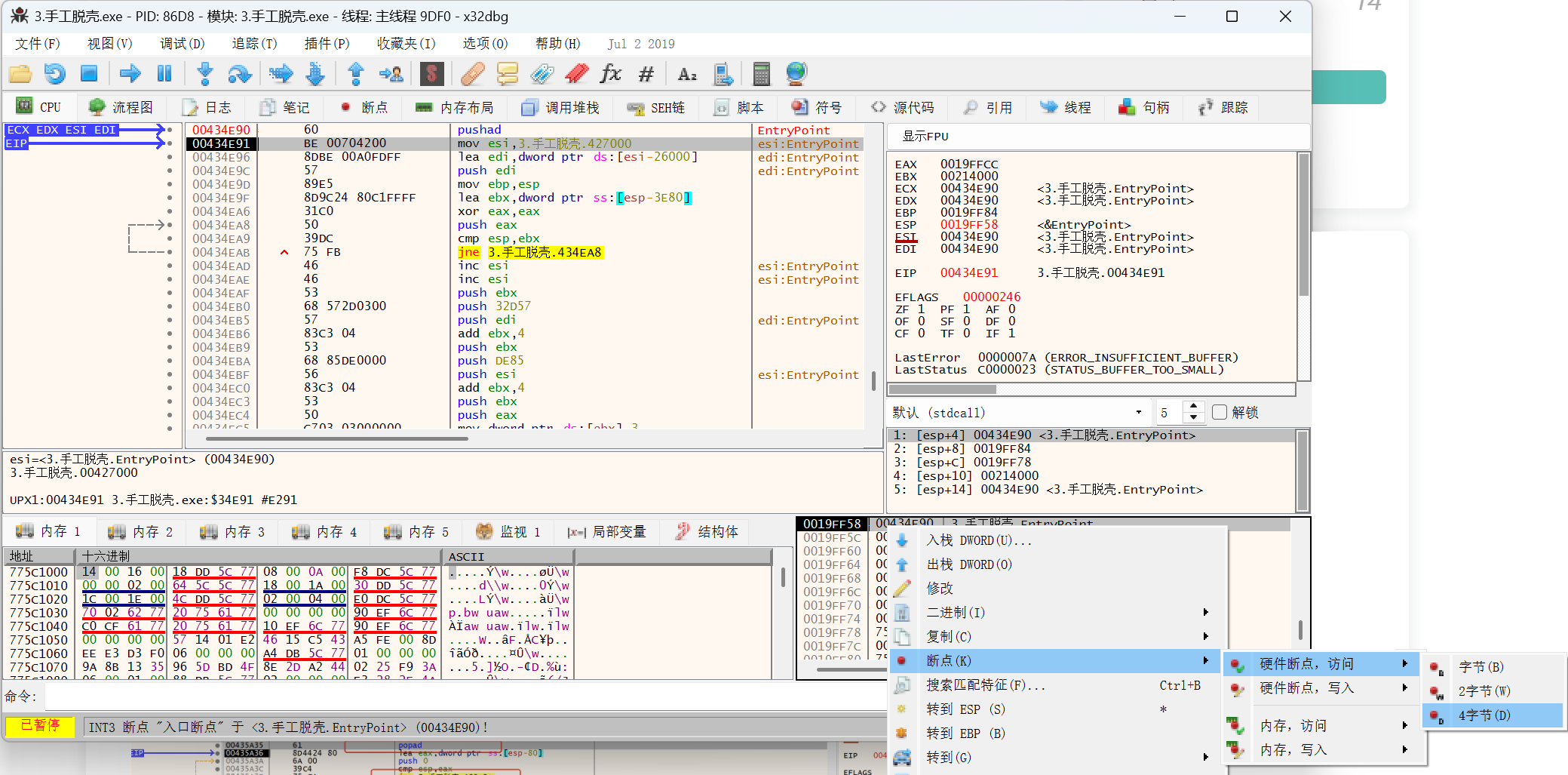
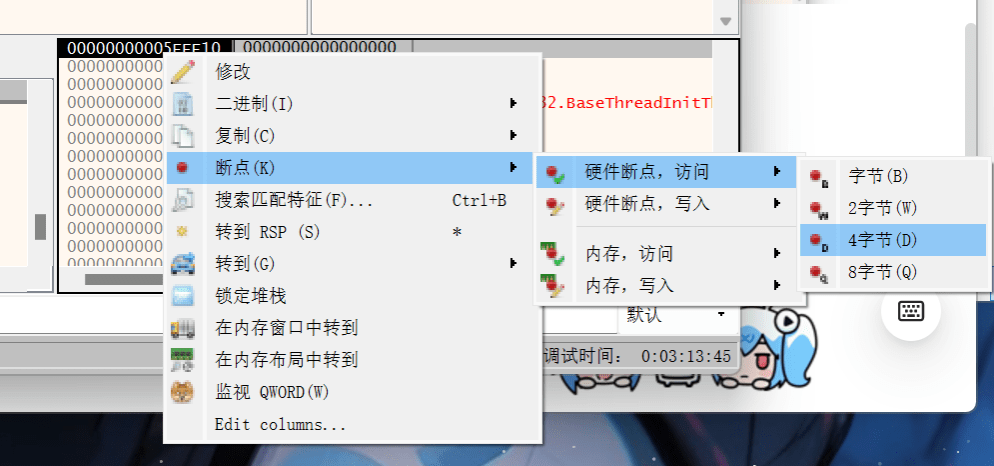
然后在这个地址处设硬件断点,硬件断点,访问 -> 4字节
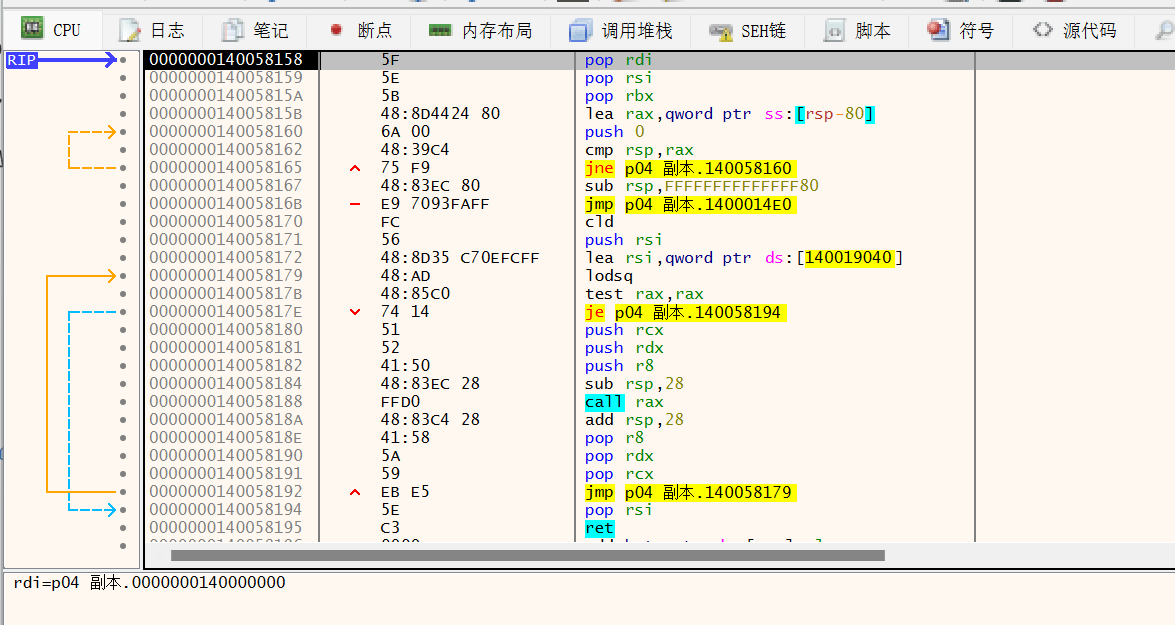
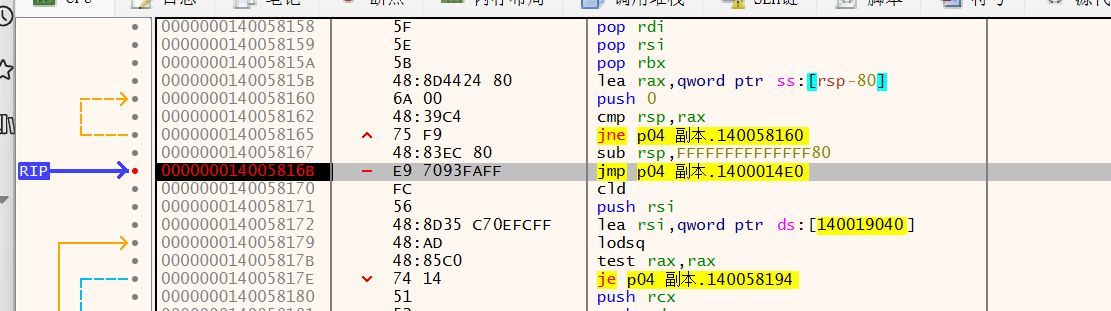
然后直接运行,看到程序跳到 popad,显而易见的程序进行弹栈操作后又进行了jmp 跳转,跳到了比较远的位置,进行大跳转的jump地址就是OEP的所在地址。在这里打上断点直接跟进去,里面就是程序的OEP。
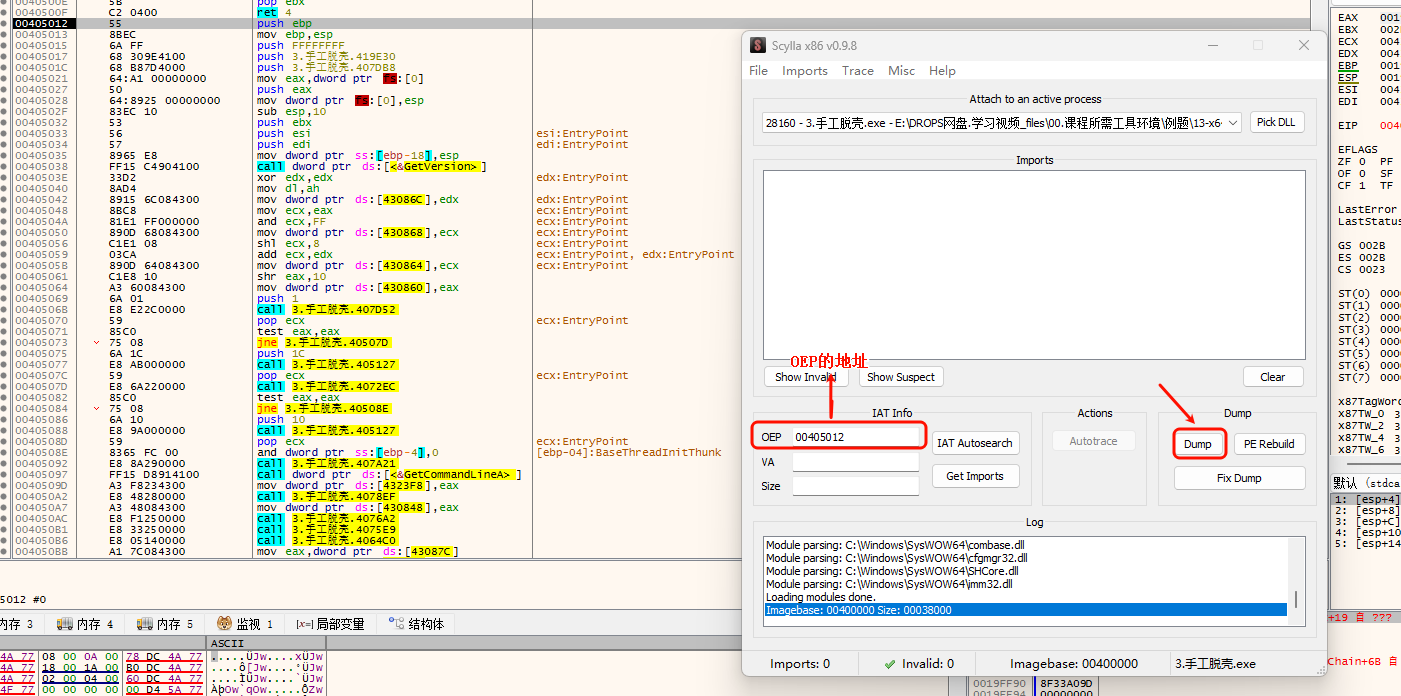
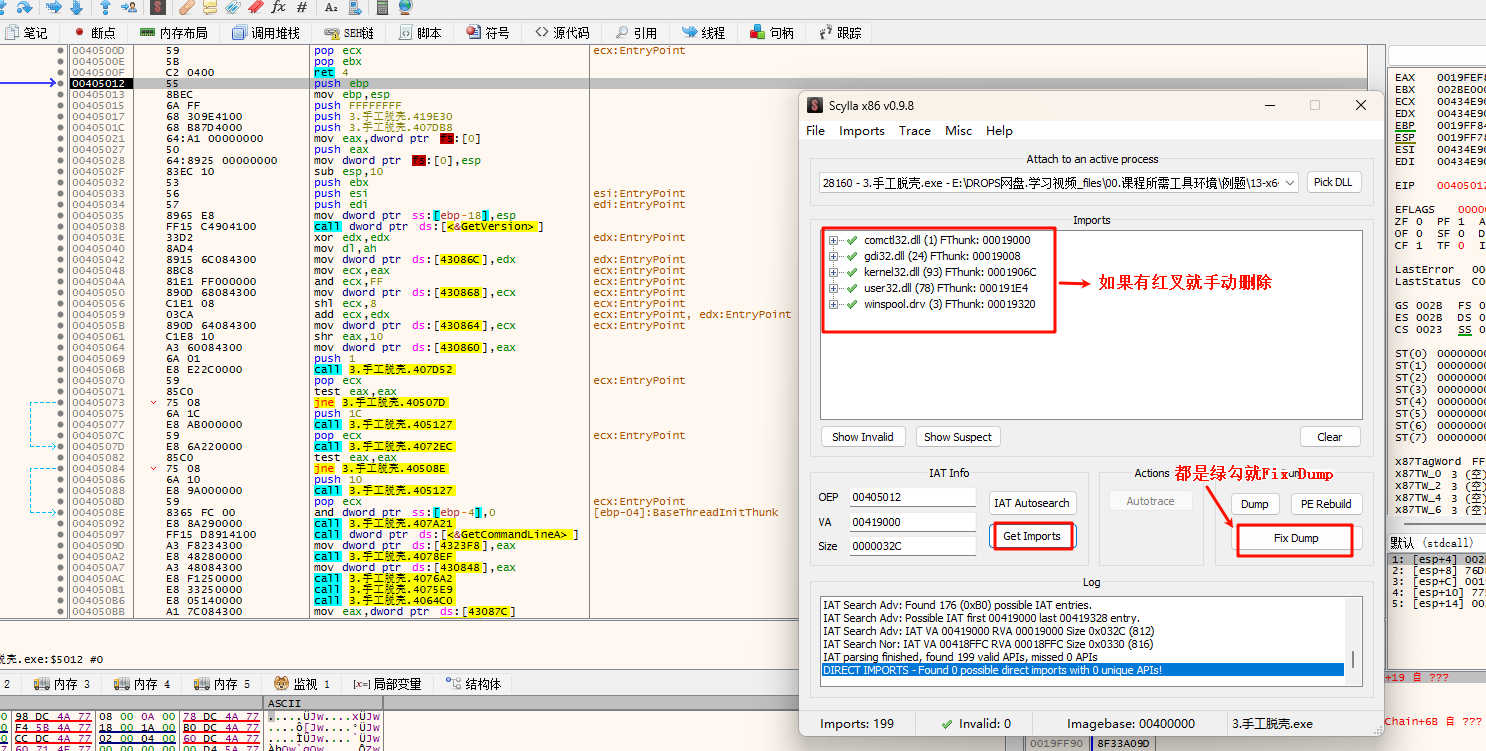
找到 OEP 后,通过 x64dbg 自带的 Scylla 插件即可完成 Dump 及 IAT 修复。在弹出的窗口中点击 Dump,并设置保存路径。
dump 的默认文件名为 原文件名_dump.exe,之后点击 IAT Autosearch,会弹出一个警告:
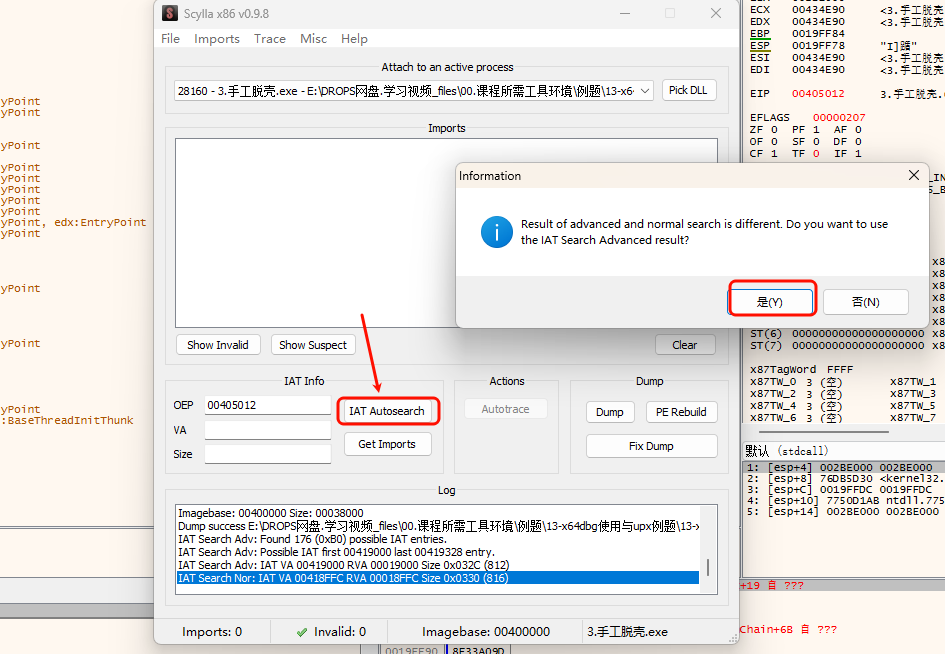
选择 是 后,会显示找到的 IAT 地址及大小:
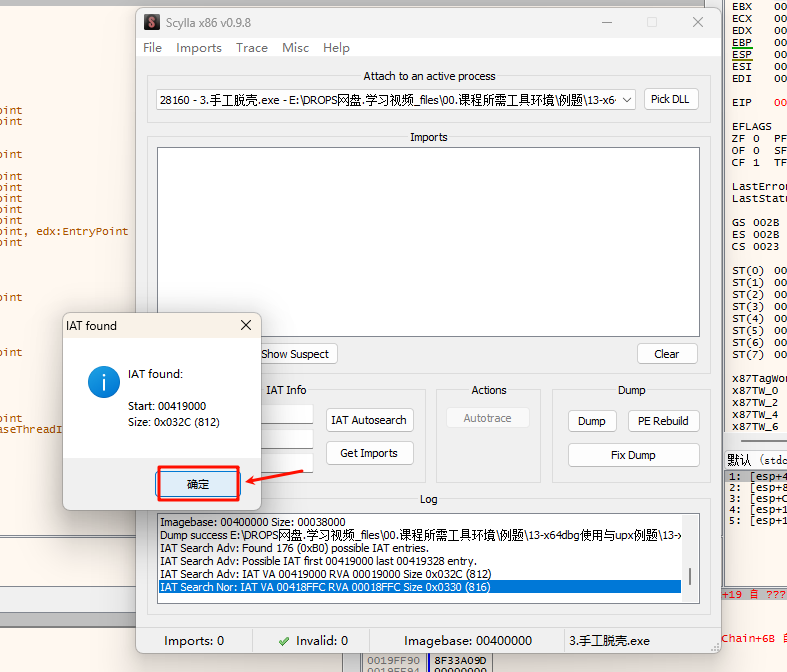
此时再点击 Get Imports,插件会列出找到的所有导入信息,如果有红叉需要手动删除:
接着点击 Fix Dump,选择刚才 dump 的 exe,插件会在同级目录下生成一个新程序 原文件名_dump_SCY.exe。
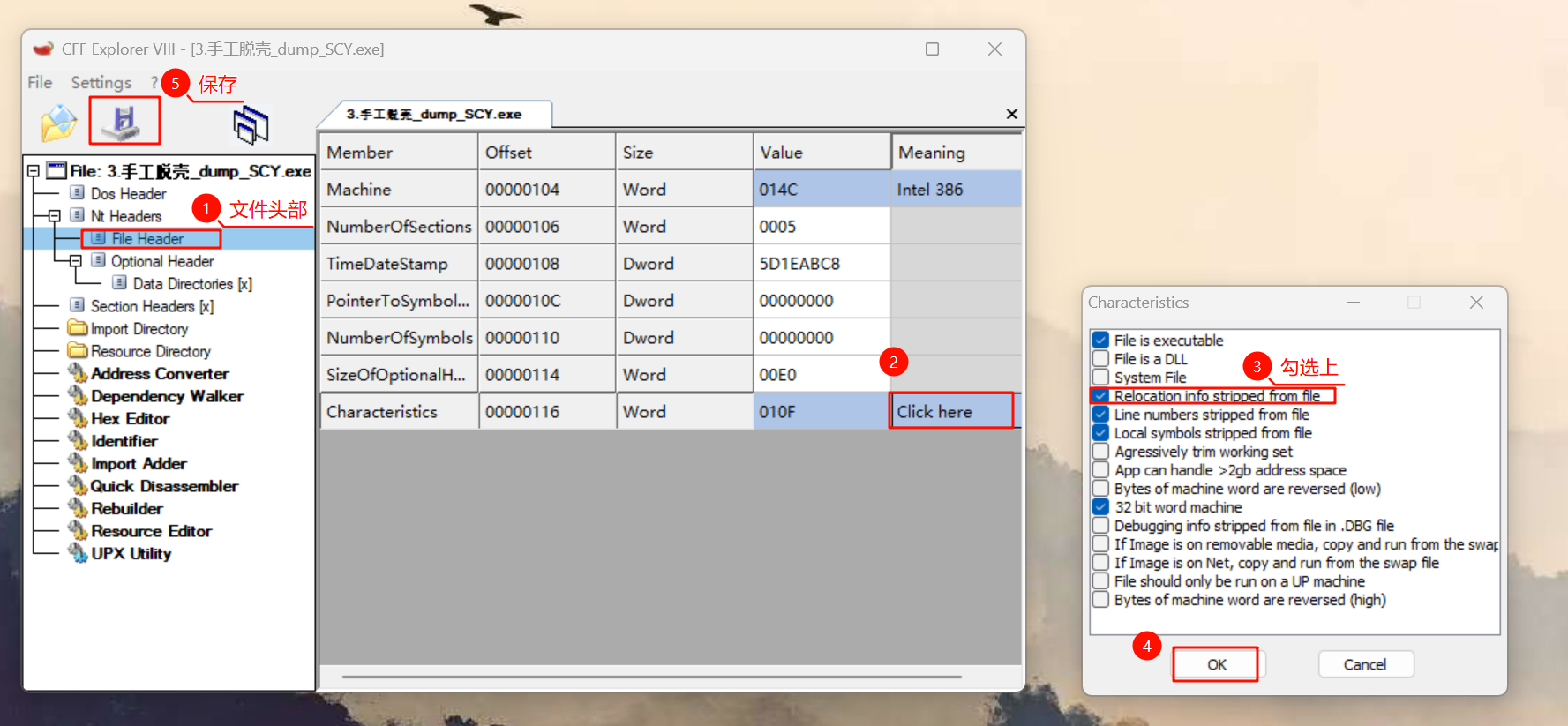
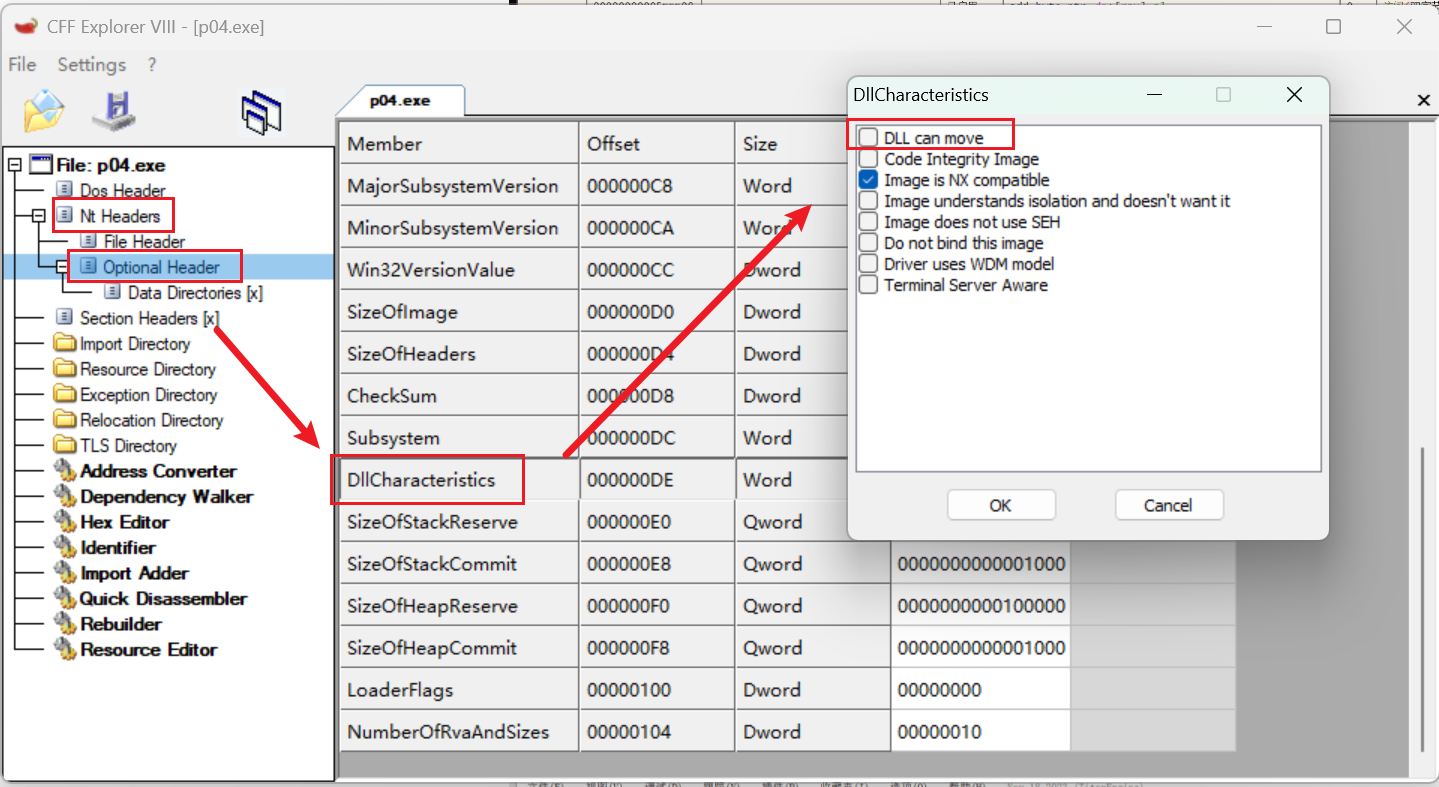
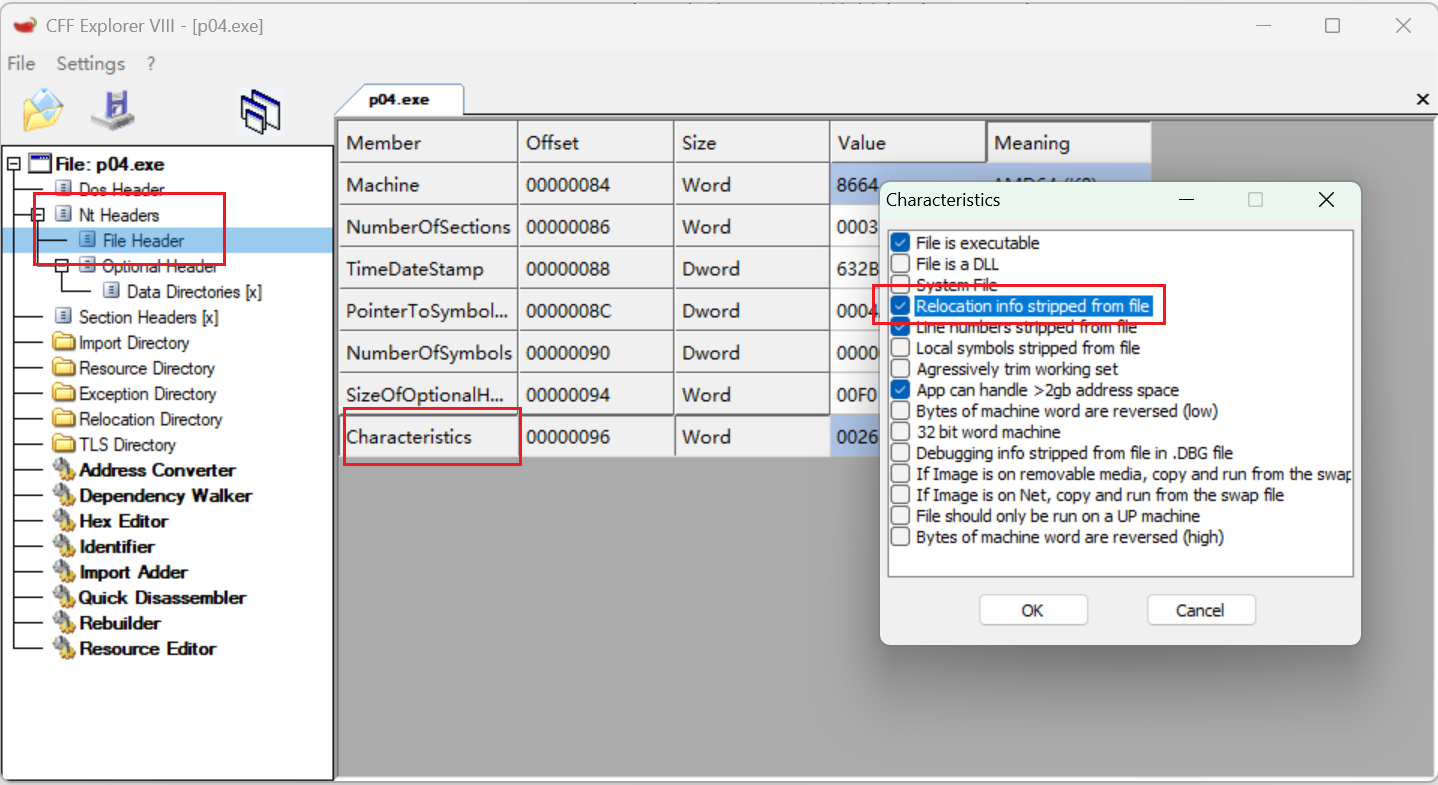
但此时该 exe 可能仍旧不能运行,我们需要修改其 PE 结构中的两个字段值:
File Header 的 Charateristics
Optional Header 的 DllCharateristics
我们可以使用 CFFExplorerVII (小辣椒) 等工具来进行编辑。
首先修改 File Header 的 Charateristics,勾选 Relocation info stripped from file。
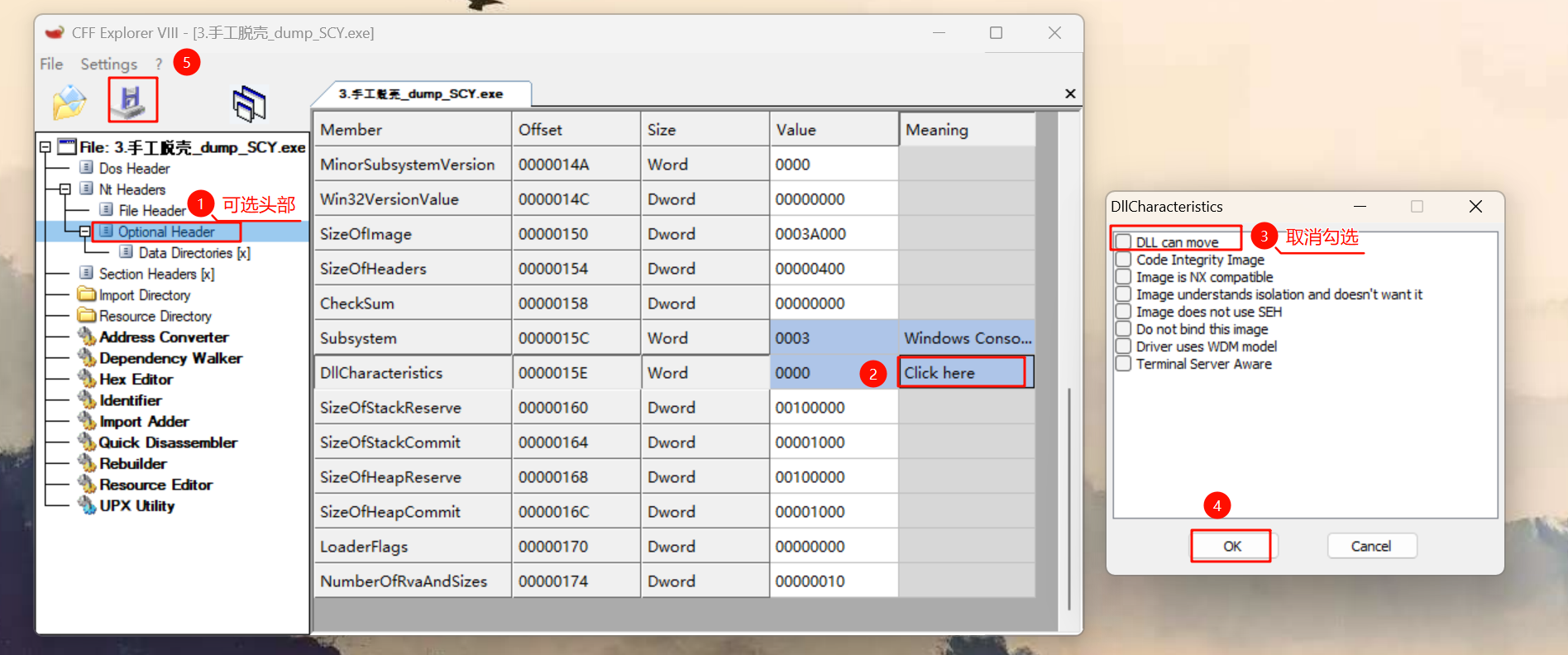
然后修改 Optional Header 的 DllCharateristics,取消勾选 DLL can move。
最后保存就好了,这样UPX壳就去除成功了,使用IDA打开,也能找到main函数
XP后的系统都有ASLR(地址空间随机化),导致dump后程序运行出错,因此我们首先用CFF Explorer修改该文件的Nt Header,禁用ASLR
没看懂原文章这里要进行什么操作,问了ai让我取消勾选option header-dllcharacteristics-dll can move
在Nt Header下的Optional Header里修改Characteristics,勾选Relocation info srtipped from file。关闭后记得保存。
这里原文如上,肯定写错了,在file header里面改
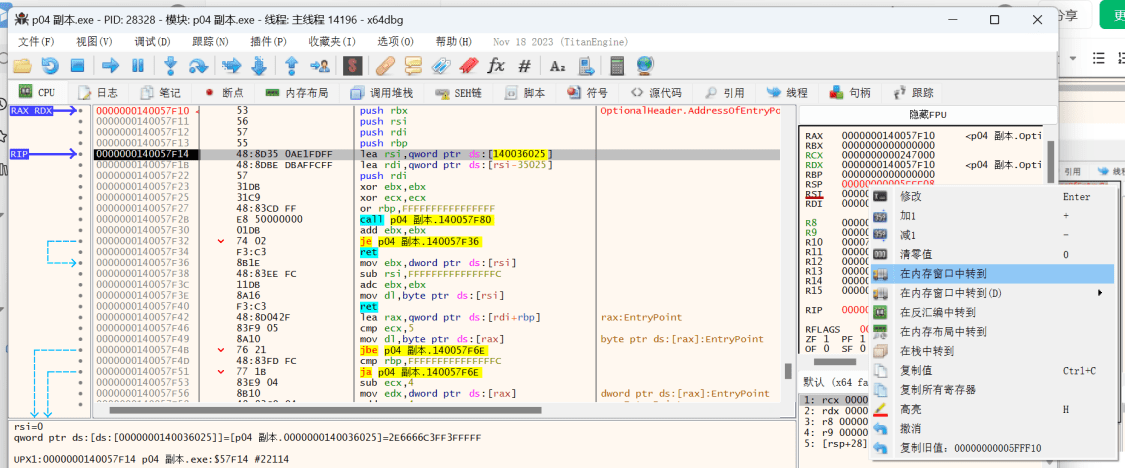
按F9到达该断点(这里要按两次,上面还有个别的什么断点)
观察到RSP的变化,在其上右键“在内存窗口中转到”
在右下角该地址右键,设置硬件断点
F9运行到断点处,看到下面的jmp大跳应该是入口,设置断点,F9跳过去
F7步入程序
往下翻可以看到提示字符串
“IAT Autosearch”→“Get Imports”→在“Imports”中删除掉带有红色叉叉的→“Dump”→“Fix Dump”选中之前的Dump文件→修复成功。
拖入IDA中(由于某种神秘力量?)没有main函数,只能通过字符串来找函数,可以看到大致的代码
蛮好理解的
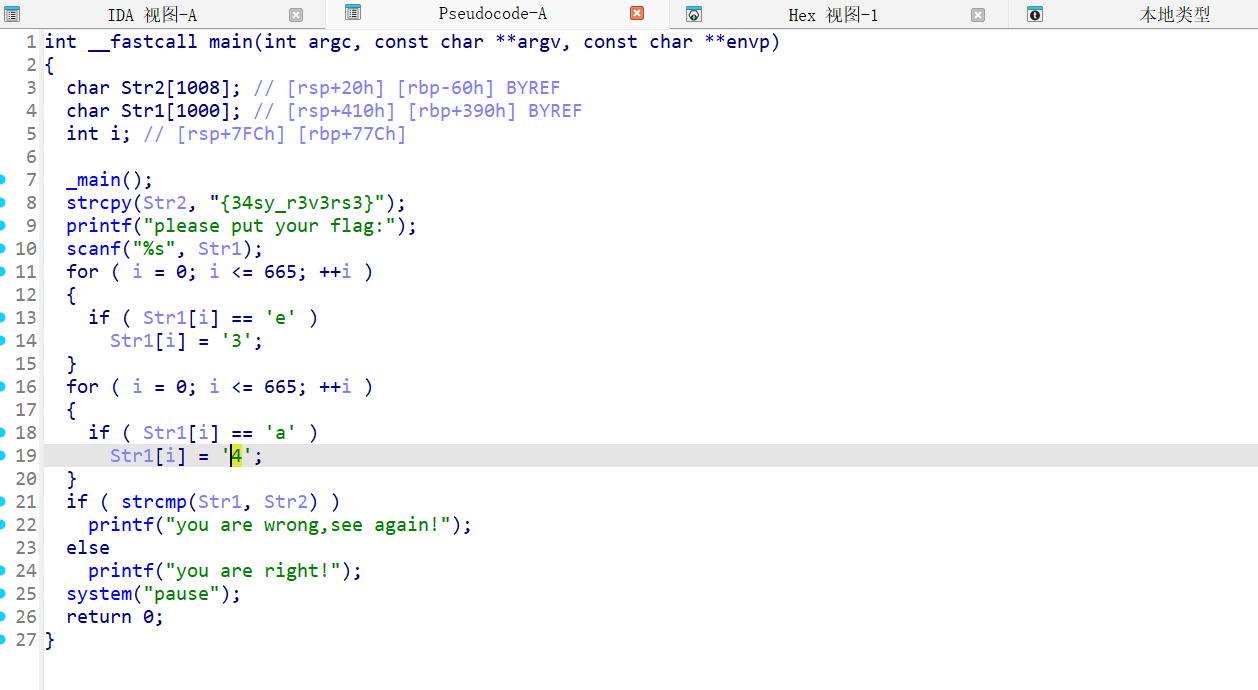
{34sy_r3v3rs3}
{easy_reverse}
逻辑与 && :and
||:or
ord()/chr()
exp1:注意加密判断是对密文判断的,所以反过来解密判断也是对处理后对象判断!!!
flag = '' Str = 'ylqq]aycqyp{' for i in Str: p1 = ord (i) + 2 p2 = ord (i) - 24 if (p1 <= 96 or p1 > 98 ) and (p1 <= 64 or p1 > 66 ): flag += chr (p1) else : flag += chr (p2) print (flag)
alpha='abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ1234567890{}-_' dic={} str ='ylqq]aycqyp{' flag='' for i in alpha: if (ord (i)<=96 or ord (i)>98 ) and (ord (i)<=64 or ord (i)>66 ): dic[chr (ord (i)-2 )]=i else : dic[chr (ord (i)+24 )]=i for i in str : flag+=dic[i] print (flag)
'''flag = 'xxxxxxxxxxxxxxxxxx' list = [47, 138, 127, 57, 117, 188, 51, 143, 17, 84, 42, 135, 76, 105, 28, 169, 25] result = '' for i in range(len(list)): key = (list[i]>>4)+((list[i] & 0xf)<<4) result += str(hex(ord(flag[i])^key))[2:].zfill(2) print(result)''' flag='' result='bcfba4d0038d48bd4b00f82796d393dfec' list = [47 , 138 , 127 , 57 , 117 , 188 , 51 , 143 , 17 , 84 , 42 , 135 , 76 , 105 , 28 , 169 , 25 ]for i in range (len (list )): key = (list [i]>>4 )+((list [i] & 0xf )<<4 ) flag += chr (int (result[2 *i:2 *i+2 ],16 )^key) print (flag)
a = "d`vxbQd" b = '' for i in range (len (a)): b += chr ((ord (a[i])^2 )-1 ) print (b)
import base64,urllib.parsekey = "HereIsFlagggg" flag = "xxxxxxxxxxxxxxxxxxx" s_box = list (range (256 )) j = 0 for i in range (256 ): j = (j + s_box[i] + ord (key[i % len (key)])) % 256 s_box[i], s_box[j] = s_box[j], s_box[i] res = [] i = j = 0 for s in flag: i = (i + 1 ) % 256 j = (j + s_box[i]) % 256 s_box[i], s_box[j] = s_box[j], s_box[i] t = (s_box[i] + s_box[j]) % 256 k = s_box[t] res.append(chr (ord (s) ^ k)) cipher = "" .join(res) crypt = (str (base64.b64encode(cipher.encode('utf-8' )), 'utf-8' )) enc = str (base64.b64decode(crypt),'utf-8' ) enc = urllib.parse.quote(enc) print (enc)
import base64,urllib.parsekey = "HereIsFlagggg" enc = urllib.parse.unquote('%C2%A6n%C2%87Y%1Ag%3F%C2%A01.%C2%9C%C3%B7%C3%8A%02%C3%80%C2%92W%C3%8C%C3%BA' ) s_box = list (range (256 )) j = 0 for i in range (256 ): j = (j + s_box[i] + ord (key[i % len (key)])) % 256 s_box[i], s_box[j] = s_box[j], s_box[i] res = [] i = j = 0 for s in enc: i = (i + 1 ) % 256 j = (j + s_box[i]) % 256 s_box[i], s_box[j] = s_box[j], s_box[i] t = (s_box[i] + s_box[j]) % 256 k = s_box[t] res.append(chr (ord (s) ^ k)) '''cipher = "".join(res) crypt = (str(base64.b64encode(cipher.encode('utf-8')), 'utf-8')) enc = str(base64.b64decode(crypt),'utf-8') enc = urllib.parse.quote(enc) print(enc)''' flag = '' for i in res: flag += i print (flag)
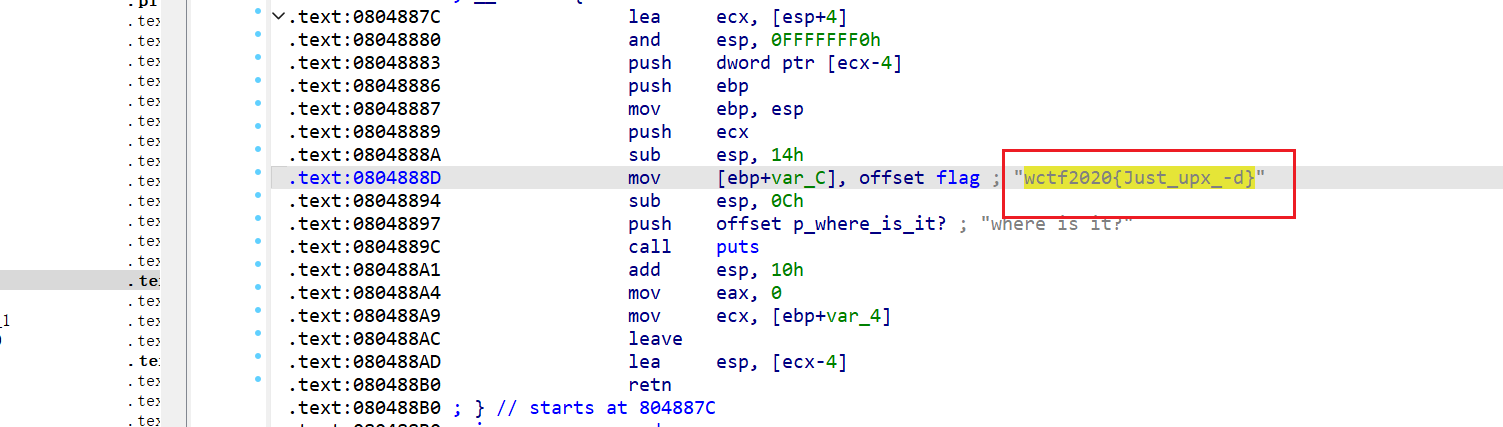
纯UPX脱壳题
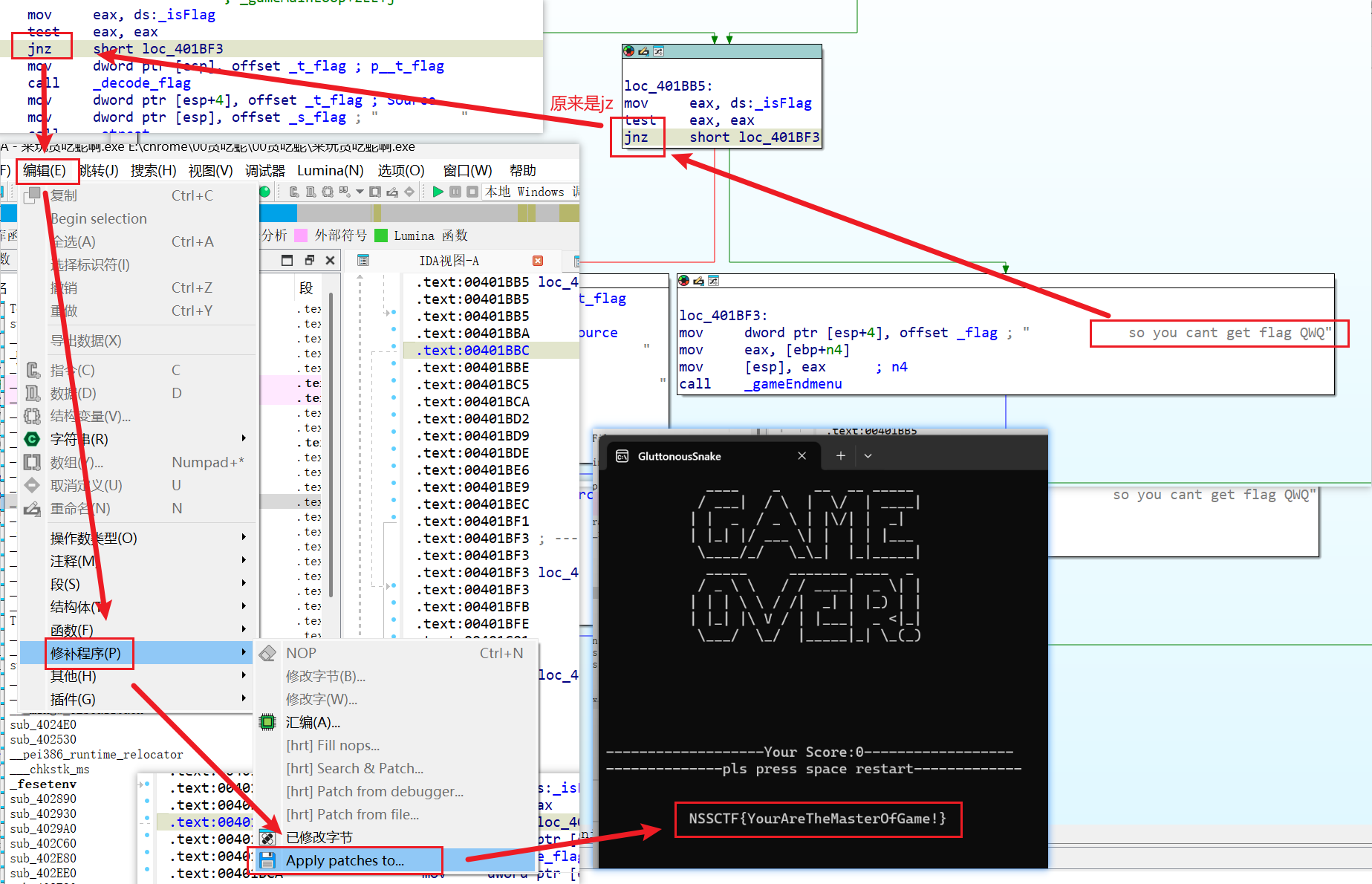
来玩贪吃蛇吧( 提示 没必要死磕这道题
jz命题jnz
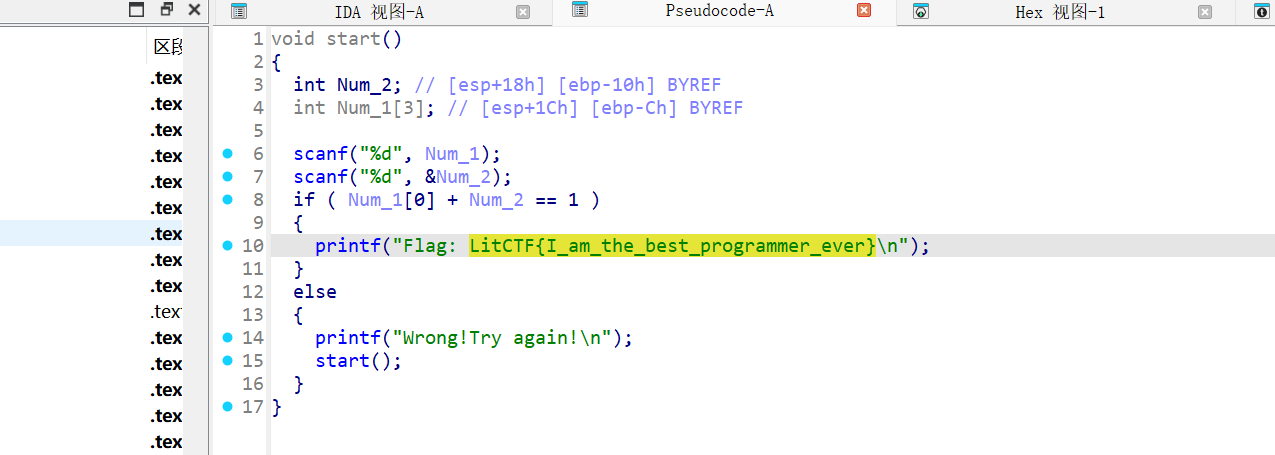
NSSCTF{YourAreTheMasterOfGame!}
在一场激烈的 CTF 竞赛中,你遭遇了一个棘手的加密谜题。现已知存在一个加密函数,它使用了特定的规则对一段关键信息进行了加密。你拿到了用于加密的 Python 代码以及加密后的字符串,请揭开这个神秘 flag 的真面目把。(加密后的字符串为iqcj{qafmgh89991})
def custom_encrypt (plaintext ): encrypted = "" key = [3 , 5 , 2 ] key_index = 0 for char in plaintext: if 'a' <= char <= 'z' : shift = key[key_index] new_char = chr ((ord (char) - ord ('a' ) + shift) % 26 + ord ('a' )) key_index = (key_index + 1 ) % len (key) elif 'A' <= char <= 'Z' : shift = key[key_index] new_char = chr ((ord (char) - ord ('A' ) + shift) % 26 + ord ('A' )) key_index = (key_index + 1 ) % len (key) elif '0' <= char <= '9' : num = int (char) new_num = (num + 7 ) % 10 new_char = str (new_num) else : new_char = char encrypted += new_char return encrypted encrypted_flag = custom_encrypt("这里藏着真正的flag,你得自己解出来" ) print ("加密后的flag是:" , encrypted_flag)
def custom_decrypt (ciphertext ): decrypted = "" key = [3 , 5 , 2 ] key_index = 0 for char in ciphertext: if 'a' <= char <= 'z' : shift = key[key_index] new_char = chr ((ord (char) - ord ('a' ) - shift) % 26 + ord ('a' )) key_index = (key_index + 1 ) % len (key) elif 'A' <= char <= 'Z' : shift = key[key_index] new_char = chr ((ord (char) - ord ('A' ) - shift) % 26 + ord ('A' )) key_index = (key_index + 1 ) % len (key) elif '0' <= char <= '9' : new_num = (int (char) - 7 ) % 10 new_char = str (new_num) else : new_char = char decrypted += new_char return decrypted print (custom_decrypt(input ("这里藏着真正的iodq,你得自己解出来" )))
这里藏着真正的iodq,你得自己解出来iqcj{qafmgh89991} flag{lychee12224}
# 打乱顺序的flag code_lines = [ "5: }", "1: f", "3: g", "2: l", "4: {", "6: l", "7: o", "8: g", "9: i", "10: c", "11: _", "12: k", "13: e", "14: y" ] # 打印代码行 for line in code_lines: print(line)
d = {} flag = '' for i in range (len (code_lines)): b,_,a = code_lines[i].partition(':' ) d[int (b)] = a flag = '' .join(d[i] for i in sorted (d)) print (flag)
partition/repatition/sorted/join用法
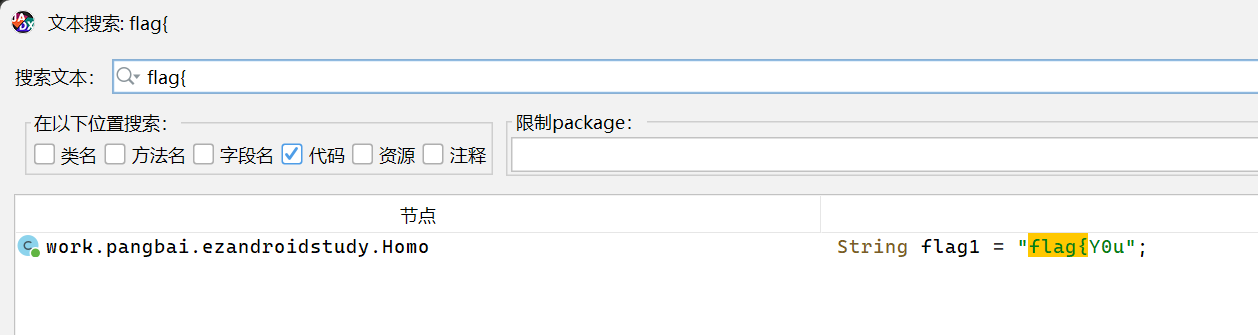
既然知道了flag被分成了5份,可以用搜索直接搜flag1
再搜索flag2并转到
根据提示在/res/raw下找到flag4.txt
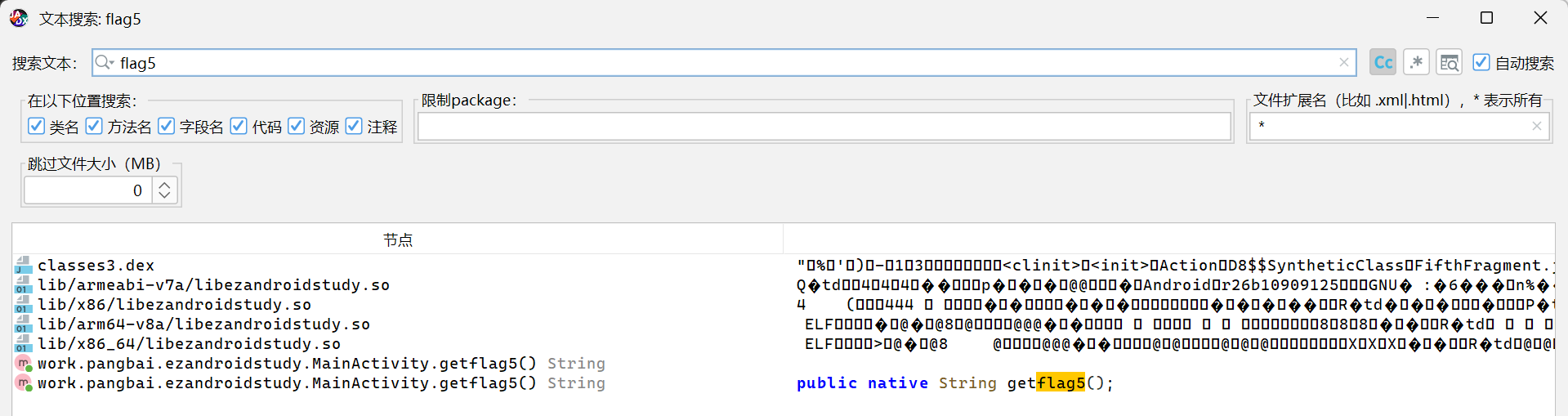
搜索flag5可以看到:有 native 标签,说明函数是 C 语言编写的,主体在 so 文件,需要逆向so文件。并且flag2处也提示了要逆向so文件
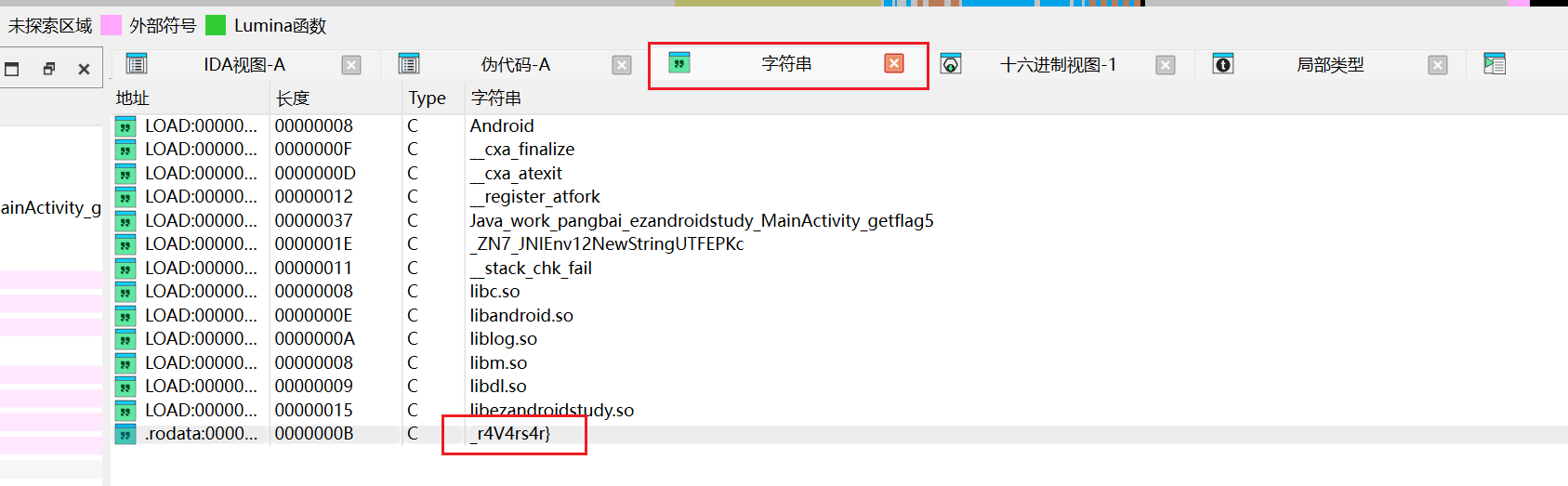
在lib里找到x86_64点开找到so文件右键导出,然后放到IDA64位里查看
最后合到一起flag{Y0u_@r4_900d_andr01d_r4V4rs4r}
走一下流程,找到MainActivity并跳转,主要看onClick里面的代码,可以看到Enc enc = new Enc(tx),加密逻辑在 Enc中
@Override public void onClick (View v) { if (v == this .binding.contentMain.frist.buttonFirst) { String tx = String.valueOf(this .binding.contentMain.frist.text.getText()); if (MainActivity$$ExternalSyntheticBackport0.m(tx)) { new MaterialAlertDialogBuilder (this ).setTitle("CheckResult" ).setMessage("不准拿空的骗我哟" ).show(); return ; } Enc enc = new Enc (tx); if (enc.check()) { new MaterialAlertDialogBuilder (this ).setTitle("CheckResult" ).setMessage("Congratulations ! ! !" ).show(); } else { new MaterialAlertDialogBuilder (this ).setTitle("CheckResult" ).setMessage("Wrong" ).show(); } } }
package work.pangbai.ezencrypt;import android.util.Base64;import javax.crypto.Cipher;import javax.crypto.SecretKey;import javax.crypto.spec.SecretKeySpec;public class Enc { String enc; public native boolean doEncCheck (String str) ; public Enc (String v) { try { this .enc = encrypt(v, stringToKey(MainActivity.title)); } catch (Exception e) { throw new RuntimeException (e); } } public boolean check () { return doEncCheck(this .enc); } public static SecretKey stringToKey (String keyStr) { byte [] decodedKey = keyStr.getBytes(); return new SecretKeySpec (decodedKey, 0 , decodedKey.length, "AES" ); } public static String encrypt (String data, SecretKey secretKey) throws Exception { Cipher cipher = Cipher.getInstance("AES/ECB/PKCS5Padding" ); cipher.init(1 , secretKey); byte [] encryptedBytes = cipher.doFinal(data.getBytes("UTF-8" )); return Base64.encodeToString(encryptedBytes, 2 ); } public static String decrypt (String encryptedData, SecretKey secretKey) throws Exception { Cipher cipher = Cipher.getInstance("AES/ECB/PKCS5Padding" ); cipher.init(2 , secretKey); byte [] decryptedBytes = cipher.doFinal(Base64.decode(encryptedData, 0 )); return new String (decryptedBytes, "UTF-8" ); } static { System.loadLibrary("ezencrypt" ); } }
这个类有一个native方法doEncCheck,静态块里加载了libezencrypt.so ,所以这个库应该包含doEncCheck的实现
分析:Enc(String v),里面调用了encrypt方法,参数是v和从MainActivity.title生成的密钥。然后加密后的结果保存在enc变量里。check方法调用doEncCheck,传入这个enc字符串,返回结果。
使用MainActivity.title作为密钥来源,转换为AES密钥。
采用AES/ECB/PKCS5Padding模式加密输入字符串,结果经Base64编码后存储。
check()调用本地方法doEncCheck()验证加密结果。
ai
要确定一个 native 方法的具体实现位置,通常有三种方法:
静态映射:JNI 命名规范在 Android 中,最常见的关联方式是遵循 JNI(Java Native Interface)的标准命名规则。当你调用 doEncCheck 时,系统会自动在已加载的 .so 库中寻找符合以下格式的函数名:Java_包名_类名_方法名
对于你的代码 work.pangbai.ezencrypt.Enc.doEncCheck:
包名:work.pangbai.ezencrypt (点号变成下划线 → \rightarrow →
类名:Enc
方法名:doEncCheck
最终结果:
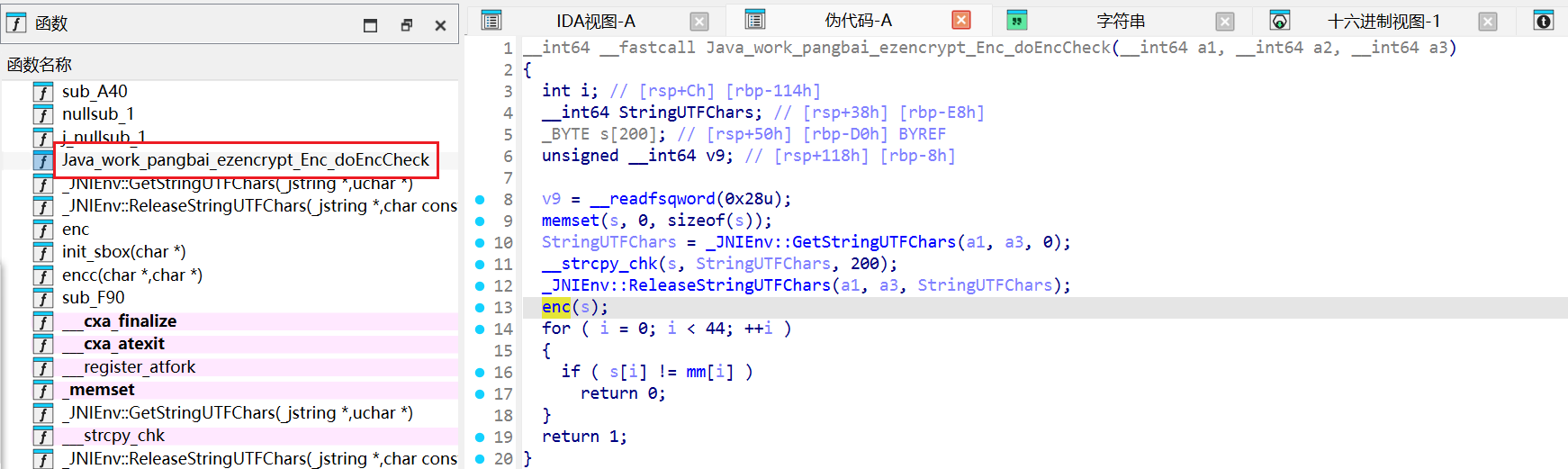
在 libezencrypt.so 中,一定会有一个 C/C++ 函数名叫:Java_work_pangbai_ezencrypt_Enc_doEncCheck
__int64 __fastcall Java_work_pangbai_ezencrypt_Enc_doEncCheck (__int64 a1, __int64 a2, __int64 a3) { int i; __int64 StringUTFChars; _BYTE s[200 ]; unsigned __int64 v9; v9 = __readfsqword(0x28u ); memset (s, 0 , sizeof (s)); StringUTFChars = _JNIEnv::GetStringUTFChars(a1, a3, 0 ); __strcpy_chk(s, StringUTFChars, 200 ); _JNIEnv::ReleaseStringUTFChars(a1, a3, StringUTFChars); enc(s); for ( i = 0 ; i < 44 ; ++i ) { if ( s[i] != mm[i] ) return 0 ; } return 1 ; }
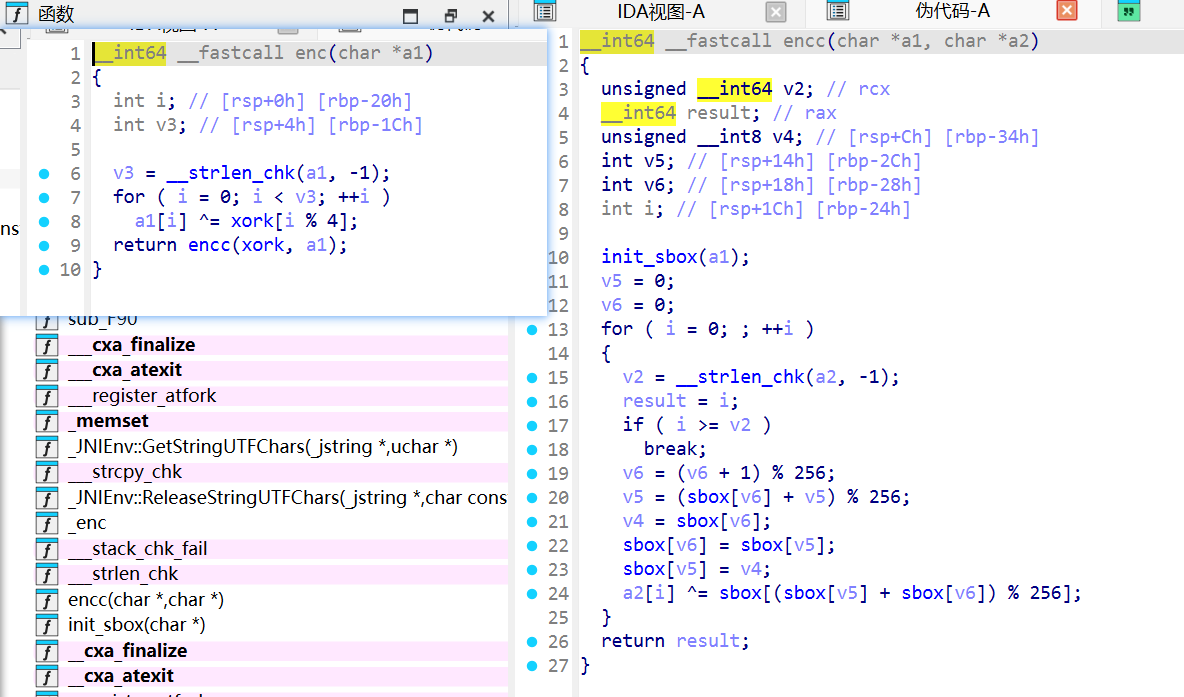
先异或加密,再典型的RC4加密,密钥是xork = meow
将加密后的数据进行RC4解密,得出来的数据与xork进行异或。
c现在不是很会,先当脚本记下来好了
#include "stdio.h" #include "string.h" char xork[] = "meow" ;#define size 256 unsigned char sbox[256 ] = { 0 }; void init_sbox (char * key) unsigned int i, j, k; int tmp; for (i = 0 ; i < size; i++) sbox[i] = i; j = k = 0 ; size_t key_len = strlen (key); for (i = 0 ; i < size; i++) { tmp = sbox[i]; j = (j + tmp + (unsigned char )key[k]) % size; sbox[i] = sbox[j]; sbox[j] = tmp; if (++k >= key_len) k = 0 ; } } void encc_decrypt (char * key, unsigned char * data, int len) int i, j, k, R, tmp; init_sbox (key); j = k = 0 ; for (i = 0 ; i < len; i++) { j = (j + 1 ) % size; k = (k + sbox[j]) % size; tmp = sbox[j]; sbox[j] = sbox[k]; sbox[k] = tmp; R = sbox[(sbox[j] + sbox[k]) % size]; data[i] ^= R; } } void decrypt_logic (unsigned char * in, int len) encc_decrypt (xork, in, len); for (int i = 0 ; i < len; ++i) { in[i] ^= xork[i % 4 ]; } } int main () unsigned char mm[] = { 0xc2 , 0x6c , 0x73 , 0xf4 , 0x3a , 0x45 , 0x0e , 0xba , 0x47 , 0x81 , 0x2a , 0x26 , 0xf6 , 0x79 , 0x60 , 0x78 , 0xb3 , 0x64 , 0x6d , 0xdc , 0xc9 , 0x04 , 0x32 , 0x3b , 0x9f , 0x32 , 0x95 , 0x60 , 0xee , 0x82 , 0x97 , 0xe7 , 0xca , 0x3d , 0xaa , 0x95 , 0x76 , 0xc5 , 0x9b , 0x1d , 0x89 , 0xdb , 0x98 , 0x5d }; int data_len = 44 ; decrypt_logic (mm, data_len); printf ("密文: " ); for (int i = 0 ; i < data_len; i++) { putchar (mm[i]); } puts ("" ); return 0 ; }
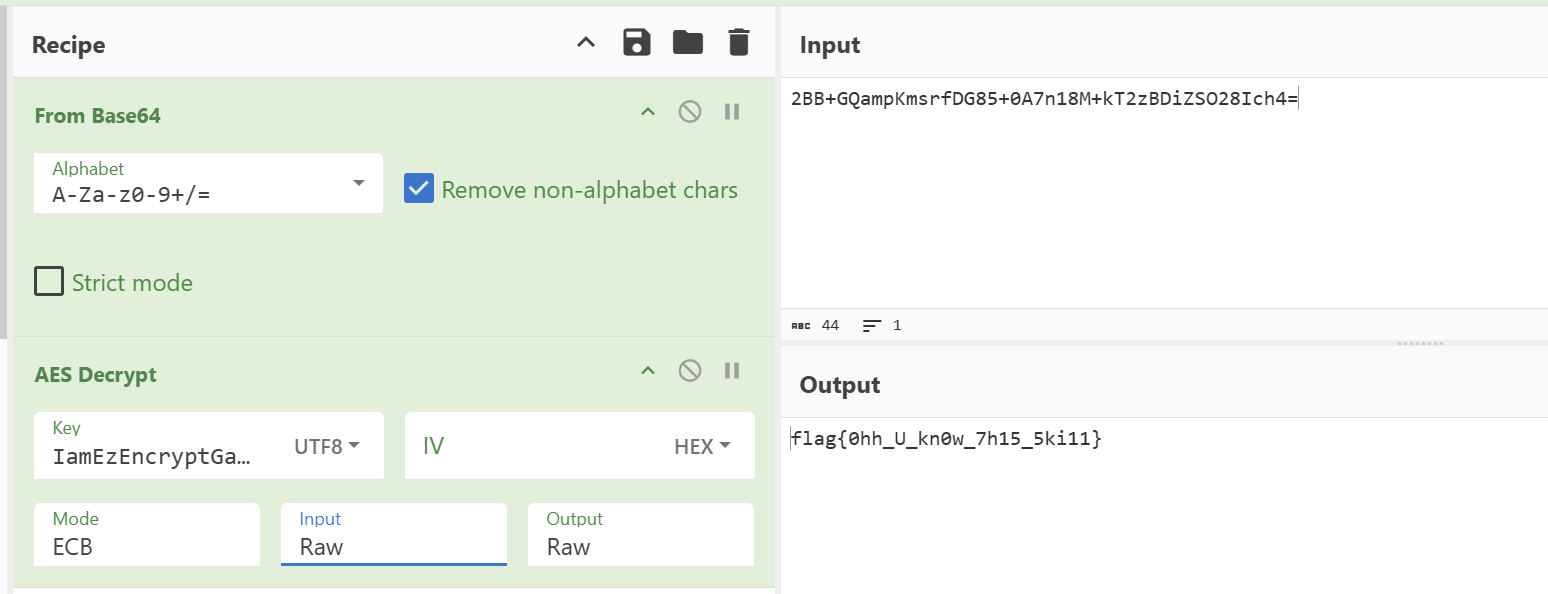
flag{0hh_U_kn0w_7h15_5ki11}
累死了还是java代码一点了解没有造成的后面得学
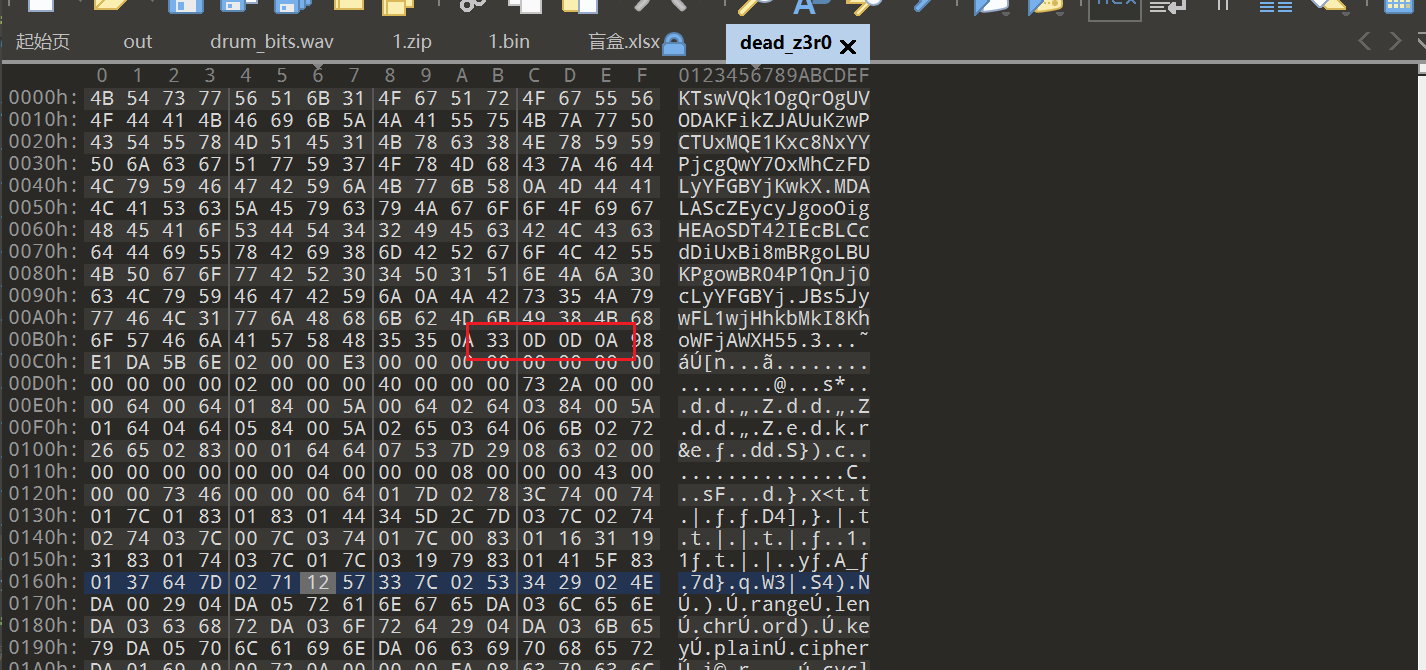
pyc-python3.6-33 0D 0D 0A
def encryt (key, plain ): cipher = "" for i in range (len (plain)): cipher += chr (ord (key[i % len (key)]) ^ ord (plain[i])) return cipher def getPlainText (): plain = "" with open ("plain.txt" ) as f: while True : line = f.readline() if line: plain += line else : break return plain def main (): key = "LordCasser" plain = getPlainText() cipher = encryt(key, plain) with open ("cipher.txt" , "w" ) as f: f.write(cipher.encode("base_64" )) if __name__ == "__main__" : main()
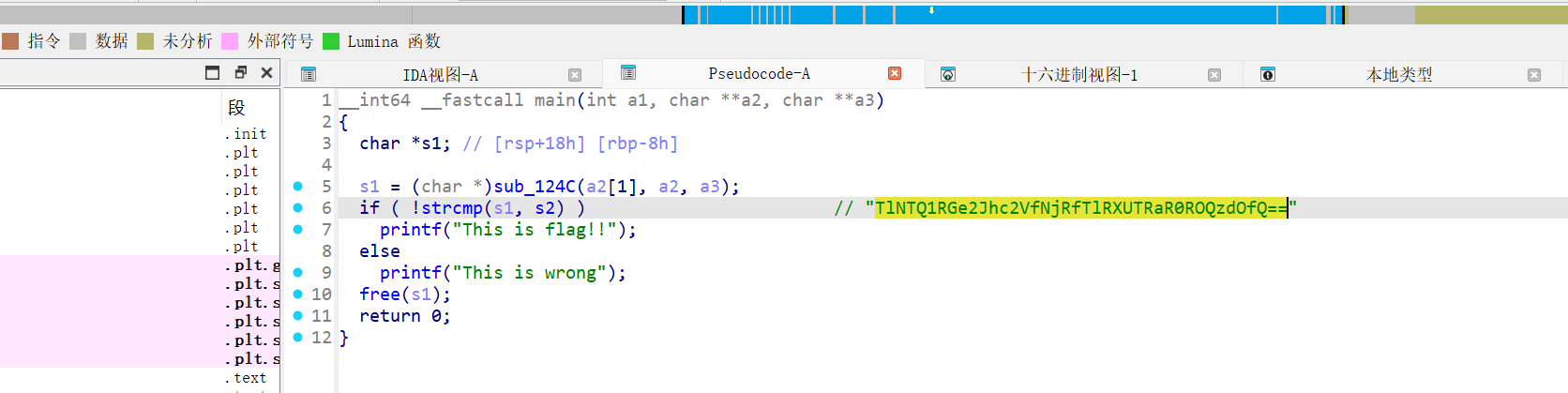
import base64import urllib.parsedef decrypt (cipher_text, key ): decoded = base64.b64decode(cipher_text) plain = "" for i in range (len (decoded)): plain += chr (decoded[i] ^ ord (key[i % len (key)])) return plain cipher_b64 = "KTswVQk1OgQrOgUVODAKFikZJAUuKzwPCTUxMQE1Kxc8NxYYPjcgQwY7OxMhCzFDLyYFGBYjKwkXMDALAScZEycyJgooOigHEAoSDT42IEcBLCcdDiUxBi8mBRgoLBUKPgowBR04P1QnJj0cLyYFGBYjJBs5JywFL1wjHhkbMkI8KhoWFjAWXH55" key = "LordCasser" print (urllib.parse.unquote(base64.b64decode(decrypt(cipher_b64, key))))
python -m stegosaurus dead_z3r0.pyc -x
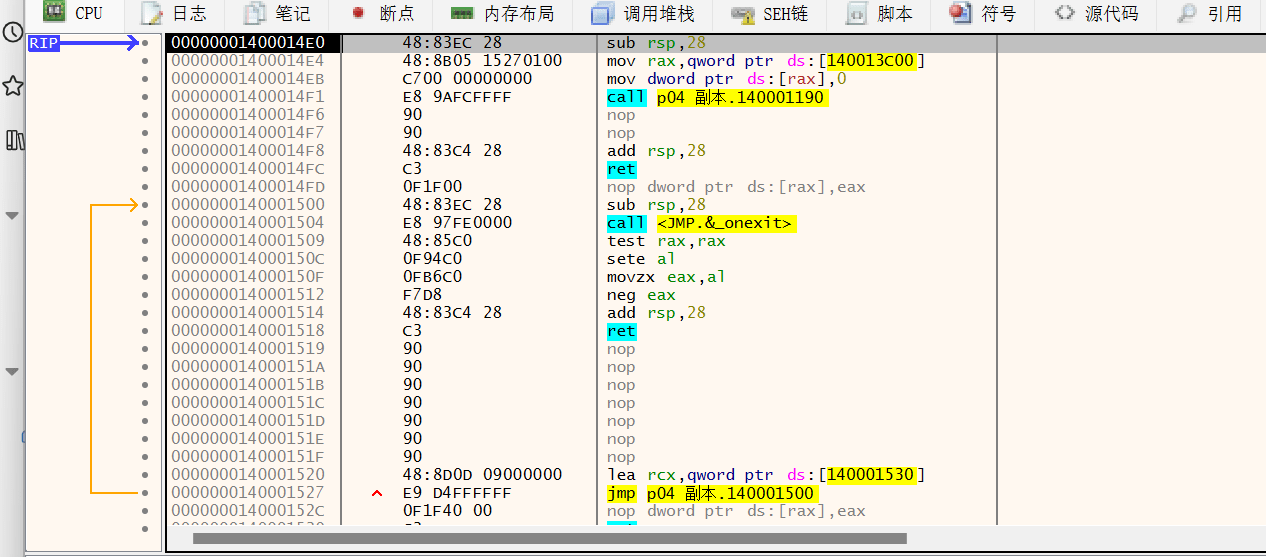
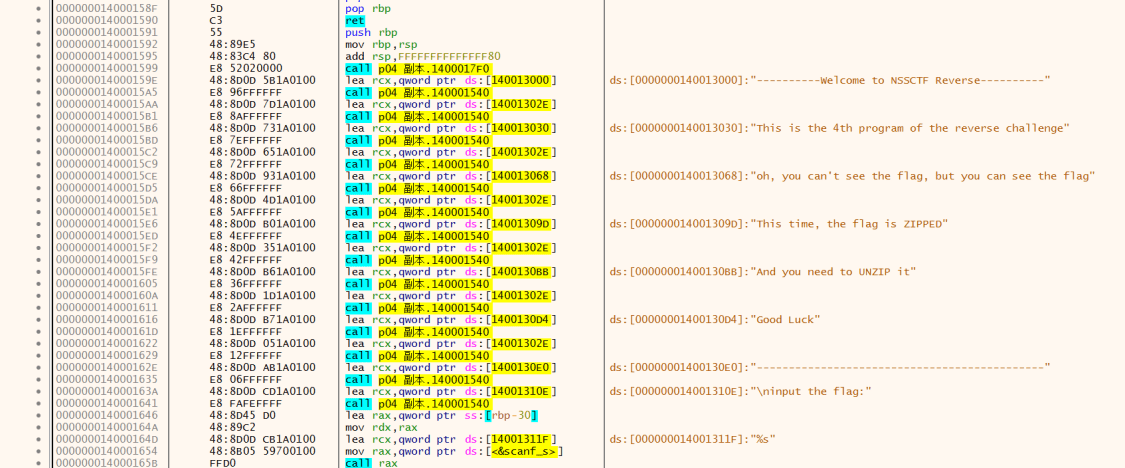
printf ("please input flag:" );scanf ("%99s" , input_0);if ( strlen (input_0) != 18 ){ printf ("Length Wrong!" ); exit (0 ); } v8 = strlen (input_0) - 8 ; v7 = v8 + 1 - 1LL ; v3 = alloca(16 * ((unsigned __int64)(v8 + 1 + 15LL ) >> 4 )); v6 = &v5; for ( i = 0 ; i < v8; ++i ) v6[i] = input_0[i + 7 ]; v6[v8] = 0 ; if ( (unsigned int )cul(v6) ) printf ("You get flag!\n" ); else printf ("Wrong flag!\n" ); return 0 ;
from z3 import *a1 = [Int(f'a{i} ' ) for i in range (10 )] constraints = [ 2 *a1[7 ] + 8 *a1[6 ] + 8 *a1[5 ] + 2 *a1[4 ] + 4 *a1[3 ] + 5 *a1[1 ] + 2 *a1[0 ] + 6 *a1[2 ] + a1[8 ] + 5 *a1[9 ] == 3976 , a1[5 ] + 9 *a1[3 ] + 7 *a1[2 ] + 5 *a1[1 ] + 3 *a1[0 ] + 7 *a1[4 ] + 4 *a1[6 ] + 6 *a1[7 ] + 8 *a1[8 ] + 5 *a1[9 ] == 5265 , 7 *a1[8 ] + 2 *a1[6 ] + 6 *a1[4 ] + 7 *a1[3 ] + 7 *a1[2 ] + 3 *a1[1 ] + 8 *a1[0 ] + 5 *a1[5 ] + 4 *a1[7 ] + 9 *a1[9 ] == 5284 , 7 *a1[6 ] + 5 *a1[5 ] + 6 *a1[4 ] + 3 *a1[3 ] + 9 *a1[0 ] + 6 *a1[1 ] + 4 *a1[2 ] + 9 *a1[7 ] + 8 *a1[8 ] + 7 *a1[9 ] == 5925 , 7 *a1[8 ] + 8 *a1[6 ] + 6 *a1[4 ] + a1[2 ] + 4 *a1[1 ] + 3 *a1[0 ] + 2 *a1[3 ] + 5 *a1[5 ] + 2 *a1[7 ] + 3 *a1[9 ] == 4048 , 3 *a1[8 ] + 9 *a1[7 ] + 7 *a1[6 ] + 4 *a1[4 ] + 4 *a1[3 ] + 5 *a1[0 ] + 8 *a1[1 ] + 6 *a1[2 ] + 4 *a1[5 ] + 7 *a1[9 ] == 5072 , 5 *a1[7 ] + 2 *a1[3 ] + 2 *(a1[0 ] + a1[1 ]) + 3 *a1[2 ] + a1[4 ] + 7 *a1[5 ] + 2 *a1[6 ] + 3 *a1[8 ] + 2 *a1[9 ] == 2813 , 3 *a1[8 ] + 5 *a1[7 ] + 7 *a1[6 ] + 3 *a1[5 ] + 7 *a1[4 ] + 7 *a1[1 ] + a1[0 ] + 7 *a1[2 ] + 8 *a1[3 ] + 6 *a1[9 ] == 5004 , 2 *a1[8 ] + 5 *a1[6 ] + 5 *a1[5 ] + 5 *a1[4 ] + 9 *a1[3 ] + 5 *a1[0 ] + 9 *a1[1 ] + a1[2 ] + 5 *a1[7 ] + a1[9 ] == 4490 , 6 *a1[8 ] + 7 *a1[7 ] + 5 *a1[6 ] + 6 *a1[3 ] + 4 *a1[1 ] + 6 *a1[0 ] + 8 *a1[2 ] + 6 *a1[4 ] + 8 *a1[5 ] + 7 *a1[9 ] == 5936 ] solver = Solver() solver.add(constraints) if solver.check() == sat: m = solver.model() flag_inner = '' .join(chr (m[ai].as_long()) for ai in a1) print ('flag middle 10 bytes:' , flag_inner) else : print ('no ans!' )
from z3 import *solver = Solver() flag = [BitVec('flag_%d' % i, 64 ) for i in range (6 )] all_chars = [] for i in range (6 ): char_values = [BitVec('char_%d_%d' % (i, j), 8 ) for j in range (7 )] all_chars.append(char_values) flag_part_56 = Concat(char_values) solver.add(flag[i] == ZeroExt(8 , flag_part_56)) for j in range (7 ): solver.add(char_values[j] >= 0x20 ) solver.add(char_values[j] <= 0x7e ) solver.add((593 *flag[5 ] + 997 *flag[0 ] + 811 *flag[1 ] + 258 *flag[2 ] + 829 *flag[3 ] + 532 *flag[4 ]) == 0x54eb02012bed42c08 ) solver.add((605 *flag[4 ] + 686 *flag[5 ] + 328 *flag[0 ] + 602 *flag[1 ] + 695 *flag[2 ] + 576 *flag[3 ]) == 0x4f039a9f601affc3a ) solver.add((373 *flag[3 ] + 512 *flag[4 ] + 449 *flag[5 ] + 756 *flag[0 ] + 448 *flag[1 ] + 580 *flag[2 ]) == 0x442b62c4ad653e7d9 ) solver.add((560 *flag[2 ] + 635 *flag[3 ] + 422 *flag[4 ] + 971 *flag[5 ] + 855 *flag[0 ] + 597 *flag[1 ]) == 0x588aabb6a4cb26838 ) solver.add((717 *flag[1 ] + 507 *flag[2 ] + 388 *flag[3 ] + 925 *flag[4 ] + 324 *flag[5 ] + 524 *flag[0 ]) == 0x48f8e42ac70c9af91 ) solver.add((312 *flag[0 ] + 368 *flag[1 ] + 884 *flag[2 ] + 518 *flag[3 ] + 495 *flag[4 ] + 414 *flag[5 ]) == 0x4656c19578a6b1170 ) if solver.check() == sat: m = solver.model() result = "" for i in range (6 ): for j in range (7 ): char_val = m.evaluate(all_chars[i][j]).as_long() result += chr (char_val) print ("Found Flag: " , result) else : print ("No solution found." )
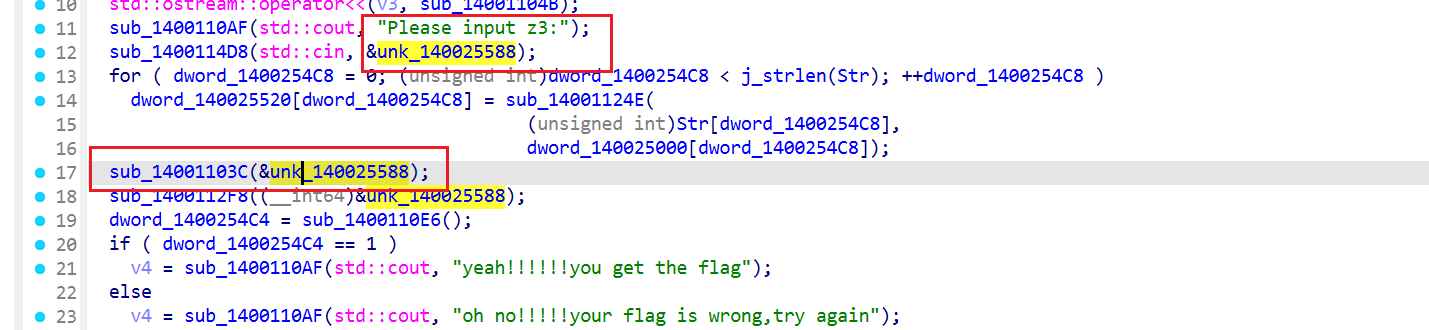
int __fastcall main_0 (int argc, const char **argv, const char **envp) { __int64 v3; __int64 v4; j___CheckForDebuggerJustMyCode(&unk_14002B069, argv, envp); sub_1400110AF(std ::cout , "Please input the flag:" ); sub_1400114D8(std ::cin , Str); v3 = sub_1400110AF(std ::cout , "Can you calculated out z3?" ); std ::ostream::operator<<(v3, sub_14001104B); sub_1400110AF(std ::cout , "Please input z3:" ); sub_1400114D8(std ::cin , &unk_140025588); for ( dword_1400254C8 = 0 ; (unsigned int )dword_1400254C8 < j_strlen(Str); ++dword_1400254C8 ) dword_140025520[dword_1400254C8] = sub_14001124E( (unsigned int )Str[dword_1400254C8], dword_140025000[dword_1400254C8]); sub_14001103C(&unk_140025588); sub_1400112F8(&unk_140025588); dword_1400254C4 = sub_1400110E6(); if ( dword_1400254C4 == 1 ) v4 = sub_1400110AF(std ::cout , "yeah!!!!!!you get the flag" ); else v4 = sub_1400110AF(std ::cout , "oh no!!!!!your flag is wrong,try again" ); std ::ostream::operator<<(v4, sub_14001104B); system("pause" ); return 0 ; }
就是0x1207
但是好像不止对比第一个???不懂
.data:0000000140025050 dword_140025050 dd 1207h, 4CA0h, 4F21h, 39h, 1A523h, 23Ah, 926h, 4CA7h .data:0000000140025050 ; DATA XREF: sub_140014770+6D↑o .data:0000000140025070 dd 6560h, 36h, 1A99Bh, 4CA8h, 1BBE0h, 3705h, 926h, 77D3h .data:0000000140025090 dd 9A98h, 657Bh, 18h, 0B11h, 8 dup(0)
dword_140025050=[0x1207, 0x4CA0, 0x4F21, 0x39, 0x1A523, 0x23A, 0x926, 0x4CA7,0x6560, 0x36, 0x1A99B, 0x4CA8, 0x1BBE0, 0x3705, 0x926, 0x77D3,0x9A98, 0x657B, 0x18, 0x0B11, 0,0,0,0,0,0,0,0]
ok现在按主函数顺序再顺一下
第一步:索要flag和z3
第二步:
跟进发现:flag和某数组作为a1和a2输入此函数
某数组:
.data:0000000140025000 dword_140025000 dd 3 dup(7), 9, 5, 6, 3 dup(7), 9, 2 dup(7), 5, 3 dup(7) .data:0000000140025000 ; DATA XREF: main_0+CF↑o .data:0000000140025040 dd 5, 7, 9, 7
shuzu=[7 ]*3 +[9 ,5 ,6 ]+[7 ]*3 +[9 ]+[7 ]*2 +[5 ]+[7 ]*3 +[5 ,7 ,9 ,7 ]
一个非常经典的**快速幂算法(Fast Exponentiation)**的变体,但它有一个非常特殊的“陷阱”,导致它的行为和标准的数学幂运算不一样。
底数 a1 :就是你的 Flag 字符(ASCII 码)。
指数 a2 :就是那个固定数组里的数字(比如 7, 5, 9…)。
__int64 __fastcall sub_140014CC0 (int a1, __int64 a2, __int64 a3) { unsigned int v4; int v6; v6 = a2; j___CheckForDebuggerJustMyCode(&unk_14002B069, a2, a3); v4 = 1 ; while ( v6 ) { if ( (v6 & 1 ) != 0 ) v4 *= a1; a1 = a1 * a1 % 1000 ; v6 >>= 2 ; } return v4; }
跟进sub_14001103C,把z3输入的和约束条件对比
__int64 __fastcall sub_140014E90 (char *a1, __int64 a2, __int64 a3) { __int64 v3; __int64 v4; j___CheckForDebuggerJustMyCode(&unk_14002B069, a2, a3); if ( 20 * a1[19 ] * 19 * a1[18 ] - 17 * a1[16 ] - 18 * a1[17 ] == 1967260144 ) { v4 = sub_1400110AF(std ::cout , "YOU are right" ); std ::ostream::operator<<(v4, sub_14001104B); }
这里上z3代码得到&unk_140025588即正确z3值
from z3 import *a1 = [BitVec(f'a{i} ' , 16 ) for i in range (20 )] solver = Solver() '''for i in range(20): solver.add(a1[i] >= 32, a1[i] <= 126)''' constraints = [ ] solver.add(constraints) if solver.check() == sat: m = solver.model() print (m) else : print ('false' )
这里z3要注意(其实也不知道具体原因反正要加限制,都试下好了以后
一种是位宽16
一种是加上字符约束,固定在可见字符范围内
仔细分析下这步异或
__int64 __fastcall sub_140014830 (__int64 a1, __int64 a2, __int64 a3) { j___CheckForDebuggerJustMyCode(&unk_14002B069, a2, a3); for ( dword_1400254C8 = 0 ; (unsigned int )dword_1400254C8 < j_strlen(Str); ++dword_1400254C8 ) dword_1400254D0[dword_1400254C8] = *(char *)(a1 + j_strlen(Str) - (unsigned int )dword_1400254C8 - 1 ) ^ dword_140025520[dword_1400254C8]; return 0 ; }
a1=[104 , 97 , 104 , 97 , 104 , 97 , 116 , 104 , 105 , 115 , 105 , 115 , 102 , 97 , 99 , 107 , 102 , 108 , 97 , 103 ] final=[0x1207 , 0x4CA0 , 0x4F21 , 0x39 , 0x1A523 , 0x23A , 0x926 , 0x4CA7 ,0x6560 , 0x36 , 0x1A99B , 0x4CA8 , 0x1BBE0 , 0x3705 , 0x926 , 0x77D3 ,0x9A98 , 0x657B , 0x18 , 0x0B11 ] yihuo=[] for i in range (20 ): yihuo.append(final[i]^a1[-1 -i]) def supermi (x, y ): v4 = 1 v6 = y while v6: if (v6 & 1 ) != 0 : v4 *= x x = x * x % 1000 v6 >>= 2 return v4 def inverse_supermi (v4, y ): for x in range (32 ,127 ): if supermi(x, y) == v4: return x shuzu=[7 ]*3 +[9 ,5 ,6 ]+[7 ]*3 +[9 ]+[7 ]*2 +[5 ]+[7 ]*3 +[5 ,7 ,9 ,7 ] flag = [0 ] * 20 for i in range (20 ): flag[i]=chr (inverse_supermi(yihuo[i],shuzu[i])) print ('' .join(flag))